10. SQLite3 データベース
 Photo by
Gabriel Ghnassia on Unsplash
Photo by
Gabriel Ghnassia on Unsplash
この回で身につける考え方

この回では,軽量なデータベースソフトウェアである SQLite3 をコマンドラインから使い,データベースの基本を体験する.
この回で大事なのは,SQL の全命令を覚えることではない. むしろ,次の流れを理解することが目的である.
- データを 表 として整理する.
- 表にデータを 追加 する.
- 条件を指定して,必要なデータを 取り出す.
- 複数の表を 共通の id でつなぐ.
- 取り出したデータを 集計 する.
- 慣れてきたら,コマンド列をファイル化して 自動化 する.
表で整理し,質問を SQL に直して,答えを取り出す
この感覚をつかめれば,SQLite 以外のデータベースにも進みやすくなる.
データベースソフトウェアとは

大雑把に言えば,データベースとは 一定のルールに従って保存されたデータの集まり である. また,そのデータを保存したり,取り出したり,更新したりするためのソフトウェアを,データベースソフトウェア,あるいは単にデータベースと呼ぶことも多い.
小さなデータならば,テキストファイルや表計算ソフトでも十分である. しかし,データが増えたり,複数の種類のデータを関係づけたりする必要が出てくると,次のような問題が起こりやすくなる.
- 同じ情報を何度も書いてしまう.
- ある場所を修正したのに,別の場所を修正し忘れる.
- 表記ゆれにより,同じ人・同じ商品が別物として扱われる.
- 必要な情報を探すための手作業が増える.
データベースを使うと,こうした問題をかなり減らすことができる. 今回の実習では,その最初の一歩として,商品・顧客・売上を別々の表に分けて管理する.
どの程度のデータならデータベースを使うべきか
データが1画面に収まる程度で,しかも一度きりしか使わないなら,テキストファイルや表計算ソフトの方が簡単なことも多い. 一方で,データを繰り返し更新する,条件検索を何度も行う,複数種類の情報を関係づける,という場合はデータベースを検討する価値がある.
数値計算の単純な観測データのように,数値が大量に並んでいるだけの場合は,専用の形式や専用プログラムを使った方がよいことも多い. データベースは万能ではなく,「構造をもつデータを,壊さず,探しやすく,更新しやすく管理する」ための道具と考えるとよい.
SQLite とは
本授業で用いる SQLite は,軽量な RDBMS の一つである. RDBMS は relational database management system,つまりリレーショナルデータベース管理システムの略である. リレーショナルデータベースでは,データを複数の表として管理し,表同士の関係を使って必要な情報を取り出す.
SQLite の本家ページでは,SQLite は「世界で一番広く使われている SQL エンジン」であると説明されている. 興味があれば SQLite の説明ページ を見てみよう.
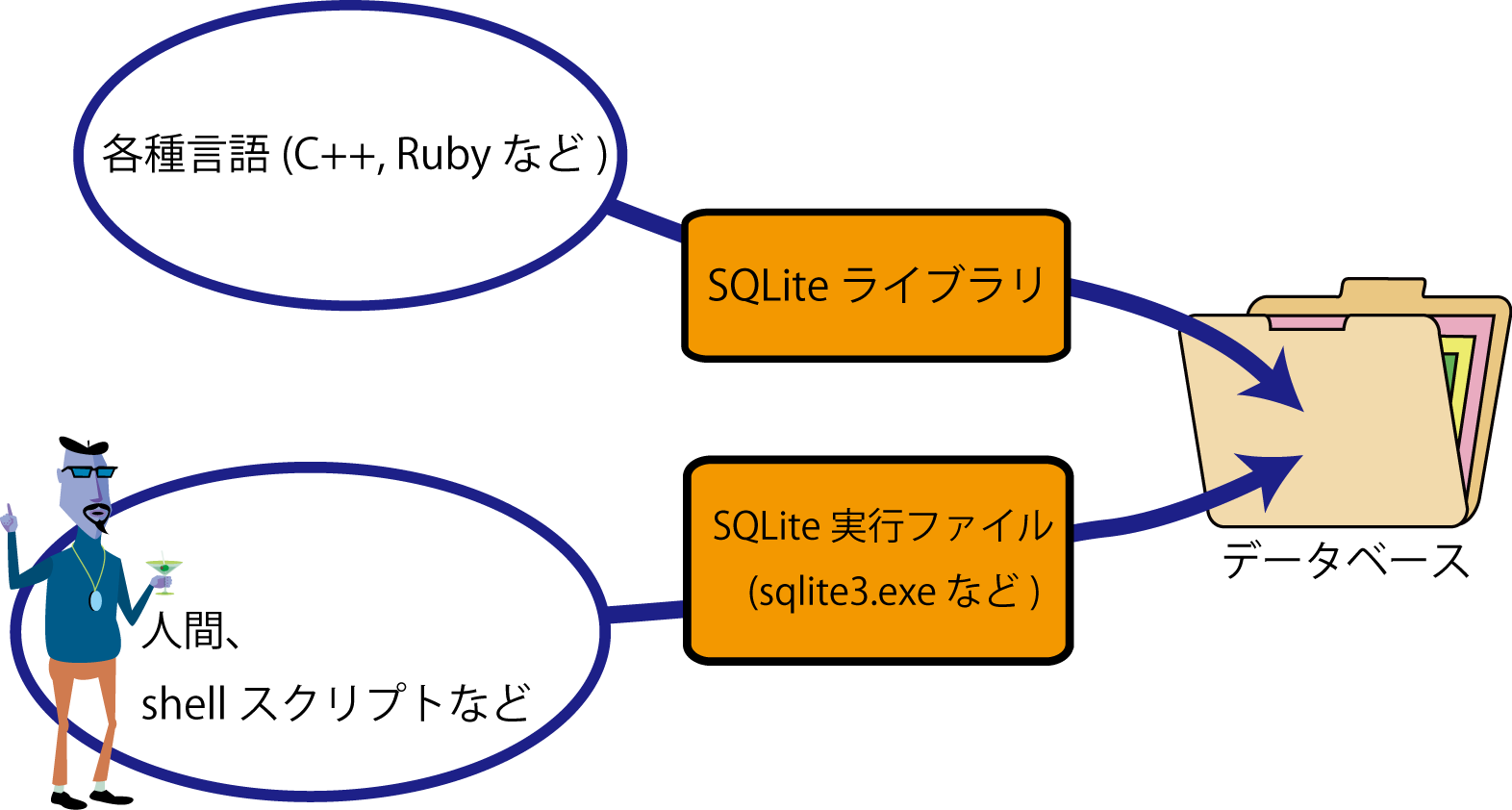
Tips 1. SQLite では,(サーバにではなく) データベースファイルに直接アクセスする
多くの本格的なデータベースシステムでは,データベースサーバを動かし,そこへ接続してデータを操作する. 一方,SQLite では基本的に 1つのデータベースが1つのファイル になっていて、そのファイルに直接アクセスするという単純な仕組みだ.
