A2. 偏微分方程式 多次元問題

空間次元が多次元の偏微分方程式
これまで空間次元が 1 である問題を扱ってきた. しかしながら,多くの現実の問題は空間次元が 2以上である. そこで,今回は空間次元が 2 以上である偏微分方程式を扱ってみよう.
対象例: 相分離問題モデル Cahn-Hilliard 方程式
たとえば比重の異なる二種類の物質を混ぜて放置すると,(軽いほうが上側に移動することから)全体はその二種類の物質ほぼそれぞれからなる二つの相に分離するという「相分離」現象が起きる. 他にも,混ぜた物質同士がそもそも分離しようとする性質をもっている場合も同様に相分離が起きる.
こうした相分離現象のモデル方程式の一つが Cahn-Hilliard 方程式(wikipedia)で,多次元問題の数値計算の対象としてはなかなか面白いものである. この方程式の仕組みはあまり難しくないので,授業時に白板で解説しよう.
なお,この方程式は時間発展方程式なのだが,普通の手法で数値計算をしようとすると時間方向の刻み幅である $\Delta t$ を大変小さく取らないと不安定になる(数値解が発散する)性質を強く持つことでも知られている. そのため,相分離現象のシミュレーションを,という意味で計算したいのであればなかなか大変なのだが,今回は計算する空間を小さめに取り,かつ,空間次元も 2次元に抑えることでその雰囲気を味わってみよう.
さてこの Cahn-Hilliard 方程式であるが,対象とする関数 $u(\boldsymbol{x},t)$ に対して次のような偏微分方程式となっている( $u$ の peak 値が $\pm 1$ として問題のない範囲でパラメータを簡潔にしている). \[ \frac{\partial u}{\partial t} = \Delta \left( -u + u^3 + q \, \Delta u \right) \] ただし,$q < 0$ は相の表面に働く表面張力の強さを表すパラメータで,その絶対値が大きいほど強いことになる. また,境界条件は本来は $\boldsymbol{n}$ を境界での外向き単位法線ベクトルとして以下のようになる.
$\left\{\begin{array}{rcl} \nabla u \cdot \boldsymbol{n} & = & 0, \cr \nabla (\Delta u) \cdot \boldsymbol{n} & = & 0. \end{array}\right.$
今回は本格的なシミュレーションが目的ではないので,まあ,この境界条件の代わりに,周期的境界条件を使うことにしよう(領域が矩形領域ならば,これらの境界条件の離散近似は難しくないが).
いつもの気軽な method of line + Runge-Kutta 法で
これまでのように,偏微分方程式の数値解法の手軽な手法の一つである,「method of line + Runge-Kutta法」で今回もチャレンジしてみよう. ただし,安直な分だけ,$\Delta t$ をちょいと小さく取る必要があるので,そこは覚悟しておこう.
まず,空間領域 $\Omega = [0, L] \times [0, L]$ に対し、その分割数を $N_x \times N_x$ とし、境界条件として周期的境界条件を離散化しよう.
そして $\Delta x = \Delta y = L / N_x$ として $u(\boldsymbol{x},t)$ の離散化に相当する従属変数を
\[ \boldsymbol{u}(t) = \{ u_{i,j}(t)\}_{i, j = 1}^N \]
としよう. なおここでは $u_{i,j}(t) \cong u(x = i\Delta x, y = j\Delta y, t)$ と想定している.
そして周期的境界条件を離散化した境界条件だが,外側にはみ出す点を仮想的に考えたとして
\[ \left\{ \begin{array}{rcl} \displaystyle u_{0, j} & := & u_{N, j} {\rm \,\,\, for \,\,\,} \forall j ,\cr\cr \displaystyle u_{N+1, j} & := & u_{1, j} {\,\,\, 同上 } , \cr\cr \displaystyle u_{i, 0} & := & u_{i, N} {\rm \,\,\, for \,\,\,} \forall i, \cr\cr \displaystyle u_{i, N+1} & := & u_{i, 1} {\,\,\, 同上 } \end{array} \right. \]
と解釈するのが良いだろう.
