06. プログラム可能なフィルタ
 Photo by Anne Nygård on Unsplash
Photo by Anne Nygård on Unsplash
今回の授業の概要と目標
前回は単機能なフィルタを中心に学んだ.
今回は、複雑な動作が可能な「プログラミングが可能な」フィルタについて学ぼう.
今回の授業では、その基本とも言える awk について学ぶ.
到達目標は以下のようになるだろう.
- プログラム指示を与えた awk を単体で起動できる
- プログラム指示を与えた awk をフィルタとして使える
- awk のレコードとフィールドを理解できる
- awk の持つ文字列処理コマンドと演算コマンドを知る
- awk の制御構造を使える
- awk の連想配列を使える
- スクリプトファイルのコマンド化を理解し、実際に適用できる
awk: データ処理専用? フィルタ
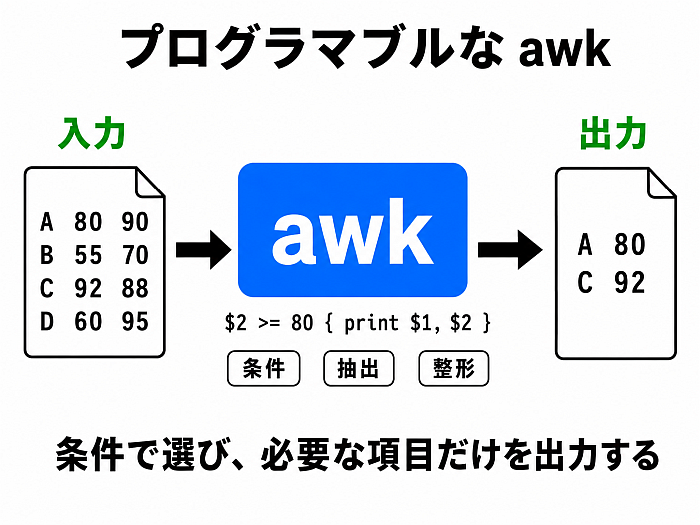
awk はプログラム指示を与えて動かせるコマンドで、
- 行を読み込み、
- 中身を分割し、
- 処理を施す
という作業に向いた設計である. 比較的簡単にプログラムでき、フィルタを作るのに向いているツール1と言えよう.
[使い方]
まず、awk の起動方法には次の 3種類がある。
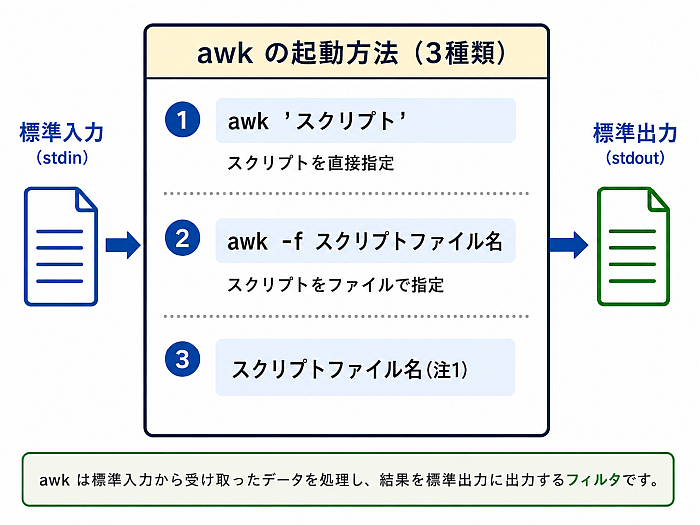
注1. このあとで学ぶ スクリプトファイルのコマンド化 を利用するものである.
注2. 「スクリプト」とは動作指示書, すなわち,プログラムのことである.
(起動方法の使い分け)
下記の具体例を通じておおよそわかってくるとは思うが、起動方法は下記のように使い分けることになるだろう.
awkへの指示(スクリプト)が短い場合は ❶awk 'スクリプト'の方法が良い.- 指示(スクリプト)が長い場合は ❷
awk -f スクリプトファイル名がお勧めだ. - ❸ はちょっと特殊だ.今回の授業の後半で スクリプトファイルのコマンド化 として学ぶのでそこまで待とう.
これら3つの起動方法をまとめて awk_launch と書くとして、使い方は以下のようになる.