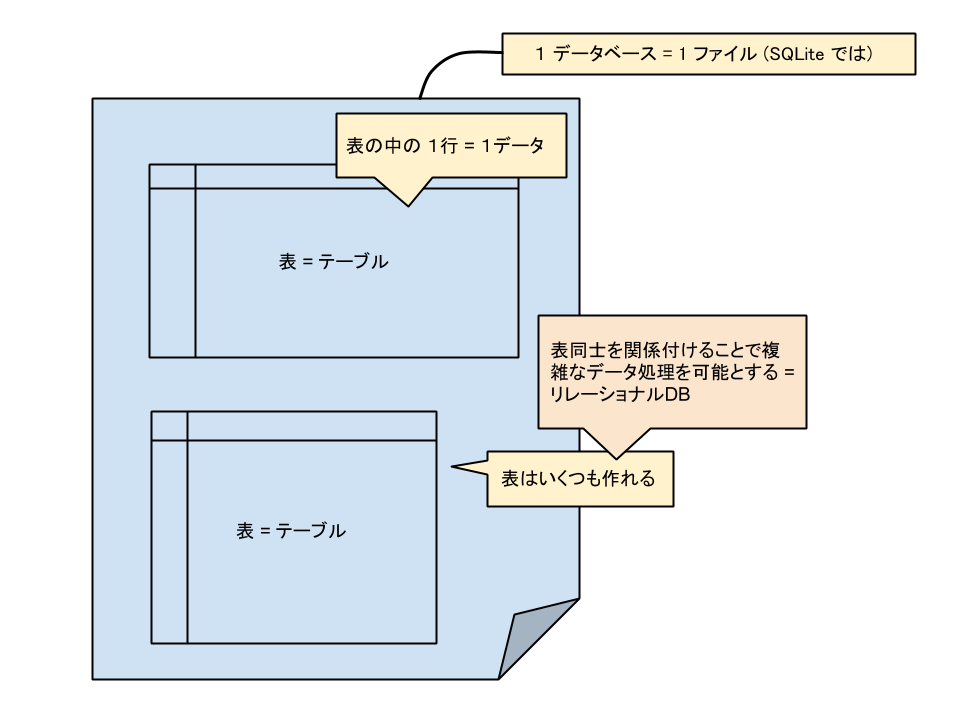
Tips 2. SQLite では,ファイルの中に複数の表が作られる
また、その1つのデータベースファイルの中に、SQLite では多くの「表(テーブル)」を作ることが出来る. これらの表(テーブル)をうまく繋いで活用するのが RDBMS の本質だ.
SQLite で用いる2種類の命令
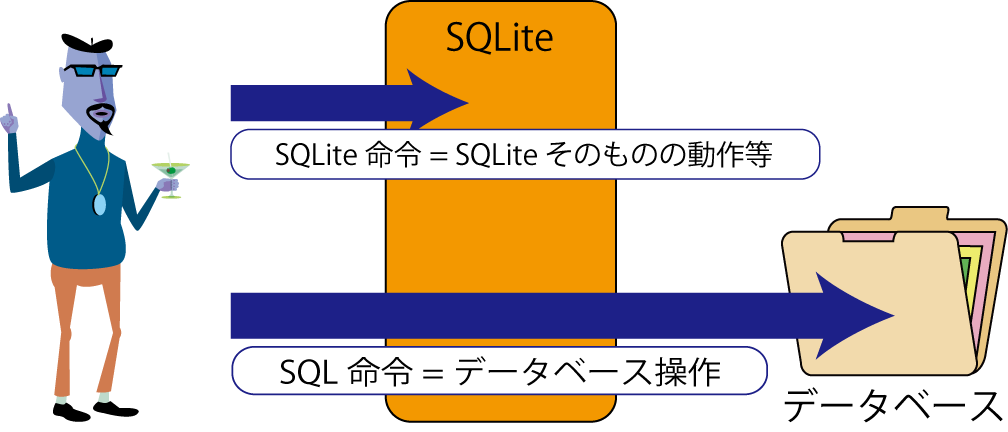

SQLite を対話的に使うときは,2種類の命令を区別する必要がある.
| 種類 | 例 | 何をするか |
|---|---|---|
| SQLite コマンド | .show, .tables, .mode table, .exit |
sqlite3 コマンドそのものへの指示.先頭が . で始まる. |
| SQL コマンド | CREATE TABLE, INSERT INTO, SELECT, UPDATE, DELETE |
データベースの中身への指示.普通は最後に ; を付ける. |
特に初学者が混乱しやすいのは,
.tablesのような SQLite コマンドは.で始まるSELECT * FROM fruits;のような SQL コマンドは最後の;で実行される
という違いである.
