05. フィルタ

この回で身につける考え方
この回では,Unix のフィルタを使って,テキストデータを少しずつ加工していく方法を学ぶ. この回で最も大事なのは,個々のコマンドを暗記することではなく,
小さな処理をパイプでつないで,大きな処理を作る
というフィルタの考え方である.
具体的には,
- データを流す
- 必要な行を取り出す
- 並べ替える
- 重複をまとめる
- 数える
- 必要な列を取り出す
- 一時的な指標を付けて並べ替える
- パターンを指定する
という処理を,cat, grep, sort, uniq, wc, awk, DSU, 正規表現などを通じて学ぶ.
Tips: Unix でのデータ処理の対象は
Unix でデータ処理を行う際、その対象は多くの場合は「行」である.
プログラムは「1行分のデータを貰って」「処理をして」「1行のデータを出力する」の繰り返しで動く. そう認識しておくと、以下のフィルタの話がわかりやすいだろう.
フィルタ
フィルタとは,入力したデータを加工して出力するプログラム一般のことだ.
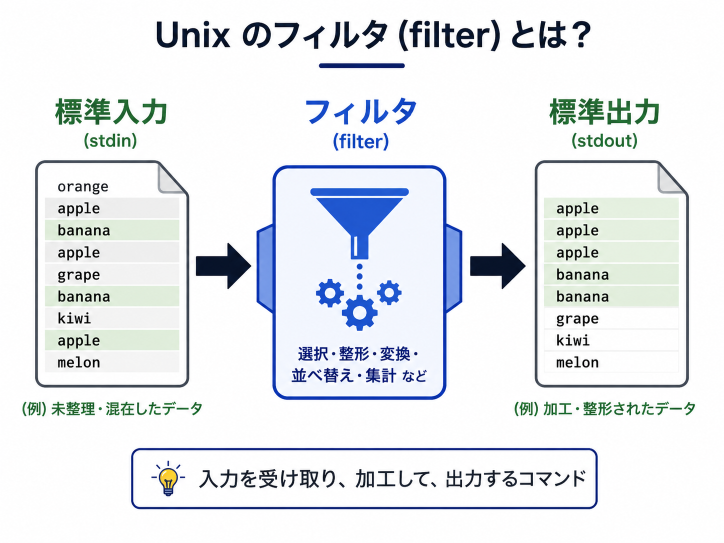 unix には単純な機能を持つフィルタが多い.
これらをパイプでつなげて、
unix には単純な機能を持つフィルタが多い.
これらをパイプでつなげて、
- データを流す
- 途中で加工する
- 必要な部分だけ取り出す
- 結果を次の処理に渡す
と処理すると,複雑で大量のデータ処理が簡単にできるぞ
ちょっと準備
今回の授業で具体例や実習のための準備を下記のように行おう.
- (安全のために)実習用ディレクトリを作り、そこへ移動する.たとえば以下のように.
1cd ~ ← ホームディレクトリへ移動
2mkdir work ← work というディレクトリを作成
3cd work ← work ディレクトリへ移動
- サンプルとなるファイル sample.txt を作成する.たとえば
1emacs sample.txt ← 作成するファイル名を指定して emacsエディタを起動する
として emacs エディタを起動し、起動した emacs を用いて下記の内容を書き込んで保存する. 念の為に emacs は終了しておこう.
Frank physics 075
Carol math 91
Alice math 82
Eve math 82
Bob physics 75
Dave chemistry 68
注意: emacs をインストールしていない人は 第3回授業の脚注 1を参照してインストールしておこう.
- 以降はこの sample.txt ファイルを用いるので、今の work ディレクトリに居る状態のままにしておこう.
単機能フィルタ
今回の授業では、(ほぼ)単純な機能のフィルタを紹介する. その機能と、組み合わせてできるよく知られた例を学ぼう.
cat ファイルの中身を標準出力に出す
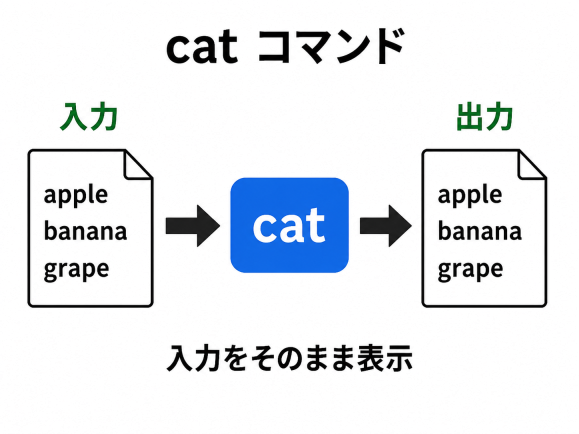
[使い方]
cat ファイル名とするとファイルの中身を そのまま 標準出力に吐き出す.- 複数のファイルを与えて
cat ファイル名1 ファイル名2 ファイル名3などとすると、順番に 中身を連結して 標準出力に吐き出す. - ファイル名を与えてないときや,ファイル名として "-" (ハイフン)を与えたときは、標準入力を読込んで出力する.
利用方法としては、
- (フィルタとしての使い方)
コマンド | catとすると、コマンドの出力をそのまま出力する.ただし、catにオプションをつけると少し動作が変わる(下記に記載) - 単にテキストファイルの中身を表示する
- 複数の結果をまとめる
- オプション
-n: 出力に行番号を与える - オプション
-s: 空白行をまとめる - オプション
-A: 目に見えない文字を見えるようにする
などがよく知られている.以下、例を見よう.
なお、フィルタの動作を理解しやすいように、以下ではコマンドを少しずつ実行・表示して解説したりしている.
実行例 1: 単に テキストの中身を出力する
1cat sample.txt ← sample.txt の中身を出力
とすると,さきほど準備した sample.txt の中身を出力できる.
実行例 2: テキストを連結する
1cat file1 file2 ← file1 と file2 の中身を連結して出力
2cat file1 file2 > sum-file ← その出力を sum-file に書き込む
とすると,file1 の中身に file2 の中身を続けた結果を sum-file に出力できる.
実行例 3: 行番号をつける
1ls -lga ← 単なる出力
2ls -lga | cat -n ← オプションを付けた cat がデータを貰って出力
3ls -lga | cat -n | less ← それを viewer で見る
とすると,出力結果に行番号を簡単につけられる.理解のため、順番にやってみよう.
実行例 4: 空行をまとめる
sample2.txt というファイルの中身が、空行だらけの下記のようだったとしよう.
apple
banana
orange
このファイルに対して、
1cat -s sample2.txt
とすると,空白行はまとめられて、出力は以下のようになる.
apple
banana
orange
実行例 5: 見えない文字を見えるようにする
たとえば、以下の内容のテキストファイル sample3.txt があるとする.
apple
banana orange
grape
コマンド less などでこのファイルを見た場合、上のように表示される.
そのため気づかないが、実はこの 2行目の banana と orange の間には「タブ文字」があり、3行目の grape の後ろには空白文字がある.