- (フィルタとしての使い方)
コマンド | awk_launchとすると、コマンドの出力に指示(スクリプト)された処理を加えて出力する awk_launch ファイル名とすると、ファイルの中身に指示(スクリプト)された処理を加えて出力する- ファイル名を与えてないときや,ファイル名として "-" (ハイフン)を与えたときは、標準入力を読込んで出力する.
前回も機能を限定した形で awk を使ったが、いまいちど、感覚を掴むために下記の実行例を見ておこう.
実行例 1: (行の中の)データを切り分けて扱う
カレンダーコマンド ncal (インストールしてない人はインストールしておこう) を用いて、今月の木曜日のリストを得たい、という場合は awk を用いて以下のようにすれば良い.
1ncal -b | awk '{print $5}'
2 # ncal の旧式表記(馴染みの表記)の第5要素(木曜日) を取り出す.
3 # スクリプト {print $5} が短いので、awk を ❶ の方法で起動している
2026年5月時点だと、次のような結果が得られるはずだ.
Th
7
14
21
28
実習: 上の実行例を自分で行ってみよう.
awk スクリプトの形
awk は sed 同様,入力を一行ずつ処理していく.
つまり,処理単位は「行」である.
そして,awk のスクリプトは基本的に,

という構造をしている.
注: 上の実行例 1 のスクリプト {print $5} を上の図に照らして解説すると、
- BEGIN 行は無し
- 途中の
条件 {}という行が1行だけあり、しかも、その条件は書かれていない.{}の部分だけがあり、コマンドが一つだけprint $5と書かれている. - END 行は無し
という形をしている.
以下、これを少しずつ詳しく説明しよう.
スクリプトの中の条件とコマンド部分
上のスクリプトの図中に、条件 という箇所と コマンド;コマンド;... という箇所がある.
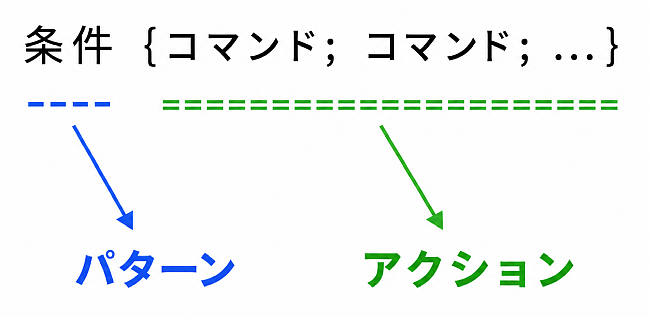
これらの awk の世界での意味(と名称)を紹介しよう.
| 該当箇所の概念等 | 解説 |
|---|---|
| 条件 (名称: パターン) |
上の図の「条件」部分. 処理対象となる行を指定する条件のこと. 省略可. 省略した場合、「無条件にそのデータを対象として、アクションを行う」. |
| 処理 (名称: アクション) |
上の図の「コマンド;コマンド;…」という部分. 対象行に対する一連の処理のこと. なお、コマンドとコマンドを区切る部分にセミコロン ; を使う代わりに改行をしても良い. |
これらがどう動作に係るかは、次の説明を読もう.
スクリプトによる awk の動作
スクリプトを与えると awk は次のように動作する.
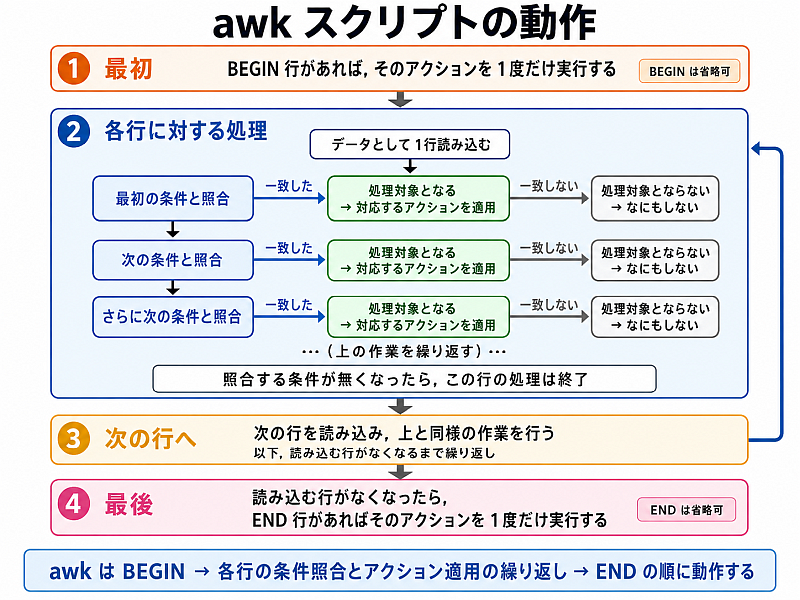
注: 上の実行例 1 のスクリプト {print $5} による動作を上の図に照らして解説すると、
❶ スクリプトに BEGIN 行がないのでスキップして次へ.