こうしておいて、空間微分(ラプラシアン) $\Delta$ を今回は差分近似で離散近似しよう.
$u$ に対するもとのラプラシアンが
\[
\Delta u =
\left( \frac{\partial}{\partial x} \right)^2 u
+
\left( \frac{\partial}{\partial y} \right)^2 u
\]
であることから,二階中心差分を用いて \[ (\Delta_d \, u)_{i,j} := \frac{ u_{i+1,j} - 2 u_{i,j} + u_{i-1,j} }{\Delta x^2} + \frac{ u_{i,j+1} - 2 u_{i,j} + u_{i,j+1} }{\Delta y^2} \] とするのが良いだろう.
そして,この離散近似を使って Cahn-Hilliard 方程式全体を離散近似して得られる常微分方程式は \[ \frac{d u_{i,j}(t) }{dt} = \Delta_d \left( - u + u^3 + q \, \Delta_d u \right)_{i,j} \,\,\,\, \mbox{ for } i = 1,2,\cdots, N, j = 1,2,\cdots, N \]
という $N \times N$ 元連立常微分方程式の形になる.
あとは少しずつプログラムを作っていくだけだ. まずは、問題のパラメータを設定してしまおう.
|
|
次に、ラプラシアンをどうにか構成しよう.
最初に思いつく方法は,係数行列 D というものを下記のように定義して,それを用いるものだ.
|
|
少し解説すると, 近似データそのものである行列 $u$ に対して、上で定義した行列 $D$ による $D * u$ をは行列 $u$ の行添字に関する二階差分になる. 同様に、$u * D$ は行列 $u$ の列添字に関する二階差分になる.
よって,これらの和である $D * u + u * D$ は $u$ に離散ラプラシアン $\Delta_d$ を適用した結果になる,という仕組みだ. これが最初の方法だ.
この方法は単純で間違いが入りにくく,そういう意味で「良い」と言える.
ただしこれはちょっと遅いのだ. 行列と行列との積は計算量が多く,たとえ片方が sparse とはいえその添字処理もあって,どうしても処理に少し時間がかかる.
そこで 2番めの方法だ. これは,行列データを貰って,各要素の計算をベタで行うという,大変にかっこ悪い方法なのだが,その分,ちょっと速い. 以下のような感じだ.
|
|
ああかっこ悪い.間違えそうだし. ただ,今回のデータの規模ですらこちらの方が最初の方法より 3倍程度は速いのだ. 最初の方法が速ければそっちの方を採用したいよなあ…
mod 計算を使って添字を循環させればいいじゃん,と思う人もいるだろう.
そうするときれいなプログラムが書けるのだが,普通に実装すると 100倍ぐらい遅くなるのだ.
それでいいならば,本質的に mod を用いて循環添字を実装している CircularArrays というパッケージがあるのでそれを使うといいだろう.プログラムは楽になる.か~な~り~遅いけどな.
さて話を戻して,これら2つの計算方法の結果がきちんと一致することと,計算時間が異な ることをここでしっかり確かめておこう.そうでないと心配だからね.
そこで計算対象として初期値を作ってしまおう. 今回は「最初は二種類の物質をなるべく均等にかき混ぜた状態」を初期状態にするシチュエーションを考えて,$u \cong 0$ な状態を乱数で作り出そう.
|
|
50×50 Array{Float64,2}:
0.000907744 -0.0039247 -0.00189216 … -2.25458e-5 -0.000703019
0.000359209 0.00475919 -0.00200338 0.00139821 -0.00344962
… (値は乱数のため,やるたびに異なる)
どんな初期値なのか、目で見ておこう.
|
|

さて、これで準備は整ったので、早速ラプラシアン Δ の2つの計算方法の値の比較と,計算時間の比較を行おう.
まずは計算結果の比較だ.
|
|
1.4210854715202004e-14 (u0 が乱数なので左の値そのものは 人によって異なる)
計算結果はほぼ一致している. どちらの計算方法を使っても計算結果は実質的に変わらないと見て大丈夫だろう.