しかし、
1cat -A sample3.txt
とすると、
apple$
banana^Iorange$
grape $
と表示される.タブや、行末の空白などが認識できるようになる(記号はすぐ解説する).
上の例に出てきた見慣れない $ や ^I という記号だが、その他にも cat -A で良くでてくるものとあわせて意味を下記に記そう.
| 文字 | 意味 |
|---|---|
| $ | 行末 |
| ^I | タブ文字 |
| ^[ | ESC文字 |
| ^? | DEL文字 |
| ^M | CR(Carriage return)文字 注: Windows では LF文字と合わせて CR LR とすると「改行」の意味になる |
grep 与えた「パターン」を含む箇所を検索する
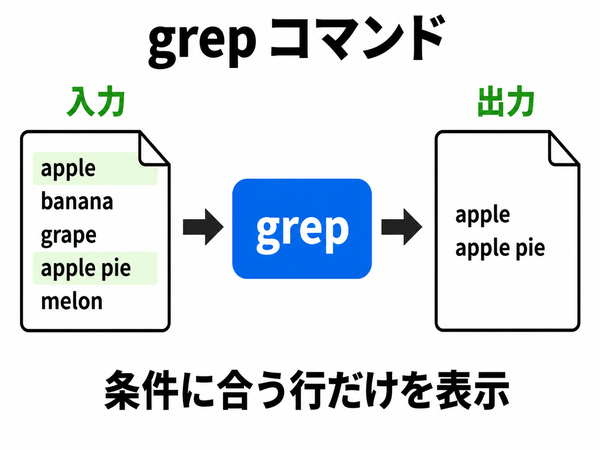
grep コマンドは、もらったデータの行が 与えた「パターン」を含む場合、出力する.
まあ、要は 検索 だ.
パターンは、単なる文字列 か、基本正規表現 と呼ばれるものを使う. 単なる文字列は説明不要だろう. 正規表現については、 正規表現 としてこのあとすぐ学ぶ.
[使い方]
- (フィルタとしての使い方)
コマンド | grep パターンとすると、コマンドの出力の中のパターンに合致する行を出力. grep パターン ファイル名とすると、そのファイル中のパターンに合致する行を出力.- ファイル名を与えてないときやファイル名として "-" (ハイフン)を与えたときは、標準入力を読込み、パターンに合致する行を出力.
利用方法としては、
- コマンド出力の必要な行だけ抜き出す
- 単にテキストファイルの中身を検索する
- オプション
-i: 探すパターンで 大文字・小文字を区別しない - オプション
-n: パターンに合致した行に、行番号をつける - オプション
-r: 対象フォルダ以下のファイルを再帰的に対象として検索する
などがよく知られている.以下、例を見よう.
実行例 1: コマンドの出力の中で合致する行を出力する
たとえば,bash を使ったり,bash 経由で起動したソフトウェアがある状態でその様子を知りたいとしよう. その際、
1ps axu ← ps コマンドの出力全部がでてくる
とするとプロセスすべてが表示されてしまうが、
1ps axu | grep bash ← ps コマンドの出力の、bash という文字列を含む行だけ出力される
とすれば該当行だけが表示される.
注意: この結果に、grep bash 自身が含まれることがある.これは、grep を実行している瞬間には grep 自身もプロセス一覧に含まれるからである.
実行例 2: ファイル中のパターンに合致する行を出力する
たとえば今回準備した sample.txt を対象として、
1grep math sample.txt ← sample.txt中で、math という文字列を含む行だけ出力される
とすると、
Carol math 91
Alice math 82
Eve math 82
という出力が得られる.
実行例 3: 探すパターンの大文字・小文字を気にしない
たとえば今回準備した sample.txt を対象として、Bob のデータを検索しようとして、
1grep bob sample.txt ← bob という文字列を含む行を探すが…
とすると、大文字・小文字を厳密にみて bob を含む行が無いため、なにも出力されない.
これに対し、-i オプションを付けて
1grep -i bob sample.txt ← 大文字・小文字を無視して bob という文字列を含む行は?
とすると、大文字・小文字の違いが無視されて検索され、
Bob physics 75
という結果を得る.つまり、うまく見つかった.
実行例 4: 見つかった行に行番号をつける
たとえば今回準備した sample.txt を対象として、
1grep -n Dave sample.txt ← Dave という文字列を含む行は?
とすると、
6:Dave chemistry 68 ← 最初の 6: が、行番号 6 を意味する.
という出力になり、ファイル中の 6行目のデータが合致したことが判明する.
実行例 5: 再帰的に、該当するファイルすべてを対象として検索する
たとえば、fruits というディレクトリに a.txt, b.txt というファイルがあり、さらにそこに sub というディレクトリがありその中に c.txt というファイルがあるとしよう.そしてそれぞれのファイルには apple, banana, red apple という文字列が入っているとする.図にすると下記のような感じだ.
fruits/
├── a.txt apple
├── b.txt banana
└── sub/
└── c.txt red apple
そして、fruits ディレクトリの「上」のディレクトリで
1grep -r "apple" fruits
とすると、fruits 以下のファイルがまとめて検索対象となり、
fruits/a.txt:apple
fruits/sub/c.txt:red apple
という出力が得られる.
実習: grep に関する上の実行例の、1から4までを実際に行ってみよう.
さてここで grep にからむ重要なことを述べておこう.
目で探してはいけない!
コンピュータ操作でなにかを「探す」シーンは多いが、自前の「目」で行うと
- 遅い
- 見逃しやすい
- 目の「健康」に悪い ← とくにコレは気にすべきだ
と、悪いことばかりだ.検索には grep などのコンピュータの機能を使おう.
ちなみに、適切に grep などのツールなどを使わずに目で探すことを "eyeball search" とか "vgrep (visual grep)" などと言う.
sort 順番に並べ直す
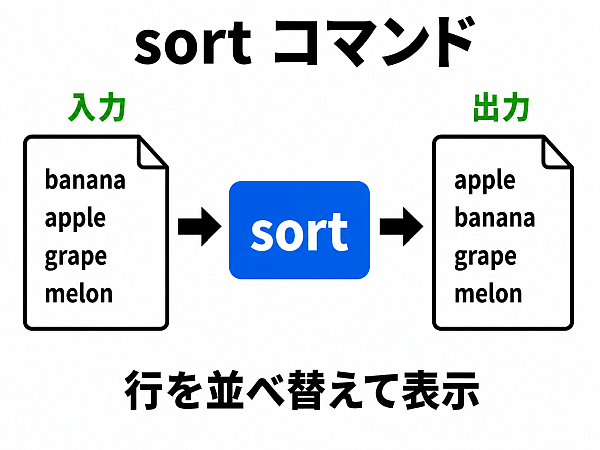
与えられた行を 並べ直す フィルタである. データを処理する際、頻繁に使う.
並べ方のデフォルトは辞書式順序だ.数字の大きさ順で並べるには(後述する)オプション -n を用いよう.