慣習として SQL 命令は大文字で書かれることが多いが,SQLite では小文字でも動く.
この資料でも,説明では SELECT のように大文字を使うが,実習で対話的に入力するときは select と小文字で打ってもよい.
実習の準備
今回の実習では,作業用ディレクトリを作り,その中で作業する. 端末,PowerShell,WSL のいずれを使っていても,基本的な考え方は同じである.
まず,作業用ディレクトリを作って,そこへ移動しよう.
1cd ~
2mkdir sqlite10
3cd sqlite10
以降,このディレクトリの中で作業しているものとする. 途中で自分がどこにいるかわからなくなったら,Unix/Linux や WSL では
1pwd
2ls
Windows の PowerShell では
1pwd
2ls
などで確認すればよい.
全体像: 今日の実習で作って操作するのは…
さきに、今日の実習で操作する対象を紹介しておく.

この授業では,果物屋の売上を管理する小さなデータベースを作る. 具体的には,1つのデータベースファイル db1.db の中に次の3つの表を作る.
| 表名 | 役割 |
|---|---|
fruits |
商品リスト.商品名と単価を入れる. |
customers |
顧客リスト.顧客名を入れる. |
sales |
売上記録.誰が,どの商品を,何個買ったかを入れる. |
最初は fruits 表だけを使って,表の作成・追加・表示・更新・削除を練習する.
その後,customers 表と sales 表を追加し,複数の表をつないで,例えば
tomは何を買ったか- 各顧客に合計でいくら請求すればよいか
- 各商品は合計でいくら売れたか
といった情報を取り出す.
SQLite3 の起動,設定,終了
今回の実習では,sqlite3 というコマンドを使って,db1.db というデータベースファイルを直接操作する.
その想定のもと、以下の内容を読もう.

SQLite3 を起動する
次のようにすると,db1.db というデータベースファイルに接続する.
まだそのファイルが存在しなければ,新しく作られる.
1sqlite3 db1.db
起動すると,プロンプトが
1sqlite>
に変わる. これ以降は,シェルではなく SQLite の中にいる,と意識しよう.
実習
上のコマンドで SQLite3 を起動しよう.
起動したら,そのまま次の設定へ進もう.
出力を見やすくする
SQLite を対話的に使うときは,最初に次の2つを設定しておくと見やすい.
1.headers on
2.mode table
環境によっては .mode table だけで表の見出しも出ることがあるが,ここでは明示的に .headers on も実行しておく.
現在の設定は次の命令で確認できる.
1.show
また,今のデータベースにどんな表があるかは,次の命令で確認できる.
1.tables
最初はまだ表を作っていないので,何も表示されないかもしれない. これは正常である.
実習
sqlite> プロンプトで,次の3つを順に実行しよう.
1.headers on
2.mode table
3.show
SQLite3 を終了する
SQLite を終了するには,次のいずれかを実行する.
1.exit
または
1.quit
終了すると,シェルや PowerShell のプロンプトに戻る.
1つの表を操作する

ここからは,まず fruits という1つの表だけを操作する.
この表には,商品名と単価を入れる.
データベースの基本操作は,しばしば CRUD と呼ばれる.
| 操作 | SQL命令 | 意味 |
|---|---|---|
| Create | CREATE TABLE, INSERT INTO |
表を作る,データを追加する. |
| Read | SELECT |
データを見る,検索する. |
| Update | UPDATE |
データを修正する. |
| Delete | DELETE |
データを削除する. |
表を作る:CREATE TABLE
表を作るには CREATE TABLE を使う.
今回の fruits 表は,次の3つの列をもつことにする.
| 列名 | 意味 |
|---|---|
id |
商品を一意に区別する番号.自動で連番にする. |
name |
商品名. |
price |
単価. |
sqlite> プロンプトに次のように入力しよう.
1CREATE TABLE fruits
2(id INTEGER PRIMARY KEY AUTOINCREMENT, name, price);
最後の ; を入力するまでは,SQLite は SQL 命令がまだ続くものとして待つ.
そのため,長い命令を途中で改行してもよい.
実習
上の命令で fruits 表を作ったあと,次の命令で表が作られたことを確認しよう.
1.tables
うまくいっていれば,
1fruits
のように表示される.
データを追加する:INSERT INTO
表にデータを追加するには INSERT INTO を使う.
今回の表では id は自動で入れるので,最初の値には NULL を指定する.
1INSERT INTO fruits VALUES(NULL, "banana", 100);
2INSERT INTO fruits VALUES(NULL, "strawberry", 200);
3INSERT INTO fruits VALUES(NULL, "apple", 150);
4INSERT INTO fruits VALUES(NULL, "water melon", 1500);
SQLite では文字列を "banana" のようにダブルクォーテーションで囲んでも動く場合があるが,他の SQL 処理系では 'banana' のようにシングルクォーテーションで囲むのが普通である.
本格的に SQL を学ぶときは,この点にも注意しよう.
データを見る:SELECT
表の中身を見るには SELECT を使う.
まず,表の全列を表示してみよう.
1SELECT * FROM fruits;
うまくいっていれば,次のような出力になる.
1+----+-------------+-------+
2| id | name | price |
3+----+-------------+-------+
4| 1 | banana | 100 |
5| 2 | strawberry | 200 |
6| 3 | apple | 150 |
7| 4 | water melon | 1500 |
8+----+-------------+-------+
ここで * は「全ての列」という意味である.
条件を指定して取り出す:WHERE

条件を指定して行を取り出したいときは WHERE を使う.
例えば,単価が1000円より大きい商品だけを取り出すには次のようにする.