次に計算時間を見よう.
|
|
BenchmarkTools.Trial:
memory estimate: 58.92 KiB
allocs estimate: 6
--------------
minimum time: 22.900 μs (0.00% GC)
median time: 41.701 μs (0.00% GC)
mean time: 43.141 μs (12.07% GC)
maximum time: 4.851 ms (99.21% GC)
--------------
samples: 10000
evals/sample: 1
|
|
BenchmarkTools.Trial:
memory estimate: 39.30 KiB
allocs estimate: 5
--------------
minimum time: 3.738 μs (0.00% GC)
median time: 15.906 μs (0.00% GC)
mean time: 15.633 μs (17.79% GC)
maximum time: 764.575 μs (98.01% GC)
--------------
samples: 10000
evals/sample: 8
先に書いたように,明らかに後者の方が 3倍近く速い. 今回は後者を使うことにしよう.
ということで,微分方程式の右辺の近似計算式は次のようになるだろう.
|
|
f (generic function with 1 method)
さて、これで連立常微分方程式の右辺(の近似)が計算できたことになるので、いつものように Runge-Kutta 法を定義する.
|
|
RK (generic function with 1 method)
これで計算手順の準備は整った. 早速計算しよう.
|
|
Progress: 100%|████████████████████████████| Time: 0:02:10
試しに結果の数字をちょろっと見てみる.
|
|
50×50×201 Array{Float64,3}:
[:, :, 1] =
0.000907744 -0.0039247 -0.00189216 … -2.25458e-5 -0.000703019
0.000359209 0.00475919 -0.00200338 0.00139821 -0.00344962
> …
[:, :, 2] =
-0.000811457 -0.00144386 -0.00211925 … 0.00024822 -0.000244266
-0.000153012 -0.000554191 -0.00112487 0.000227066 9.30991e-5
> … (初期値が乱数のため,結果もやるたびに異なる)
あまり変なことにはなっていなさそうなので、最終結果をまずはプロットしてみよう. こういう場合は heatmap 関数を使うのが良さそうだ.
|
|

ふむ,確かに分離しているようだな(初期値が乱数なので,貴殿の結果がこの図と異なってもそれは「当然」だ).
ちなみに,最終結果の $u$ の値のスケールで初期値をあらためてプロットして,「初期値がたしかに均等っぽい」ことも確認しておこう. それには,計算値全体の最大値と最小値をまず次のように調べて,
|
|
(-1.028435658672145, 1.024132326800102)
次のように clim オプションで値の上下を固定して heatmap を使えば良い.
|
|

確かに,時間発展結果に比べると初期値は「ほぼ均等にゼロに近い」ことが見て取れる.よし.
ということで,ふむ、なんとなくうまく計算できているようだ.
すべてのデータを一気に画像化する
あとは heatmapコマンドを好きなだけ繰り返せば途中結果も見られる. しかしまあそれはそれで様子がよくわからないので全データを画像 & 動画にしてしまうことを考えよう.
まず、たくさんの画像ファイルを入れておくディレクトリをコマンドで作らせよう.これは一回だけやれば良い.
|
|
Process(`mkdir figures`, ProcessExited(0))
注: 上の "mkdir" の実行後、juliabox のファイルビューアー部分を見てみよう.figures という新しいディレクトリができているはずだ.
次に、データを画像ファイルとして保存するコマンドを作ろう. 基本的には、plot 系コマンドの直後に savefig コマンドを使うだけで、そのグラフを画像ファイルとして保存できる. 今回は動画ファイルの「元」にしたいので、そうだなあ、"4桁の数字.png" というファイル名になるようにしておく.
|
|
注: "@sprintf" というマクロは、昔から C 系統のプログラム言語で使われている sprintf 命令を模したもので、文字列を「決まったフォーマットで出力する」ものだ.使い方は "sprntf" などで検索してみよう.
では、全データからたくさんの画像ファイルを作ろう.これは 10秒程度で終わるだろう.
|
|
Progress: 100%|█████████████████████████████████| Time: 0:00:07
そして jupyter のファイルビューアー部分で.figures ディレクトリの下を見てみよう.