❷ 条件がある場合は { の左に書く約束だが、{print $5} では条件が省略されている.
「条件が省略されている ⇛ 無条件でアクションを実行する」ルールにより、読み込んだデータに対してアクション print $5 が実行される.
❸ 次の行を読み込もうとするが、もう無いので ❹ へすすむ.
❹ スクリプトに END 行がないのでスキップ.そのまま終了.
ということになる.
実行例 2: 上のステップ ❷ を例で理解する
上のステップ ❷ の中の繰り返しの意味がつかみにくい人は,以下の例を見てみよう. 同じデータ行に対して、2つのアクションを用意するとどうなるか、という例だ.
-
test.awk という名前のテキストファイルを用意する. ただし、このファイルの中身は下記のようにする.
1{ print $1,$2,$3 } 2{ print $1,$2,$3,$4 } -
下記のように
awkを動かす.1echo "a b c d" | awk -f test.awk -
すると、
a b c a b c dという結果が得られる. 1つのデータ行に対して,2つのアクションが行われたことが分かる.
実習: 上の実行例を自分で行ってみよう.
条件(パターン) 指定の方法
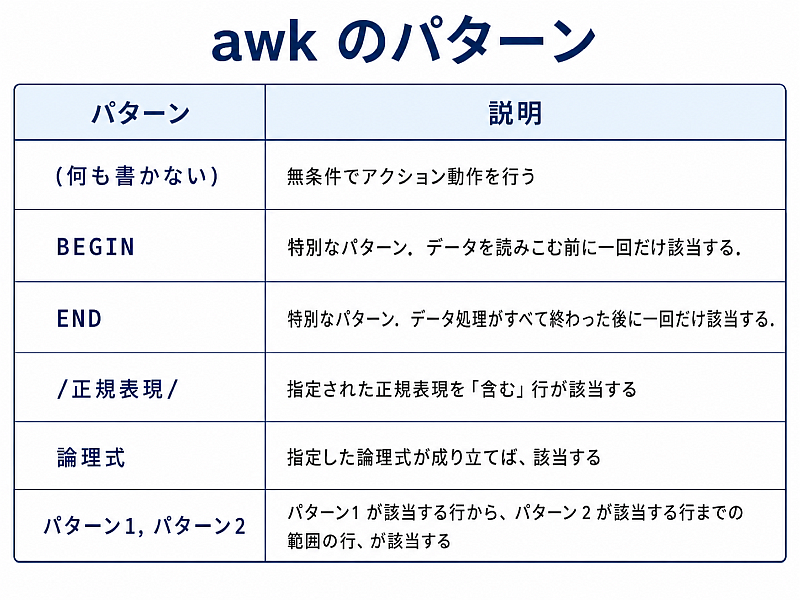
awk のパターンは、まあ普通は以下の6種類と思えば良い.正規表現以外はごく素直なので簡単だ.
awk が行をどう分解するか
awk は読み込んだ行を複数のデータに分解する.
このルールと各種用語を知っておこう.図にすると下の図のようになる.