1SELECT * FROM fruits WHERE price > 1000;
出力は次のようになる.
1+----+-------------+-------+
2| id | name | price |
3+----+-------------+-------+
4| 4 | water melon | 1500 |
5+----+-------------+-------+
文字列のパターンを指定したいときは LIKE を使える.
例えば,名前が nana で終わる商品を探すには,次のようにする.
1SELECT * FROM fruits WHERE name LIKE '%nana';
出力は次のようになる.
1+----+--------+-------+
2| id | name | price |
3+----+--------+-------+
4| 1 | banana | 100 |
5+----+--------+-------+
LIKE で使っている % は「任意の文字列」を表す.
つまり '%nana' は「最後が nana で終わる文字列」を意味する.
列を絞って表示することもできる. 例えば,単価だけを見たいなら次のようにする.
1SELECT price FROM fruits;
1+-------+
2| price |
3+-------+
4| 100 |
5| 200 |
6| 150 |
7| 1500 |
8+-------+
実習
次の3つを実行し,出力の違いを確認しよう.
1SELECT * FROM fruits;
2SELECT * FROM fruits WHERE price > 1000;
3SELECT name, price FROM fruits WHERE name LIKE '%nana';
データを修正する:UPDATE
表に入っているデータを修正するには UPDATE を使う.
1UPDATE テーブル名 SET 列名 = 新しい値 WHERE 条件;
ここで大事なのは WHERE を付けること である.
WHERE を省略すると,表の全ての行が更新対象になる.
実習
まず,water melon の価格を2000円に修正しよう.
1UPDATE fruits SET price = 2000 WHERE id = 4;
2SELECT * FROM fruits;
うまくいっていれば,次のようになる.
1+----+-------------+-------+
2| id | name | price |
3+----+-------------+-------+
4| 1 | banana | 100 |
5| 2 | strawberry | 200 |
6| 3 | apple | 150 |
7| 4 | water melon | 2000 |
8+----+-------------+-------+
次に,単価が300円未満の商品を2倍に値上げしてみよう.
1UPDATE fruits SET price = 2*price WHERE price < 300;
2SELECT * FROM fruits;
出力は次のようになるはずである.
1+----+-------------+-------+
2| id | name | price |
3+----+-------------+-------+
4| 1 | banana | 200 |
5| 2 | strawberry | 400 |
6| 3 | apple | 300 |
7| 4 | water melon | 2000 |
8+----+-------------+-------+
REPLACE INTO について
SQLite では REPLACE INTO という命令も使える.
例えば,次のような形で使う.
1REPLACE INTO fruits VALUES(4, "water melon", 2000);
ただし,REPLACE INTO は,指定した id のデータが存在しない場合には新規登録として扱われる.
単に既存データを修正したいだけなら,初学者はまず UPDATE ... WHERE ...; を使う方が安全である.
データを削除する:DELETE
表からデータを削除するには DELETE を使う.
1DELETE FROM テーブル名 WHERE 条件;
DELETE でも WHERE は非常に重要である.
WHERE を省略すると,表の全データが削除される.
実習
strawberry の行を削除しよう.
1DELETE FROM fruits WHERE id = 2;
2SELECT * FROM fruits;
出力は次のようになる.
1+----+-------------+-------+
2| id | name | price |
3+----+-------------+-------+
4| 1 | banana | 200 |
5| 3 | apple | 300 |
6| 4 | water melon | 2000 |
7+----+-------------+-------+
id = 2 が欠番になったことに注目しよう.
次に,新しい商品 orange を追加してみる.
1INSERT INTO fruits VALUES(NULL, "orange", 400);
2SELECT * FROM fruits;
出力は次のようになる.
1+----+-------------+-------+
2| id | name | price |
3+----+-------------+-------+
4| 1 | banana | 200 |
5| 3 | apple | 300 |
6| 4 | water melon | 2000 |
7| 5 | orange | 400 |
8+----+-------------+-------+
自動連番を使っているので,削除された id = 2 は再利用されず,新しい行には id = 5 が付いた.
ファイルからデータを読み込む:.import

データを1行ずつ INSERT するのは面倒である.
ファイルに書いたデータをまとめて読み込むには .import を使う.
今回は,区切り文字として | を使うファイルを作る.
まず,SQLite の外で,つまり普通のエディタで add-fruits.txt というファイルを作り,次の内容を書き込もう.
16|mango|200
27|kiwi|150
sqlite> プロンプトに戻って,次のように読み込む.
1.import ./add-fruits.txt fruits
2SELECT * FROM fruits;
うまくいっていれば,次のようになる.
1+----+-------------+-------+
2| id | name | price |
3+----+-------------+-------+
4| 1 | banana | 200 |
5| 3 | apple | 300 |
6| 4 | water melon | 2000 |
7| 5 | orange | 400 |
8| 6 | mango | 200 |
9| 7 | kiwi | 150 |
10+----+-------------+-------+
.import は SQLite コマンドなので,先頭が . で始まり,最後に ; を付けない.
.once と .excel
直後の出力1回だけをファイルへ保存したいときは .once が便利である.
例えば,次のようにすると,SELECT の結果が dout.txt に保存される.
1.once "dout.txt"
2SELECT * FROM fruits;
環境によっては,直後の出力を表計算ソフトで開く .excel も使える.
1.excel
2SELECT * FROM fruits;
うまく動く環境では,次のように表計算ソフトで結果を確認できる.
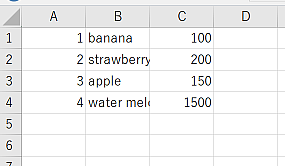
Windows 上の WSL などで .excel を試すには,xdg-utils などが必要になる場合がある.
授業時間中は,うまく動かなければ深入りしなくてよい.
複数の表をつなぐ

データベースの面白さは,複数の表を関係づけられることにある.