[使い方]
- (フィルタとしての使い方)
コマンド | sortとすると、コマンドの出力を並べ直して出力 sort ファイル名とすると、そのファイルの中身を並べ直して出力- ファイル名を与えてないときやファイル名として "-" (ハイフン)を与えたときは、標準入力を読込み、並べ直して出力.
利用方法としては、
- コマンド出力を用途に合うように並べ直す
- ファイルの中身を用途に合うように並べ直して出力する
- オプション
-r: 逆順に並べる - オプション
-k: 並べる手がかりの(行中の)場所指定.デフォルトは 1. - オプション
-n: 数字として数値順に並べる
などがよく知られている. 以下、例を見よう.
実行例 1: コマンド出力を並べ直す
たとえば今回準備した sample.txt を並べ直すことを考える.
1cat sample.txt ← 中身を出力
2cat sample.txt | sort ← catコマンドの結果を sort が受け取り、並べ直して出力
としよう. すると、(各行の第1項目を手がかりに) 並べ直した結果
Alice math 82
Bob physics 75
Carol math 91
Dave chemistry 68
Eve math 82
Frank physics 75
が得られる.
実行例 2: ファイルの中身を並べ直して出力
たとえば今回準備した sample.txt を並べ直すならば、
1sort sample.txt ← sort が sample.txt の中身を並べ直して出力
でよい.結果は実行例 1 のものと同じはずだ.
実行例 3: 逆順に並べる
たとえば今回準備した sample.txt を 逆順に 並べ直すならば、
1sort -r sample.txt ← sort が sample.txt の中身を逆順に並べ直して出力
とすると、
Frank physics 075
Eve math 82
Dave chemistry 68
Carol math 91
Bob physics 75
Alice math 82
という出力が得られる.
実行例 4: 並べる手がかりの位置を指定する
たとえば今回準備した sample.txt を、データの行の中の第 2項目(授業名?)を手がかりに並べ直すならば、
1sort -k 2 sample.txt ← sort が sample.txt の各行の第2項目を手がかりに並べて出力
とすると、
Dave chemistry 68 ← 第2項目は chemistry
Alice math 82 ← 第2項目は math
Carol math 91 ← 第2項目は math
Eve math 82 ← 第2項目は math
Frank physics 075 ← 第2項目は physics
Bob physics 75 ← 第2項目は physics
となり、各行の第2項目が手がかりとして使われて、chemistry, math, physics の順に並んだことがわかる.
実行例 5: 文字ではなく、数字として扱って並べる
たとえば今回準備した sample.txt を、データの行の中の第3項目(点数?)を手がかりに並べ直そう. まず、単純に
1sort -k 3 sample.txt ← sort が sample.txt の各行の第3項目を手がかりに並べて出力
としてみると、
Frank physics 075 ←あれ? 75点なのに、すぐ下の 68点より前に表示される…
Dave chemistry 68
Bob physics 75
Alice math 82
Eve math 82
Carol math 91
という結果になる. よく見ると、Frank の 75点が Dave の68点より前になってしまっていて、意図した結果になっていない.
これは、Frankの点数のみが3桁表記で 075 と書かれているせいだ. 「辞書式順序」で並べると、075 は 68よりも前になってしまうのだ.
こういう間違いが起きないように、数字を比べる時は「数字順」になるように -n オプションを付けると良い.
具体的には、下記のようにすることになる.
1sort -n -k 3 sample.txt ← sample.txt の各行の第3項目を手がかりに数字順に並べて出力
すると、次のような「納得いく」結果が得られる.
Dave chemistry 68
Bob physics 75
Frank physics 075
Alice math 82
Eve math 82
Carol math 91
実習: sort に関する上の実行例の、1から5まですべてを実際に行ってみよう.
uniq 重複を除去する
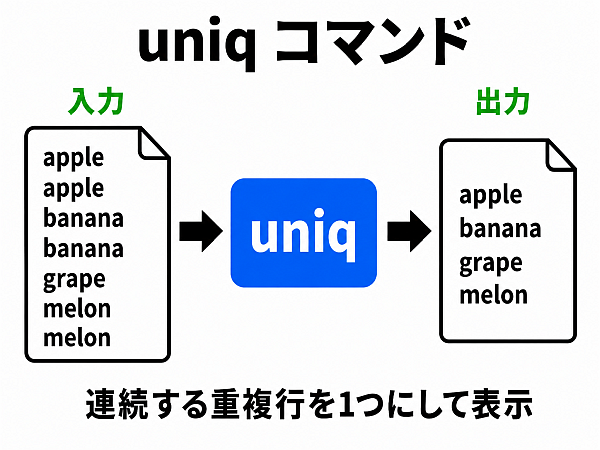
前後に同じ行をまとめる フィルタである.
データ処理で sort フィルタを通すと、前後に重複する行が続くことが多い.
そうした際、uniq フィルタが役に立つ.
[使い方]
- (フィルタとしての使い方)
コマンド | uniqとすると、コマンドの出力の前後に重複する行を 1行にして出力 uniq ファイル名とすると、そのファイルの中身の前後に重複する行を 1行にして出力- ファイル名を与えてないときやファイル名として "-" (ハイフン)を与えたときは、標準入力を読込み、並べ直して出力.
利用方法としては、
- コマンド出力の無駄な重複を削って出力
- ファイルの中身の無駄な重複を削って出力
sort | uniqという、sortコマンドとのコンボ- オプション
-c: 「何回重複したか」も出力. - オプション
-d: 重複した行のみを出力. - オプション
-u: 重複しなかった行のみを出力.
などがよく知られている. 以下、例を見よう.
実行例 1: 重複を削除
たとえば、/usr/bin と /usr/local/bin という、コマンドファイルがたくさん格納してある2つのディレクトリを例に挙げよう.
この2つのディレクトリにあるファイルを重複なしで全部列挙して見るには、
bash などならば
1(ls /usr/bin; ls /usr/local/bin) | sort | uniq | less
とすればよいし、fish ならば
1begin; ls /usr/bin; ls /usr/local/bin; end | sort | uniq | less
とすればよい.
注意: ls コマンドの挙動を alias で変更している人は,上の例の中の ls という部分を \ls と置き換えて実行しよう.
ちなみに,コマンドに \ をつけて実行するのは,「alias があってもコマンドそのものを呼び出す」という意味である.
単に出力をまとめたいという目的で bash などのシェルで ( aaa; bbb ) とするところでは、fish では begin; aaa; bbb; end とすれば良い.
このような sort | uniq のコンボはよく使われる.覚えてしまおう.
実行例 2: 重複を検知
実は、/usr/bin と /usr/local/bin には同じ名前のコマンドファイルは無いことが望ましい.
同じ名前のコマンドファイルが複数点在するのは事故のもとなので.
というわけで、こうしたファイルが無いかチェックしよう.
bash を使っている場合は、 uniq コマンドを使って次のようにすれば良い.
1(ls /usr/bin; ls /usr/local/bin) | sort | uniq -d
fish を使っている人は次のようにすればよい.