今回は 201個の画像ファイルが生成されているはずだ.
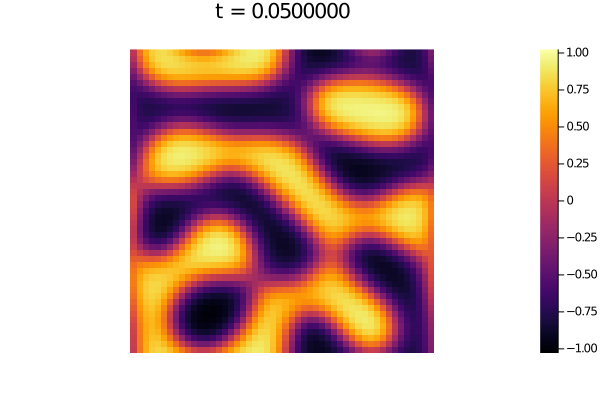
たとえばその 0010.png を見てみると次のような感じになっているだろう.
ffmpeg などの動画作成ツールで動画にしてみよう
さて,数百個もの画像ファイルが有るならばこれをつなげて動画にするのが可視化としては「いつもの手」というやつだ. そして世の中には有名なフリーのツールに FFmpeg というものがあり、これを使うと連番の画像ファイルを無理なくきれいに動画にできる. この手法は便利なので覚えておこう.
自分の PC に FFmpeg がインストールされていない、という人は、これを機にインストールしておこう. Download FFmpeg から windows用,Mac用,Linux用のインストール用ファイルがダウンロードできる.
さて、今回は FFmpeg を julia から直接呼び出して使ってみよう. 以下のようにすればよいだろう.動画への変換はほぼ一瞬で終わるはずだ.
(詳しい人向け: terminal からコマンドを打っても良い)
|
|
ffmpeg version git-2020-06-10-9dfb19b Copyright (c) 2000-2020 the FFmpeg developers
built with gcc 9.3.1 (GCC) 20200523
configuration: --enable-gpl --enable-version3
…
これで ch-eq.mp4 という動画ファイルができたはずだ. jupyter のファイル操作画面で、その動画ファイルを view したり、ダウンロードして(jupyter はファイルを1つずつなら指定してから download できるぞ)動かしてみるなどして、確認しよう.
参考のために、そのファイルをここに直接おいておく.
- 動画ファイル (mp4 形式)
あと,もう少し大きな空間領域で計算した結果例も載せておこう(Δx, Δt 等は同じまま).
もちろん計算時間はさらに必要で,要した時間はそれぞれ約 30分,15時間というところだ.
- 動画ファイル, 空間領域サイズを 3x3 にしたもの (mp4 形式)
- 動画ファイル, 空間領域サイズを 5x5 にし, t=10 まで計算したもの (mp4 形式)
動画を見ることで,初期のほぼ均一な状況から一瞬にして相分離が発生し,その後,かなりゆっくりと相同士が融合して全体の構造が大きくなっていくことが見て取れるだろう. こうした「挙動の性質」は動画にしないと見えてこないことが多いので,時間発展問題の数値計算結果はなるべく動画にし,考察を加えるようにしておこう.
レポート(オプション)
下記要領でレポートを出してみよう.
- e-mail にて,
- 題名を 2020-numerical-analysis-report-a2 として,
- 教官宛(アドレスは web の "TOP" を見よう)に,
- 自分の学籍番号と名前を必ず書き込んで,
- 内容はテキストでも良いし,pdf などの電子ファイルを添付しても良いので,
下記の内容を実行して,結果や解析,感想等をレポートとして提出しよう.
- 上の例では初期値を乱数で作ったが,そうでない初期値を自分で作ってそれに対して計算してみよう.
ただし,$-1 < u(\boldsymbol{x}, 0) < 1$ を満たすようにしておくことを忘れないように.
- 今回は空間方向だけ差分化して、あとは常微分方程式として扱うという method of line の手法を使った. 時間方向も差分化したり、有限要素法を使ったり(かなり面倒だが)他の方法で計算してみよう. さらにできればだが,「高速な計算」も試みると良いだろう.