今回の例では,商品情報は fruits 表に,顧客情報は customers 表に,売上記録は sales 表に入れる.
sales 表には,顧客名や商品名を直接書かない.
代わりに,
customer_idに,customers表のidfruit_idに,fruits表のid
を入れる. こうしておくと,顧客名や商品名を1箇所だけで管理できる.
準備:customers 表を作る
次のように,顧客リストを作ろう.
1CREATE TABLE customers
2(id INTEGER PRIMARY KEY AUTOINCREMENT, name);
3
4INSERT INTO customers VALUES(NULL, "john");
5INSERT INTO customers VALUES(NULL, "tom");
6INSERT INTO customers VALUES(NULL, "mike");
中身を確認する.
1SELECT * FROM customers;
1+----+------+
2| id | name |
3+----+------+
4| 1 | john |
5| 2 | tom |
6| 3 | mike |
7+----+------+
準備:sales 表を作る
売上記録を入れる sales 表を作る.
この表には,
| 列名 | 意味 |
|---|---|
id |
売上記録そのものの番号. |
customer_id |
どの顧客か.customers.id を参照する. |
fruit_id |
どの商品か.fruits.id を参照する. |
quantity |
何個売れたか. |
を入れる.
1CREATE TABLE sales
2(id INTEGER PRIMARY KEY AUTOINCREMENT, customer_id, fruit_id, quantity);
次の5件の売上を追加しよう.
1INSERT INTO sales VALUES(NULL, 2, 5, 3);
2INSERT INTO sales VALUES(NULL, 1, 1, 1);
3INSERT INTO sales VALUES(NULL, 2, 3, 2);
4INSERT INTO sales VALUES(NULL, 2, 1, 4);
5INSERT INTO sales VALUES(NULL, 3, 4, 10);
中身を確認する.
1SELECT * FROM sales;
1+----+-------------+----------+----------+
2| id | customer_id | fruit_id | quantity |
3+----+-------------+----------+----------+
4| 1 | 2 | 5 | 3 |
5| 2 | 1 | 1 | 1 |
6| 3 | 2 | 3 | 2 |
7| 4 | 2 | 1 | 4 |
8| 5 | 3 | 4 | 10 |
9+----+-------------+----------+----------+
この表だけを見ても,customer_id = 2 や fruit_id = 5 が何を意味するかはすぐにはわからない.
そこで JOIN を使う.
JOIN で顧客名を見えるようにする
sales.customer_id と customers.id が同じ行を対応させるには,次のようにする.
1SELECT * FROM sales
2 JOIN customers ON sales.customer_id = customers.id;
出力は横に長くなるが,売上記録に顧客名が結合されていることがわかる.
1+----+-------------+----------+----------+----+------+
2| id | customer_id | fruit_id | quantity | id | name |
3+----+-------------+----------+----------+----+------+
4| 1 | 2 | 5 | 3 | 2 | tom |
5| 2 | 1 | 1 | 1 | 1 | john |
6| 3 | 2 | 3 | 2 | 2 | tom |
7| 4 | 2 | 1 | 4 | 2 | tom |
8| 5 | 3 | 4 | 10 | 3 | mike |
9+----+-------------+----------+----------+----+------+
表示する列を絞ると見やすくなる.
1SELECT sales.id, customers.name, fruit_id, quantity FROM sales
2 JOIN customers ON sales.customer_id = customers.id;
1+----+------+----------+----------+
2| id | name | fruit_id | quantity |
3+----+------+----------+----------+
4| 1 | tom | 5 | 3 |
5| 2 | john | 1 | 1 |
6| 3 | tom | 3 | 2 |
7| 4 | tom | 1 | 4 |
8| 5 | mike | 4 | 10 |
9+----+------+----------+----------+
id や name のように,複数の表に同じ列名があるときは,sales.id や customers.name のように 表名.列名 と書いて区別する.
JOIN を2回使って,顧客名と商品名を同時に見る
JOIN は続けて複数回使える.
sales に customers と fruits を両方つないでみよう.
1SELECT sales.id, customers.name, fruits.name, price, quantity FROM sales
2 JOIN customers ON sales.customer_id = customers.id
3 JOIN fruits ON sales.fruit_id = fruits.id;
1+----+------+-------------+-------+----------+
2| id | name | name | price | quantity |
3+----+------+-------------+-------+----------+
4| 1 | tom | orange | 400 | 3 |
5| 2 | john | banana | 200 | 1 |
6| 3 | tom | apple | 300 | 2 |
7| 4 | tom | banana | 200 | 4 |
8| 5 | mike | water melon | 2000 | 10 |
9+----+------+-------------+-------+----------+
これで,例えば第4回目の売上では tom が banana を4個買った,ということが読める.
同じ情報を何度も書かない
商品名や単価は fruits 表に1回だけ書く.
顧客名は customers 表に1回だけ書く.
売上記録は,それらの id を参照する.
これにより,表記ゆれや修正漏れを減らせる.
計算と集計

SQL では,取り出すだけでなく,簡単な計算もできる.
例えば,単価 price と個数 quantity から小計を計算するには,次のようにする.
1SELECT sales.id, customers.name, fruits.name, price, quantity, price*quantity FROM sales
2 JOIN customers ON sales.customer_id = customers.id
3 JOIN fruits ON sales.fruit_id = fruits.id;
1+----+------+-------------+-------+----------+----------------+
2| id | name | name | price | quantity | price*quantity |
3+----+------+-------------+-------+----------+----------------+
4| 1 | tom | orange | 400 | 3 | 1200 |
5| 2 | john | banana | 200 | 1 | 200 |
6| 3 | tom | apple | 300 | 2 | 600 |
7| 4 | tom | banana | 200 | 4 | 800 |
8| 5 | mike | water melon | 2000 | 10 | 20000 |
9+----+------+-------------+-------+----------+----------------+
さらに,顧客ごとの合計を出したいときは GROUP BY と SUM を使う.