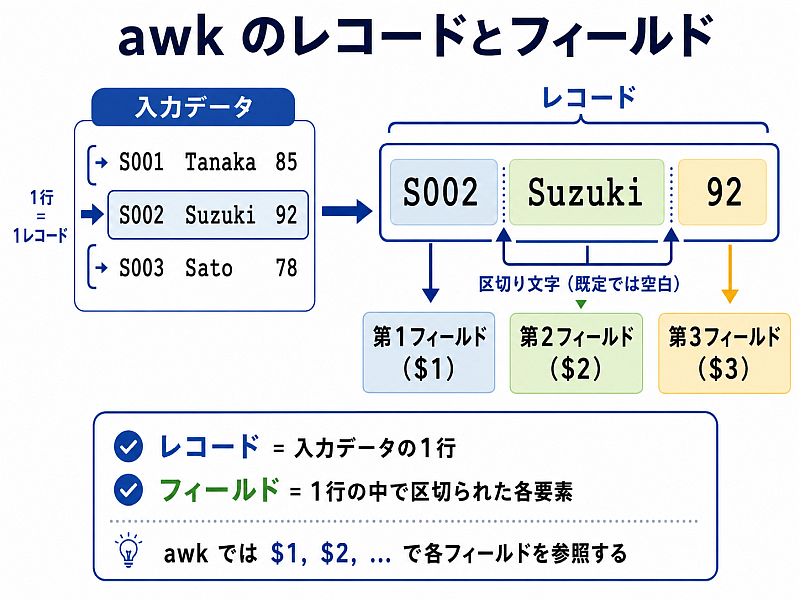
フィールド $0 は特別に全てのフィールド、つまり、レコードを指す。
レコードをフィールドに分解する時の「区切り」は,デフォルトでは「空白(連続しても良い)」である. これは変更可能で、以下の二つの方法がある.
- 起動時に -F オプションで指定する.
- プログラム中で FS という変数で指定する.
区切り文字の変更を下記の実行例で見てみよう.
実行例 3: awk の区切り文字を変えてみる
-
まず、区切り文字をデフォルトの 空白 から変えてない状況を確認する.
1ncal -b 2 # まず、もとのカレンダー表記.2026年5月時点では出力は以下のとおり.
May 2026 Su Mo Tu We Th Fr Sa 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31これに対し、まずは
awkを普通に適用する.1ncal -b | awk '{print $2,$3}' 2 # 空白区切りでの 第2要素、第3要素 を抜き出す出力は以下のようになるだろう.
2026 Mo Tu 2 4 5 11 12 18 19 25 26 -
次に、起動時オプション
-Fを使う方法で、区切り文字を 2 にしてみる.1ncal -b | awk -F '2' '{print $2,$3}' 2 # 文字「2」区切りでの 第2要素、第3要素 を抜き出す出力は以下のようになる.確かに文字「2」で区切られてこうなっていることを、先のもとの
ncal -bの出力と照らし合わせて確認しよう.0 6 13 14 15 16 0 1 4 5 -
次に、スクリプト内部で変数
FSを指定する方法で区切り文字を 1 にしてみよう.1ncal -b | awk 'BEGIN{FS="1"}{print $2,$3}' 2 # 文字「1」区切りでの 第2要素、第3要素 を抜き出す注意: BEGIN をうまく使っていることに注意しよう.
出力は以下のようになる.やはり確かに文字「1」で区切られてこうなっていることを、同様に照らし合わせて確認しよう.
2 0 _ 7 8
これをまずやってみよう. また,他の区切り文字もいろいろ試してみよう.
実習: 上の実行例を自分で行ってみよう.
スクリプト指示に必要そうな知識: 1. 特別な変数
既に紹介した変数 FS の他にも、使えそうな変数があるので下記に列挙しておいた.
| 変数 | 説明 |
|---|---|
| FS | 入力レコードをフィールドに分解するときに使う区切り文字. |
| NF | 現在のレコードのフィールド数. |
| NR | その時点での全レコード数. 要するに,そこまで読み込んだ入力データの行数. |
実行例 4: 特別な変数 NF, NR を使ってみる
-
まず、もとのデータを確認.
1ncal -b 2 # まず、もとのカレンダー表記.2026年5月時点では出力は以下のとおり.
May 2026 Su Mo Tu We Th Fr Sa 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 -
変数 NF を参照してみる.
1ncal -b | awk '{print NF}' 2 # もとのカレンダー表記の各行のフィールド数が出るはずだ出力は以下のとおり.もとのデータと比べて確かめよう.
2 7 2 7 7 7 7 1 -
変数 NR も参照してみる.
1ncal -b | awk '{print NF,NR}' 2 # もとのカレンダー表記の各行のフィールド数と、そこまでのレコード数が出るはずだ 3 # そこまでのレコード数は、結局はデータの行番号と一致するはず…出力は以下のとおり.これももとのデータと比べて確かめよう.
2 1 7 2 2 3 7 4 7 5 7 6 7 7 1 8
実習: 上の実行例を自分で行ってみよう.