1begin; ls /usr/bin; ls /usr/local/bin; end | sort | uniq -d
ちなみに、上の重複チェックの結果はおそらく空っぽだろう. もしもここに出力がある場合は少し注意が必要だ.これは重要なツールが二箇所に重複して存在するということなので. 名前が同じで中身が異なる場合は警戒しよう.
実習: uniq に関する上の実行例 1,2 を実際に行ってみよう.
wc 数える
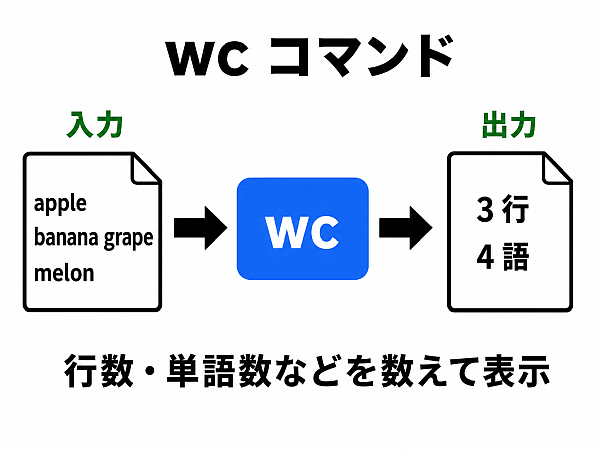
入力データの 「行数」「単語数」「byte 数」を出力 するフィルタ.
地味だが意外に役立つので覚えておこう.
使い方等は簡単なので、例を示してしまおう.
実行例 1: ファイル中のデータの行数、単語数、byte数を出力
1wc sample.txt
とすると,
7 18 94 sample.txt
のように行数・単語数・バイト数 が出力される.
実習: man wc として、wcコマンドのオプションを調べよう.
awk (の一部分) 入力データを要素ごとに分解して取り扱う
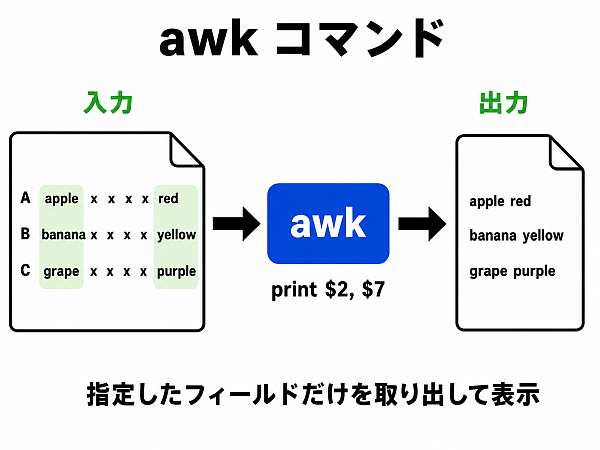
awk は高度なプログラミング機能をもつコマンドだが、ここでは、入力行の 項目を好きなように並べ直せる フィルタの機能のみ紹介しよう.より高度な機能は次回以降に説明する.
そして今回紹介する機能だが、 「スペースや ,(カンマ) で区切られたデータが連なる行に対して,区切られたそのデータを好きなように抜き出せる」というものだ.
そのデータは,行頭から数えて $1, $2, ... という名前で扱うルールだ.
なお、$0 は特殊で、「全部」という意味になる.
[使い方]
- (フィルタとしての使い方)
コマンド | awk '{print $k}'とするとコマンドの出力の各行のそれぞれ行頭から数えて k番目の要素を出力 - (フィルタとしての使い方)
コマンド | awk '{print $k,$l}'とするとコマンドの出力の各行のそれぞれ行頭から数えて k番目と l番目の要素を出力.以降、同様に3個以上の要素の出力も可. awk '{print $k}' ファイル名とするとファイルの各行のそれぞれ行頭から数えて k番目の要素を出力awk '{print $k, $l}' ファイル名とするとファイルの各行のそれぞれ行頭から数えて k番目と l番目の要素を出力(同様にいくつでも出力できる)
実行例 1: 各行の行頭から数えて k番目、l番目のデータを出力
たとえば
1cat sample.txt | awk '{print $2, $1}'
とすると、各行の第1要素と第2要素のみが, 下記のように第2要素を先にして出力される.
physics Frank
math Carol
math Alice
math Eve
physics Bob
chemistry Dave
実習: awk に関する上の実行例を実際に行ってみよう.
DSU: フィルタ処理の基本手法
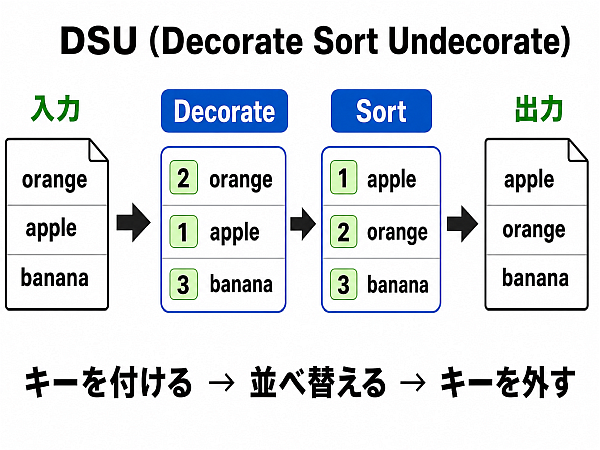
データ処理の途中で「一時的に指標を作りそれに基づいて処理をし、その後はその指標は不要だ」という場面がよくある.
たとえば、ファイル sample.txt のデータを 「 1行あたりの文字数の多い順に並べ直す」例を考えてみよう. そのための基本的な手順は次のようなものになるだろう.
1cat sample.txt | awk '{print length, $0}'
2 ↑ sample.txt の各行の「長さ」を各行の行頭に追加.
3
4cat sample.txt | awk '{print length, $0}' | sort -nr
5 ↑ その行頭を数字とみなして、大きな順に並べ直し
6
7cat sample.txt | awk '{print length, $0}' | sort -nr | awk '{print $2,$3,$4}'
8 ↑ 行頭の要素はもう不要なので、もともとの情報だけ出力する
注意: awk 内部では length というコマンドが使えて、これは「もらった1行データの文字数」を出力する.こうした詳細は次回以降に説明する.
このテクニックはデータ処理では基本で、
指標を追加し、ソートし、追加指標を除去する = Decorate Sort Undecorate
の頭文字を取って DSU などと呼ばれている. よく使うし、なにより役に立つテクニックなので覚えておこう.
実習: DSU に関する上の実行例を実際に行ってみよう.