1SELECT customers.name, SUM(price*quantity) FROM sales
2 JOIN customers ON sales.customer_id = customers.id
3 JOIN fruits ON sales.fruit_id = fruits.id
4 GROUP BY customers.id;
1+------+---------------------+
2| name | SUM(price*quantity) |
3+------+---------------------+
4| john | 200 |
5| tom | 2600 |
6| mike | 20000 |
7+------+---------------------+
これで,誰に合計でいくら請求すればよいかがわかる.
実習
上の GROUP BY の例を実行しよう.
その後,GROUP BY customers.id を別の列に変えたら何が起こるか考えてみよう.
レポート課題では,この考え方を使って商品ごとの売上合計を求める.
GROUP BY の感覚
GROUP BY は,「同じ値をもつ行をまとめる」操作である.
例えば GROUP BY customers.id とすると,同じ顧客に対応する売上行が同じグループに入る.
その各グループに対して SUM(price*quantity) を計算するので,顧客ごとの合計金額が得られる.
この考え方は,Unix のフィルタで sort | uniq -c として同じ行をまとめて数える操作にも少し似ている.
ただし SQL では,複数の列を持つ表を対象に,より構造的に集計できる.
対話操作から自動化へ

ここまでは,sqlite> プロンプトに1つずつ命令を打ち込んできた.
これは理解しやすいが,何度も同じ処理を行うには向いていない.
SQL 命令をファイルに書き,そのファイルを SQLite に読み込ませると,自動化しやすくなる. 例えば,次の内容の ds.sql というファイルを用意する.
1INSERT INTO fruits VALUES(NULL, "avocado", 550);
2INSERT INTO fruits VALUES(NULL, "coconut", 1050);
3INSERT INTO fruits VALUES(NULL, "peach", 830);
SQLite をいったん終了してから,シェルで次のように実行する.
1sqlite3 db1.db < ds.sql
あるいは,これまで学んだパイプを使って,次のようにしてもよい.
1cat ds.sql | sqlite3 db1.db
実行後,次のように1つの SQL 命令を直接渡して確認できる.
1sqlite3 db1.db "SELECT * FROM fruits;"
また,SQL 命令が1つだけなら,次のように直接実行できる.
1sqlite3 db1.db "INSERT INTO fruits VALUES(NULL, 'lemon', 180);"
2sqlite3 db1.db "SELECT * FROM fruits;"
Unix/Linux の考え方はここでも効く
ファイル,標準入力,リダイレクト,パイプを組み合わせると,データベース操作も自動化しやすくなる.
GUI ツールで眺める
コマンドラインで操作すると,何が起きているかを正確に理解しやすい. 一方で,表の中身を視覚的に確認したいときは GUI ツールも便利である.
SQLite のデータベースファイルを読み書きできる GUI ツールとして,例えば
DB Browser for SQLite がある.
Windows,macOS,Linux で使える.
下の図は,このツールで今回の実習の最後の JOIN と集計を確認している画面である.
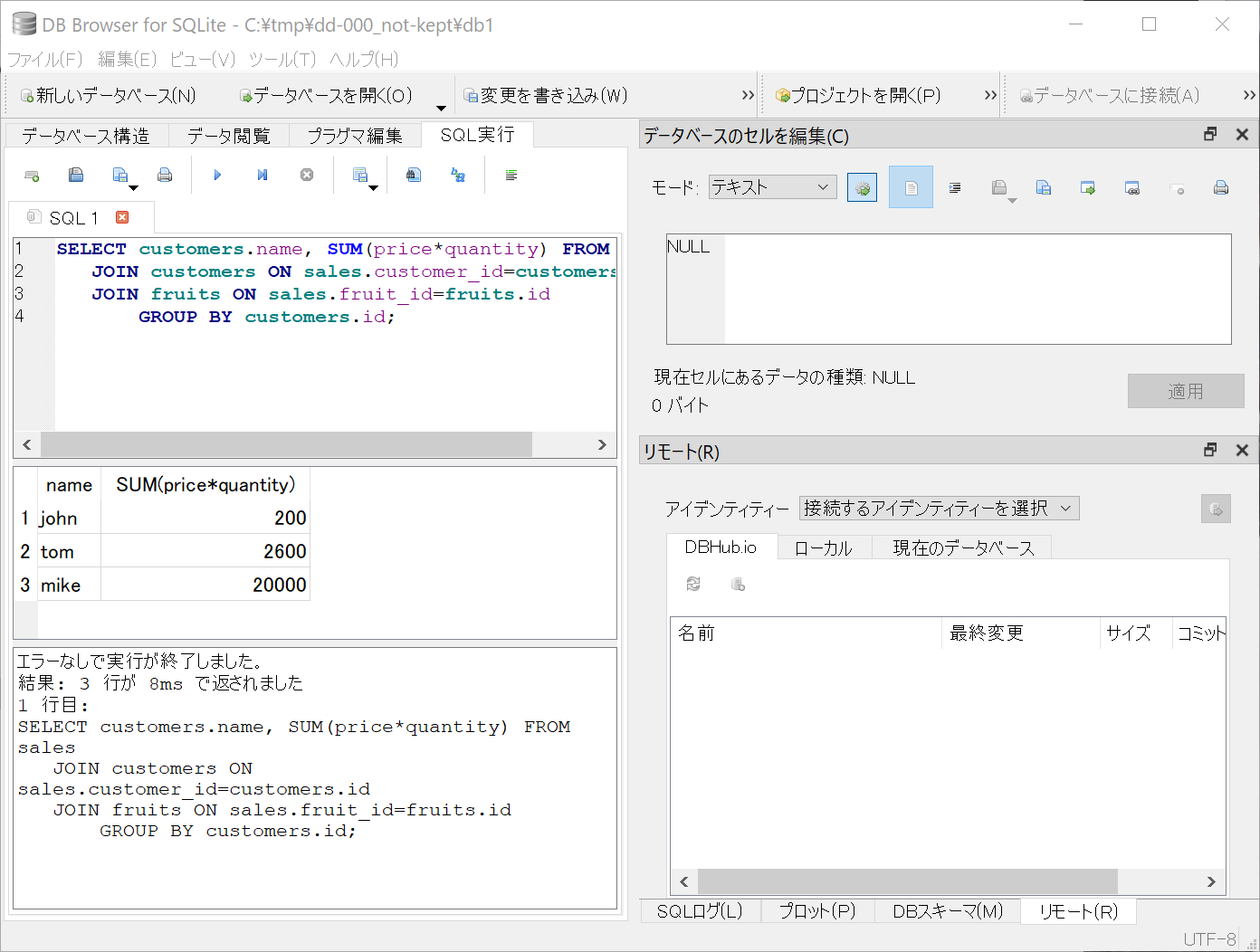
余裕がある人向け
DB Browser for SQLite を使い,今回作った db1.db を開いてみよう.