スクリプト指示に必要そうな知識: 2. 判定・演算系機能
四則演算を含め、パターンやアクションの中で使えそうな判定・演算系機能があるので下記に列挙しておいた.
| 記号 | 機能、解説 |
|---|---|
| + - * / ^ % | 四則演算、べき乗、剰余。 |
| == != < > <= >= | 同値、非同値、より小さい、より大きい、以下、以上。 (注) 最初の記号は"=" が二つつながっている。 |
| = | 代入. (注) 記号は"=" が一つ. 同値と違うので注意. |
| ! && ¦¦ | NOT AND OR |
| ~ !~ | 正規表現マッチ、否定のマッチ。 |
| exp, cos, sin, log, sqrt | ごく普通の関数. |
実行例 5: 判定・演算系機能を使ってみる
-
まず、もとのデータを確認.
1ncal -b 2 # まず、もとのカレンダー表記.2026年5月時点では出力は以下のとおり.
May 2026 Su Mo Tu We Th Fr Sa 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 -
水曜日で10日以降、という条件を満たす日を出力してみる
1ncal -b | awk '$4> = 10{print $4}' 2 # そういう条件を設定してみた出力は以下のとおり.もとのデータと比べて確かめよう.
We ← 注意! 下記に詳細を記載した. 13 20 27注意:
awkは数字と文字列を比較する際、数字を文字列として扱い、辞書式順序で比べる. コンピュータの中では文字 "1" は文字 "W" より前にあるので、 "10" < "We" という扱いになってこの判定が成立してしまい、"We" が出力されている. -
その条件に合う日付を √ 計算に入れてみる
1ncal -b | awk '$4> = 10{print sqrt($4)}' 2 # 日付を√計算…出力は以下のとおり.これももとのデータと比べて確かめよう.
0 ← 注意! 下記に詳細を記載した. 3.60555 4.47214 5.19615注意:
awkは、sqrt計算など数値が期待されるところに文字列(今回は "We")が来ると、 この文字列を左から読んでいってなんとか数字で解釈しようとする. 例えば "123We" という文字列は 123 という数字に解釈される. どうしても数字に解釈できない場合は、なんとも乱暴なことに強引に 0 に解釈する. 今回はこの機能が働いて "We" が 0 に解釈され、sqrt(0) の結果が出力されている. -
土曜日で、日付に 1 か 3 を含む日を探す
1ncal -b | awk '$7 ~ /1|3/{print $7}' 2 # 正規表現を使ってみた出力は以下のとおり.これももとのデータと比べて確かめよう.
16 23 30
実習: 上の実行例を自分で行ってみよう.
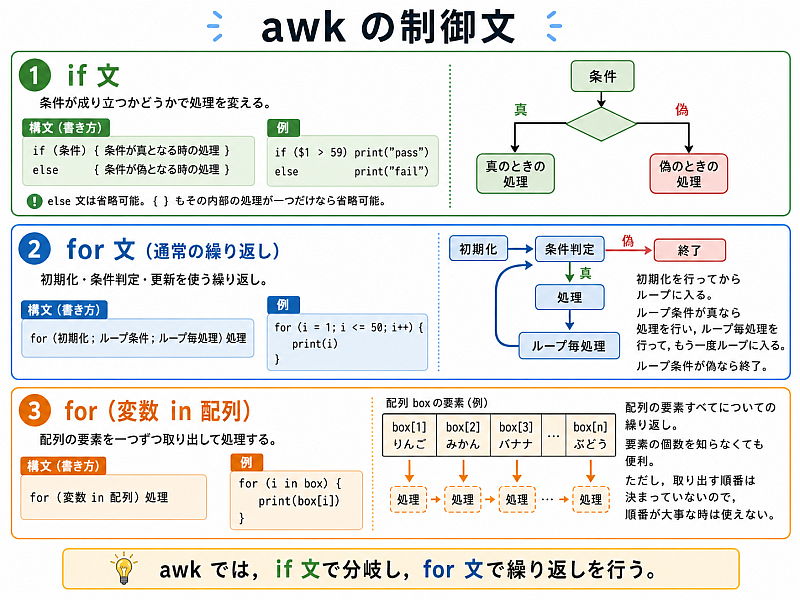
スクリプト指示に必要そうな知識: 3. 制御構造
スクリプトで場合分けや繰り返しができると便利だ. そういうときはこれだ.
実行例 6: 制御構造を使ってみる
制御構造は例を見たほうがわかりやすいだろう.