フィルタを組み合わせた面白い例
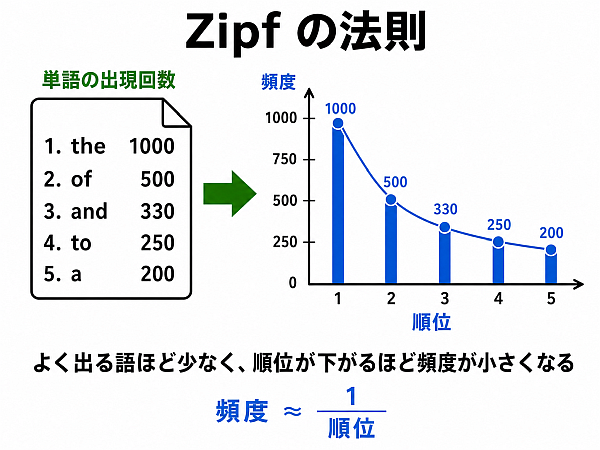
フィルタを組み合わせると複雑なことができる例として、Zipf の法則 を確かめる下記のものがある.紹介しよう.
まず、適度に長い、英語テキストのファイルを用意する.名前を sample4.txt としておこう. ここでは、2026年1月の阪大総長挨拶英語版 をテキストファイルの中身として扱ってみる.
次に、下記のフィルタを組み合わせたコマンド群を実行する
1grep -oE '[[:alpha:]]+' sample4.txt
2 ↑ テキスト中の単語っぽいものだけ取り出す
3
4grep -oE '[[:alpha:]]+' sample4.txt \
5 | awk '{print tolower($0)}'
6 ↑ すべて小文字にする
7
8grep -oE '[[:alpha:]]+' sample4.txt \
9 | awk '{print tolower($0)}' \
10 | sort | uniq -c \
11 ↑ 並べ直して、重複数を数えて記載する
12
13grep -oE '[[:alpha:]]+' sample4.txt \
14 | awk '{print tolower($0)}' \
15 | sort | uniq -c \
16 | sort -nr
17 ↑ 重複数の大きな順に並べる
18
19grep -oE '[[:alpha:]]+' sample4.txt \
20 | awk '{print tolower($0)}' \
21 | sort | uniq -c \
22 | sort -nr \
23 > result.txt
24 ↑ 結果をファイルに記録する
注意 1. シェルへの命令は 1行で書かなくても良い.次の行へ続ける時は行末に \ を書けば良い.
注意 2. grep -oE '[[:alpha:]]+' はデータ中の「英字のみからなる固まりだけ」を抜き出す.その結果、「単語っぽい」ものを抜き出せる.-o が「該当するものだけ」という意味で、-E '[[:alpha:]]+' が「英字のみからなる固まり」という意味になる.気になる人は調べておこう.
注意 3. awk '{print tolower($0)}' は受け取ったデータを小文字化するものだ.awk 中で使える tolower コマンドを使っている.
そして、こうやって作ったファイル result.txt には、入力ファイル sample4.txt 中の「英単語」が出現回数と共に,出現回数の多い順に並んでいるはずだ.
ちなみに、上で挙げた英文を解析すると、頻出単語の top10 は以下のような感じだ(タイトル等を文に含めるか等で数字は変わってくるので自分でも試してみよう).
| 出現回数順位 | 出現回数 | その単語 |
|---|---|---|
| 1 | 65 | the |
| 2 | 41 | of |
| 3 | 39 | and |
| 4 | 32 | to |
| 5 | 24 | university |
| 6 | 20 | research |
| 7 | 17 | a |
| 8 | 14 | we |
| 9 | 14 | in |
| 10 | 13 | our |
そして、ちなみに、出現回数の多い方から単語を単語1,単語2,... とナンバリングし(上の表の順位と同じ)、横軸にそのナンバーを、 縦軸にそのナンバーの単語の出現回数を並べたグラフは次のような感じだ. 上が素のグラフ, 下は両軸を対数にしたグラフだ. 特に下のグラフが「直線状にほぼ -1 の傾きでプロット点が並んでいる」ことから,Zipf の法則が成り立っているように見えるね.


蛇足までに,上のグラフはそれぞれ Julia と呼ばれる最新の科学技術用言語(この講義の後半で解説する予定)の Plots package の plot 命令で出力したものだ.
例えば data という1次元配列変数に大きい方から出現回数を要素として数字を入れておいて,これを
1plot(data, w = 3, marker = :circle, xlabel = "word order", ylabel = "count", label = nothing )
とすると上のグラフが,
1plot(data, w = 3, marker = :circle, xlabel = "word order", ylabel = "count", label = nothing )
2xaxis!(:log10)
3yaxis!(:log10)
とすると下のグラフが得られる.
実習: Zipf の法則の確かめ、に関する上の実行例を実際に行ってみよう.ただし、グラフ描画が難しいという人はその手前までで良い.
正規表現: パターン指定を柔軟に行う
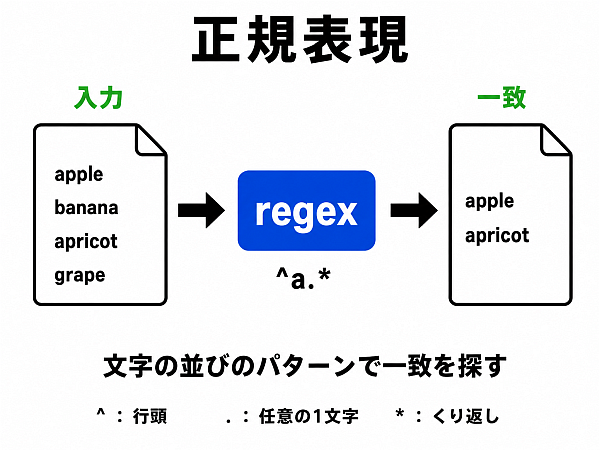
さて、grep などにおけるパターンの指定に用いるとして名前だけ紹介した正規表現についてである.
この正規表現とは,文字列の集合を表すために考えられたルールの一つである.
[使い方]
grepを始め、「検索」がからむコマンドで、パターンを表すために用いる- emacs などのエディタで、編集を素早くかつ大量に行うために用いる
と言ってもよくわからないだろうから、まずは下記にその最小セットを示し、その後に具体例を見てもらおう.
| (基本)正規表現 | 意味 |
|---|---|
| 通常文字 | 下記のメタキャラクタでない文字. |
| \ ^ $ . [ ] * 拡張正規表現では * + ? { } ( ) ¦ も. |
メタキャラクタ. 特別な意味を持つ. |
| \m | メタキャラクタ m を通常文字として扱う |
| . (ピリオド) | 任意の一文字 |
| * | 直前の正規表現の 0 回以上の繰り返し |
| ^ | 行頭 |
| $ | 行末 |
| [ ] | [ と ] とで囲まれた文字のどれか一文字 |
| [ c1 - c2 ] | 文字 c1 から c2 までの範囲の文字中のどれか一文字 |
| [^ ] | [^ と ] とで囲まれた文字以外の一文字 |
実行例 1: emacs でファイル編集
ここまで使ってきた sample.txt を、下記のようにして emacs で「正規表現を使って」編集してみよう.
まず
1emacs sample.txt
として emacs で sample.txt を読み込む.
そしてその emacs の画面で、
1M-x replace-regexp
2 ↑ これは、正規表現を使って文字列置換を行うコマンドだ.