表の中身や SQL 実行結果を GUI で確認すると,理解が深まりやすい.
まとめ
今回学んだことをまとめる.
- SQLite では,1つのデータベースを1つのファイルとして扱える.
- SQLite には,
.showや.tablesなどの SQLite コマンドと,SELECTやINSERTなどの SQL コマンドがある. - 1つの表に対する基本操作は,作成・追加・表示・更新・削除である.
WHEREにより,必要な行だけを取り出せる.JOINにより,複数の表を共通の id でつなげられる.GROUP BYとSUMにより,まとまった集計ができる.- SQL をファイル化すると,データベース操作を自動化できる.
この回の内容は,単に SQLite の使い方というだけではない. データを表として整理し,必要な情報を機械的に取り出すという考え方は,研究データ,実験データ,成績データ,ログデータなど,さまざまな場面で役に立つ.
発展・補足編
以下は,基本編に対する発展・補足である. 授業時間に余裕がなければ扱わない. 興味がある者だけ読めばよい.
SQLite の参考資料
| 資料名 | 解説 |
|---|---|
| SQLite | SQLite の本家 web.ダウンロードや公式ドキュメントがある.Linux や WSL では,通常はパッケージ管理システムから入れる方が簡単である. |
| SQLite 入門 第2版,西沢直木,翔泳社,2009 | 少し古いが,入門には読みやすい. |
| “SQLite 入門” で検索して見つかる web 資料 | 丁寧な入門記事も多い.ただし,コピペするだけでなく,意味を確認しながら読むこと. |
学習環境ごとの注意
今回用いる sqlite3 コマンドが入っていない環境では,まずインストールが必要である.
Ubuntu や WSL の Ubuntu なら,おおむね次でインストールできる.
1sudo apt install sqlite3
Windows では,本家の download page から Windows 用のコマンドライン版を入れる方法もある. ただし,授業では環境ごとに利用可能なものを使えばよい.
.help コマンド
SQLite の中で
1.help
とすると,使える SQLite コマンドの一覧と簡単な説明が表示される.
特定の命令だけ調べたいときは,例えば次のようにする.
1.help import
2.help mode
3.help dump
SQLite のバージョンによって表示される命令は変わることがあるので,資料の例よりも,手元の環境で .help を確認する方が確実である.
.schema と .dump
表の定義を確認したいときは .schema が便利である.
1.schema
2.schema fruits
データベースの中身を SQL 命令の形で書き出すには .dump が使える.
バックアップやレポート課題の調査で役立つ.
例えば,次のようにすると,データベースの中身を backup.sql へ書き出せる.
1.once "backup.sql"
2.dump
この backup.sql は,データベースを再構成するための SQL 命令を並べたテキストファイルである. 普通のエディタで開いて読める.
DROP TABLE とやり直し
実習を最初からやり直したくなった場合,表を削除して作り直す方法がある.
1DROP TABLE fruits;
ただし,これは表ごとデータを消す操作である. 練習用なら構わないが,大事なデータベースで安易に実行してはいけない.
安全に練習し直すなら,SQLite を終了してから db1.db を別名でコピーしておくとよい.
1cp db1.db db1-backup.db
DB Browser for SQLite 以外の GUI ツール
SQLite を扱える GUI ツールは他にもある. 必要になったら,自分の環境や目的に合わせて調べるとよい.
| ソフト名 | 備考 |
|---|---|
| DBeaver | 高機能なデータベース GUI ツール.各 OS で使える. |
| Beekeeper Studio | 各 OS で使える GUI ツール. |
| SQLiteStudio | SQLite 用の GUI ツール. |
授業では,コマンドラインからの操作を理解することを優先する. GUI は,表の中身を確認したり,SQL 実行結果を視覚的に確認したりする補助として使うとよい.
Emacs の SQL モード
Emacs には,SQL を書いたり,データベースに接続したりするためのモードがある. Emacs を使い慣れている人は,次を試してもよい.
1M-x sql-sqlite
接続するデータベースファイルを聞かれたら,今回作った db1.db を指定する. エディタ上で SQL を編集しながら実行できるので,長い SQL を扱う場合には便利である.
下の図は,Emacs 上で今回の実習を行っている様子である.