3 ↑ なお、M-x は、Escキーを押して離してから x キーを押す、という意味.
4 ↑ つまり、Escキーを押して離し、xキーを押してから replace-regexp と入力する.
としてみよう.
とすると emacs 画面の一番下ぐらいに
1Replace regexp:
と出て,入力を要求される(この部分を ミニバッファ と呼ぶ).
これは「置換すべき対象」を正規表現で入力しろ,と言われているので、まずは
1c.*y
と入力して Return を押そう. ちなみにこれは chemistry と打つのが面倒なのでその代わりにこう打ち込んでいる、という想定だ.
するとミニバッファにさらに
1Replace regexp c.*y with:
と出て,入力を要求される. これは 「何に置換するのか」を正規表現で入力しろ, ということであるので,今回はたとえば music を入力して return を押そう.
すると Dave の成績の行が、chemistry 68 から music 68 に変わるはずだ.
実習
- 正規表現に関する上の実行例を実際に行おう.
さらに続けて、正規表現をうまく使って sample.txt ファイルの中の math という文字列をすべて art に書き換えよう.
- 正規表現クロスワード の "Tutorial" をやってみてから、"Puzzles" をいくつかやってみよう.
発展・補足編
基本編の内容に対する、発展・補足的な内容を以下に述べる.
学習初期においては無視しても良い内容として、授業時も解説を省略する予定である.
grep 一族の他の方々
grep 一族には(見かけ上)他のプログラムがある.
慣れてきたら使い分けるとなにかと便利なので,頭の片隅にいれておこう.
| 氏名 | 性格 |
|---|---|
egrep |
パターンに「拡張正規表現」を使う(すぐこのあと、 正規表現 のところで学ぶ). grep -E と同等のはず. |
fgrep |
パターンを「単なる文字列」として扱う. つまり,正規表現「無し」バージョン. パターンが正規表現で解釈されると困る場合はこちらで. しかし, fgrep は必ずしも高速ではない( fgrep の f は fast ではなくて fixed- の頭文字である). grep -F と同等のはず. |
zgrep |
圧縮したファイルを解凍してから,その中身を検索する. 古い環境だとこのコマンドが無いかも. grep -z と同等のはず. |
sort コマンドのオプション解説表.
| オプション | 解説 |
|---|---|
-k pos1[,pos2] |
対象フィールドの指定.pos1 から pos2 までの内容で比較する. pos2 を省略すると、行末まで. |
-t sep |
対象フィールドの区切り文字の指定. 例えば、", "(カンマ) で区切りたい場合は、 sort -t ',' などとする. |
-r |
逆順にソートする. |
--debug |
対象フィールドを強調してくれる.便利. この機能を持たない sort コマンドもある. |
-u |
出力時に、重複を除去する.-c (チェックモード)の時(つまり、sort -c -u )は、「並んだ行に重複がないかをチェックする」. |
--parallel=N |
N 個のプロセッサを使って並列実行する. この機能を持たない sort コマンドもある. |
-n |
普通に数字として数値順にソートする. |
-f |
大文字小文字を同一視してソートする. |
-g |
「浮動小数」に変換して、その数値順でソートする. 便利だが遅いし、変なことも起こりうるので、「なるべく -n でやれ.これは最後の手段にしろ」とマニュアルにはある. |
-h |
人間が読めると思われる数字なら数字として扱ってソートする. 例えば、500 < 1k となる. この機能を持たない sort コマンドもある. |
-M |
対象が「月の略称」になっているとしてソートする. 環境変数 LC_TIME が英語(en)などの場合、'JAN' < 'FEB' < ... ということになる. |
-R |
ランダムソート.重複する同じものはきちんと同じ順序になる. この機能を持たない sort コマンドもある. |
-V |
対象がバージョン番号になっているとしてソートする. この機能を持たない sort コマンドもある. |
-c |
チェックモード(sort は通常はソートモード).データがソート済みかどうかを check する. |
-m |
マージモード(sort は通常はソートモード).個々に既にソートされている複数のファイルの内容をソートしてまとめる. 実は通常のソートモードではこの「個々に既にソートされている」前提が不要なので、このマージモードは機能としては低い. ただし、このモードは「動作が速い」. |
tee 標準入力からもらったデータを「標準出力」と「ファイル」の両方に出力する
上に書いた通り(前回の
パイプの実例
でも紹介した)、標準入力からのデータを標準出力とファイルの両方にコピーして出力する.
なお、通常はファイルは「上書き」されるが、
-a というオプションをつければ「追加出力」になる.
実行例 (1)
1tee d2.txt < d1.txt | less
"d1.txt" ファイルの中身を "d2.txt" にコピーしつつ、画面で内容を確認出来る.
うまく alias と組み合わせての使い途があるかもしれない.
実行例 (2)
1ls -lg | cat -n | tee dummy.txt | less
とすると,出力結果に行番号をつけたうえで,ファイル "dummy.txt" に結果を書込みつつ,同時に画面で確認できる.
tr 「文字」単位での一括変換
入力されたテキストの 「文字」の置換,削除,圧縮を行なう フィルタである. あまり普段使いしないかもしれないフィルタだが、文字統計的な処理にはうってつけだ.

として使う. 基本は「文字」単位での変換であって、「文字列」ではないことに注意しよう.
実行例 (1)
1ls -lg | tr a-z A-Z
で,ls -lg の結果を,a → A, b → B, c → C … z → Z と変換して出力する. つまり,全て大文字に置換する.
実行例 (2)
そこそこ長いテキストファイル "dummy.txt" に対して,
1cat dummy.txt | tr -cd '[:print:]'
とすると,印刷できない文字を全て消去して出力する.
この場合は、「改行」などが削られるだろう.
なお、オプション -cd と 文字クラス [:print:] についてはマニュアルを見ておこう.
実行例 (3)
1cat dummy.txt | tr -s '\n'
とすると,入力中の改行の繰り返しを一つにまとめる. つまり,空行が消去できる.
実行例 (4)
逆に処理しやすくするためにすべての項目をバラバラにすることもできる.例えば
1cal | tr '[:blank:]' '\n'
とすると,cal コマンドの出力がすべて行に分解される.
注意: ubuntu だと cal コマンドがインストールされていないことがある.その場合は,
1sudo apt install ncal
として ncal コマンドをインストールして,cal コマンドの代わりに使おう.
例えば、1年に ○月31日 は 7回あるはずであるが,上の機能を使って次のように確認できる.試してみよう.
1cal 2025 | tr '[:blank:]' '\n' | grep -c 31
実行例 (5)
テキストファイルの改行コードは OS 毎に異なるが、これを変換することができる.
例えば、
1tr -d '\r' < wintext.txt > unixtext.txt
とすると,Windows の改行コードを持つテキストファイル wintext.txt から、Unix の改行コードを持つ unixtext.txt へ変換できる.
注: Windows, Unix, MacOS の3つの OS の改行コードを調べ、それぞれの間での変換を tr や sed を使ってどうやるか考えてみよう.
head, tail 最初/最後の数行を出力
入力データの最初/最後の 数行を出力するフィルタである.
例えば、随時 記録が追加されていくようなファイルの変化をチェックするには,tail が役に立つので覚えておくと良い.
gzip, bzip2, xz,... ファイルの圧縮・解凍
データを 圧縮・解凍・閲覧 するフィルタ.
多くの種類がある.
一般には、コマンドごとに圧縮形式やファイルフォーマットが異なる.
一般に性能の良いと言われている順に、以下に示そう.
| ファイルフォーマット | コマンド群 | 解説 |
|---|---|---|
| xz | xz, lzma など | 圧縮性能がかなり良い.下記のどれよりも「はっきりと」良い.その代わりちょっと遅いが. 比較的最近のコマンド群.LZMA2 法による. |
| bz2 | bzip2 など | gz より高性能. Burrows-Wheeler ブロックソート圧縮+ハフマン符号化. |
| gz | gzip, gunzip など | unix ではかなり標準的なフォーマット. Lempel-Ziv 77 法による. |
| zip | zip など | 一般ではかなり広く用いられている.しかし、性能はあまり良くない. |
| Z | compress, uncompress など | unix で用いられていたかなり古い圧縮形式. 性能も良くなく、今はあまり使われない. |
以下、gzip を用いて、おおよその使い方を例で示そう.
実行例(1)
1gzip dummy.txt
とすると, dummy.txt が圧縮されて dummy.txt.gz になる. ただし,この方法だと dummy.txt は消去される.
実行例(2)
1gzip -k dummy.txt
というように,オプション -k (=keep) をつけると, dummy.txt は消去されずに圧縮されて dummy.txt.gz という新たなファイルができる.
実行例(3)
1ps axu | gzip > dummy.gz
とすると,ps axu の結果が圧縮されて dummy.gz という名前のファイルになる. すぐに使わない結果などはこうして最初から圧縮しておくと保管しやすい.
実習
適当に, 大きなテキストファイルなどを用意して,
圧縮しない場合,
gzip で圧縮した場合,
bzip2 で圧縮した場合,
xz で圧縮した場合、
の結果を比較して,ファイルサイズがどれくらい小さくなっているか(圧縮されているか)実際に比較してみよう.
tar 複数のファイルをまとめて一つに
複数のファイルをまとめて一つのデータに して出力する「アーカイブ機能」をもっているのがこの tar だ(そもそも、Tape ARchive の略である).
もちろん,後で元の複数のファイルに戻せる.
ちなみに、unix の多くの圧縮ツールは(アーカイブ機能はこの tar にまかせることにして)自分ではアーカイブ機能を持っていない.
通常は次のいくつかのオプションだけ覚えておけばいいだろう.
| オプション | 解説 |
|---|---|
cvf |
複数のファイルをひとつにまとめる |
xvf |
tar ファイルを解凍して複数のファイルに戻す |
J |
(上に追加して) xz 圧縮・解凍を使う |
j |
(上に追加して) bzip2 圧縮・解凍を使う |
z |
(上に追加して) gzip 圧縮・解凍を使う |
Z |
(上に追加して) compress 圧縮・解凍を使う |
実行例(1)
例えば,そこにあるディレクトリ "data" をまるごと1つのファイル result.tar にしたい時は,
1tar cvf result.tar data
とすればよい.
ちなみに tar は圧縮はしないので,圧縮したければ上の gzip や bzip2 をこのまとめた結果に対して使えば良い.
また,こうしてできた result.tar というファイルを解凍したい場合は,
1tar xvf result.tar
とすればよい.
実行例(2)
tar をフィルタとして使う面白い応用として,
複数のファイルをディレクトリの構造ごと「移動」させる例がある.
1tar cf - -C ディレクトリA . | tar xpf - -C ディレクトリB
とすると,ディレクトリA の中身をそのままディレクトリ B へコピーできる(-C は change directory オプション).
さらにこのパイプの間に
rsh など
を挟めばネットワークを越えてディレクトリの構造をコピーできる.
cut 入力データを要素ごとに分解して取り扱う
区切られたデータが連なる入力に対して,区切られたデータを抜き出す フィルタで、 その意味では awk と似ているが,awk より融通が効かない. 続いているスペースは一つの空白とみなさず、空っぽの要素が間に挟まっているという機械的な処理をしてしまう.
実行例
1ps axu | cut -f 2,11 -d " "
とすると,「区切り文字 = スペース」として 2番目と11番目の項目を出力してくれるのだが, 上の awk の例と比較すると,「融通が効かない」という意味がわかるだろう.
実習
上に示した実例を実際に行い,何が起きているのかよく理解せよ.
正規表現 補足
正規表現のオンラインマニュアルを読むなら、コマンドは以下の通り.
| 正規表現のオンラインマニュアル | 解説 |
|---|---|
man 7 regex |
Linux の場合 |
man re_format |
FreeBSD の場合 |
| 基本 正規表現 | 拡張 正規表現 | 意味 |
|---|---|---|
| 通常文字 | 同左 | メタキャラクタでない文字. その文字自身を表す. |
| \ ^ $ . [ ] * | \ ^ $ . [ ] * + ? { } ( ) ¦ | メタキャラクタ. 意味はそれぞれ下記を見よ. |
| \m | 同左 | メタキャラクタ m の意味を打消し,通常文字として扱う(エスケープという). |
| ^ | 同左 | 行頭を表す. |
| $ | 同左 | 行末を表す. |
| . (ピリオド) | 同左 | 任意の一文字を表す. |
| [ ] | 同左 | [ ] で囲まれた文字列中のどれか一文字を表す. [ ] 中では特別に "-" のみがメタキャラクタとなり, 他のメタキャラクタは通常文字として扱われる. "-" を通常キャラクタとして扱うには, "---" (ハイフンを三つ繋げる) と書けばよい. |
| [ c1 - c2 ] | 同左 | 文字 c1 から c2 までの範囲の文字中のどれか一文字を表す. |
| [^ ] | 同左 | [^ ] で囲まれた文字列中に「含まれない」一文字を表す. |
| * | 同左 | 直前の正規表現の 0 回以上の繰り返しを表す. |
| (該当無し) | + | 直前の正規表現の 1 回以上の繰り返しを表す. |
| (該当無し) | ? | 直前の正規表現が 0 回か 1回現れることを表す. |
| \{ m \} | { m } | 直前の正規表現の m 回の繰り返しを表す. |
| \{ m, \} | { m, } | 直前の正規表現の m 回以上の繰り返しを表す. |
| \{m, n\} | {m, n} | 直前の正規表現の m 回以上 n 回以下の繰り返しを表す. |
| \( \) | ( ) | 囲まれた部分をグループ化する. |
| \N | 同左 | N 番目のグループ化された正規表現が合致した結果(N= 1,2,..9). |
| (該当無し) | ¦ | 直前と直後の正規表現の「どちらか」を表す |
GNU ソフトウェアでは、通常の正規表現に加えて以下のような拡張も追加されている.
| GNU拡張 | 意味 |
|---|---|
| \< | 単語の先頭を表す. |
| \> | 単語の末尾を表す. |
| \b | 単語の先頭か末尾を表す. |
| \B | 単語の(先頭か末尾)以外を表す. |
プログラマブル フィルタ
単機能フィルタでは少々荷が重い複雑なフィルタ処理を行なうには, そのままでは, シェルスクリプトを作成するか, 通常言語でプログラムを組むなどの行為が必要となる.