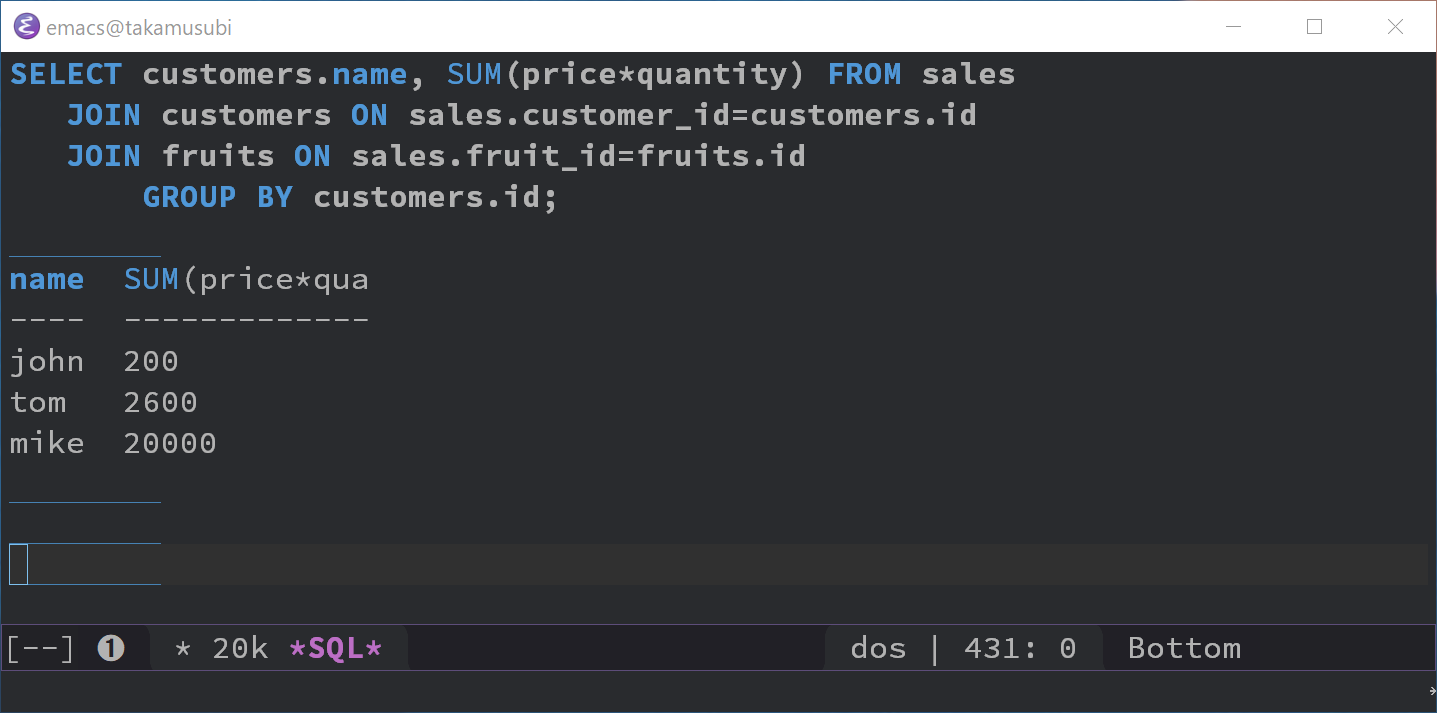
比較的新しい Emacs on Windows では,上の M-x sql-sqlite がうまく動かないことがある.
その場合は,見るだけなら
1M-x sqlite-mode-open-file
を試してもよい.
環境依存のトラブルがある場合
SQLite は比較的扱いやすいが,環境によっては表示や外部アプリ連携で問題が起こることがある.
特に .excel のように外部アプリを起動する命令は,OS,WSL,インストール済みアプリの状況に依存する.
授業中にうまく動かなければ,.excel には深入りせず,まずは SELECT の結果を端末上で確認できれば十分である.
レポート No.10
注意
近年はセキュリティ上の懸念から,実行形式のプログラムなどをメールに添付すると,受信側サーバがメールそのものを拒絶することがある.
そういう問題を避けるため,レポートをファイルで提出するときは,実行形式などの危険視されやすい形式を避けよう.
要するに,レポートは pdf ファイルにして送るのが良い,と思っておこう.
以下の課題について,自らの将来のスキルアップにつながるように調査と考察を行い,
学籍番号-氏名-10.pdf
というファイルとしてレポートを作成し,
webフォーム
から教官宛に提出しよう.
なお,レポートを $\TeX$ 等で作成したものを印刷した紙媒体を教官に直接手渡す形で提出してもよいが,物質によるレポート提出は常に破損や紛失の可能性があるのであまりお勧めはしない.
課題
-
上の実習を続けて,どの商品が合計でいくら売れたか を出力する SQL コマンドを考えよう. 結果は次のようになるはずである.
1+-------------+---------------------+ 2| name | SUM(price*quantity) | 3+-------------+---------------------+ 4| banana | 1000 | 5| apple | 600 | 6| water melon | 20000 | 7| orange | 1200 | 8+-------------+---------------------+ -
SQLite でデータベースの情報をテキストファイル等にバックアップしておく方法を調べよう.
ヒント:.dumpコマンドを使うとよい.直前で.onceコマンドを使うと,出力をファイルに保存できる. -
自分の生活や研究・学習の中で,SQLite を利用すると便利になりそうな場面がないか考えよ. 例えば,読書記録,実験記録,計算ログ,講義資料の管理,研究会参加記録など,何でもよい.
-
SQLite のデータベースを GUI で操作できるアプリケーションとして DB Browser for SQLite を紹介した. 授業中に触らなかった者は,できればこれを使ってみよう. また,他の似たようなツールもあるので,興味があれば試してみよう.
-
チャレンジ問題として,シェルスクリプト,C,Python,Go,PHP 等のどのような言語でもよいので,SQLite を使ってデータベースを読み書きするプログラムを書いてみよう. ネットワークで検索するとサンプルは多数見つかるので,まずは小さな例を動かしてみるとよい.