しかし,シェルスクリプトは制限が強すぎて柔軟な処理は難しいし, 通常言語でフィルタの内容をプログラムするのは無駄が多い.
そこで,フィルタプログラム自身が複雑なフィルタ処理をプログラムできれば, フィルタの便利な機能を生かしつつ,無駄無く複雑な処理が柔軟にできるというものだ. これが「プログラミング可能な」フィルタの存在意義である.
こうしたプログラミング可能なフィルタプログラムとしては, sed, awk, perl, ruby 等が有名である. 本講義では, sed についてまず簡単に解説する.
sed 1行ずつ、正規表現に基づいて文字列を置換する
sed は 1 行ずつ 高速 かつ 正規表現の使える文字列置換ツール (フィルタ)である. フィルタとしては

というように用いる.
ここでいう「スクリプト」とは,sed の動作を指定するために我々がこれから作るプログラムのことである.
オプション -n についてはすぐあとで学ぶ.
動作としては、sed は入力を一行ずつ処理していく.
つまり,処理単位は「行」である.
そして,sed のスクリプトは基本的に,
1 処理対象となる行の指定 {
2 コマンド
3 コマンド
4 コマンド
5 コマンド
6 }
という構造をしている.
なお、コマンドが一つしかない場合は { } は省略してもよい.
さらに、対象行の指定が不要である(つまり,全ての入力行を対象とする)場合は,
1 コマンド
2 コマンド
3 コマンド
4 コマンド
とコマンドだけを書き連ねてもよい.
そして,このスクリプトに従って、sed は基本的に
- 処理対象となる行には… 全てのコマンドを適用してから,
- 対象外の行には…なにもしないでそのままにして,
どちらにせよ結果を出力する.
ただし,起動時にオプション -n をつけた場合,「出力を命令(p フラグか p コマンド)されたとき以外は」出力しなくなる.
よって、
「処理された結果のみを見たい 場合は,-n オプションと,p フラグか p コマンドを使う」
と覚えておけば大丈夫だろう.
そして、処理対象となる行を指定する方法は,
| 対象行の指定文法 | 解説 |
|---|---|
| 行番号 | 10 と書いたら 10行目のこと. |
| /正規表現/ | その正規表現を「含む」行(複数ありうる). |
| $ | 最終行. |
の 3通り.
ただし,10, /win/ のように二つの指定を ,(カンマ) で繋げて書いた場合には,10行目から win を含む行まで という範囲指定になる.
そして、sed のスクリプト中に書き込むコマンドは以下の通り.
| コマンド | 意味 |
|---|---|
| s/元パターン/置換新パターン/フラグ | 元パターン(正規表現可) に合致する文字列を新パターンで置き換える. 置換新パターン中には,特別に & というメタキャラクタも使える. これは置換元パターンに合致した文字列そのもの,を表す. フラグは以下の通り. g … 行内の該当する文字列を「全て」置換. N … 行内の該当する文字列の「N 番目」を置換. p … 置換が行なわれたならば「表示」. |
| p | その行を必ず表示する. |
| d | その行を削除する. |
| q | sed そのものを終了する. |
実行例 (1)
1ps axu | sed -e 's/daemon/WhoAreYou?/g' | less
とすると… 何が起こるか?
実行例 (2)
さらに,
1ps axu | sed -n -e 's/daemon/WhoAreYou?/gp' | less
とすると,上より分かりやすい.
実行例 (3)
たくさんあるファイルの名前を,一斉に機械的に変更したい.
例えば,*.text というファイルをすべて *.txt というファイル名に変更したいとする.
すると
1\ls *.text | sed -n -e 's/\(.*\).text$/mv & \1.txt/gp'
とすると,「その変更操作のための下準備」ができる.
具体的には,例えば a.text, b.text, c.text, ... というファイルがある
状態でこのコマンドを打つと,
1 mv a.text a.txt
2 mv b.text b.txt
3 mv c.text c.txt
という結果が得られる( ここでは念の為に ls の頭に \ をつけている).
さて,あとはこの「結果」をシェルスクリプトにしてもよいし,シェルそのものに渡しても良い. 例えば,
1\ls *.text | sed -n -e 's/\(.*\).text$/mv & \1.txt/gp' | sh
などとすると,一斉にファイル名を希望通りに変更できる.
実習: 実習用にディレクトリを用意し,その中に実習用のファイルを幾つか作って,上の例を試してみよう.
レポート No.5
注意
近年はセキュリティ上の懸念から,実行形式のプログラムなどをメールに添付するとそのメールそのものの受信を受信側サーバが拒絶したりする.
そういうことを避けるため,レポートをファイルで提出するときはそういった懸念のあるファイル形式のものではないようにしよう.
まあ要するに,レポートは pdf ファイルにして送るのが良い ということだと思っておこう.
以下の課題について、自らの将来のスキルアップに繋がるように調査と考察を行い,
学籍番号-氏名-05.pdf
というファイルとしてレポートを作成し、
webフォーム
から教官宛に提出しよう.
なお,レポートを $\TeX$ 等で作成したものを印刷した「紙媒体」を教官に直接手渡す形で提出してもよいが、物質によるレポート提出は常に破損や紛失の可能性があるのであまりお勧めはしないぞ.
課題
-
あるファイルの中身の行頭全てに " > " という一文字を付け加えたい. どうすればよいだろうか. 手順を詳しく解説せよ.
-
Tsushima か Tsusima Tushima か Tusima か,という文字列を含む行をデータの中から探すにはどうしたらよいだろうか. 手順を詳しく解説せよ.
-
あるファイル中で,年月日が全て
2026.05.18というような形式で記述されている. これを全て18/May/2026という形式に修正したいが,どうすればよいか. 手順を詳しく解説せよ.
なおもちろん、 1月は Jan. に,2月は Feb. に… と12ヶ月全ての月表示についてうまくいくようにして欲しい. -
上で「Zipf の法則について,阪大総長の英文挨拶でどうなるか試してみた」ことを解説したが,これを別の英文を対象として行い、top 10 の単語やその登場回数等について報告せよ.
対象の英文は自分で探してもらいたいが,どうしても見つからない人は,例えば- BBC blog Front Row Late returns with lights, mics, webcams and A-list names
- Wikipedia の英語版の記事 Unix
などを対象としてみても良い.
- 余裕のある人向け:
正規表現クロスワード の "Challenges" や RegEx Crosswgrd に取り組んでみよう.自力で解を得られたらスクリーンショットをレポートに貼り付ければ良い.後者はまあちょっと大変だが…