-
準備.score.txt というファイル名でテキストファイルを作り、内容を下記のようにしよう.
Alice 80 Bob 55 Carol 92 Dave 68 Ellen 74 -
awk のアクションの中で if 文 を使ってみる.
1cat score.txt | awk '{ 2 if ($2 >= 60) print($0, "pass") 3 else print($0, "fail") 4}' 5 6 # 点数が 60点以上ならば pass と表示を追加し、そうでなければ fail と追加する注意:
awk 'スクリプト'形式で awk を使う場合も、スクリプトは 1行で書く必要はない.結果は以下のようになる.
Alice 80 pass Bob 55 fail Carol 92 pass Dave 68 pass Ellen 74 pass -
awk のアクションの中で通常の for 文 を使ってみる.
1cat score.txt | awk '{ 2 for (i = 1; i <= NF; i++) { 3 print "field", i, "=", $i 4 } 5 print "---" 6}' 7 8 # 各要素ごとに "field 要素番号 = データ" という表記を行う.下記のような出力になるはずだ.
field 1 = Alice field 2 = 80 --- field 1 = Bob field 2 = 55 --- field 1 = Carol field 2 = 92 --- field 1 = Dave field 2 = 68 --- field 1 = Ellen field 2 = 74 --- -
awk のアクションの中で配列の中身を取り出す for 文 を使ってみる.
1echo "apple orange banana grape" | awk '{ 2 for (i = 1; i <= NF; i++) { 3 fruit[i] = $i 4 } 5 6 for (i in fruit){ 7 print("fruit[" i "] = ", fruit[i]) 8 } 9}' 10 11 # 最初の for 文は通常のもの. 12 # 2つめの for 文で fruit 配列から要素 i をすべて取り出して処理している下記のような出力になるはずだ.
fruit[1] = apple fruit[2] = orange fruit[3] = banana fruit[4] = grape
実習: 上の実行例を自分で行ってみよう.
スクリプト指示に必要そうな知識: 4. 連想配列
awk の面白いところは「連想配列」が使えるところだ2.

まず、配列とは多変数をつなげて一つにしたもので,ベクトルのようなものと思えば良い.そして、 普通の配列は各要素はその要素番号で指定するが、 連想配列は各要素に「文字列で」名前を付け、その名前で指定するようになっている.
上の例で「色」と「動物」がペアになっていて連想配列が便利に使えているように、
ペアになっているような情報の処理には大変に便利
なのでぜひ習得しておこう.
実行例 7: 連想配列の強力さを味わう
上の例でも使用した score.txt をデータとして読み込むことを考えよう.
まず比較のために、これを普通の配列でやろうとすると、
1cat score.txt | awk '{
2 name[NR-1]=$1 # 配列 name に氏名を(追加で)格納.
3 score[NR-1]=$2 # 配列 size に点数を(追加で)格納.
4 }
5 END{ for (i=0;i<NR;i=i+1) print("The score of", name[i], "is", score[i]) }'
6
7 # i を 0 から NR-1 まで動かし,name[i] と score[i] を出力.
などとなるだろう.出力は以下のとおりだ.
The score of Alice is 80
The score of Bob is 55
The score of Carol is 92
The score of Dave is 68
The score of Ellen is 74
このスクリプトをみると、
関連する情報を処理するのにわざわざ二つの異なる配列を用意しないといけない
ため、プログラムの中でデータの関連性が失われていることに注意しよう. これは、本来は不要な添字の数字を使うことなどにつながってしまっていて、無駄やバグの温床となっており、いろいろとまずい.
一方,連想配列を用いるならば、このケースでは作る配列は一つだけで済む.下記のようになるだろう.
1cat score.txt | awk '{
2 score[$1]=$2
3 }
4 END{ for (name in score) print("The score of", name, "is", score[name]) }'
5
6 # まず、全データを使って、添字を氏名にした連想配列 score を作る.
7 # 最後に、配列 score の添字を name として,すべての name と score[name] を出力.
出力は以下のような感じだ.
The score of Dave is 68
The score of Carol is 92
The score of Bob is 55
The score of Alice is 80
The score of Ellen is 74
連想配列を使っていない場合と比較すると、プログラムの論理に無駄がなくなり,分かりやすく,間違えにくくなっている ことに注目しよう.
実習: 上の実行例を自分で行ってみよう.
スクリプトファイルのコマンド化
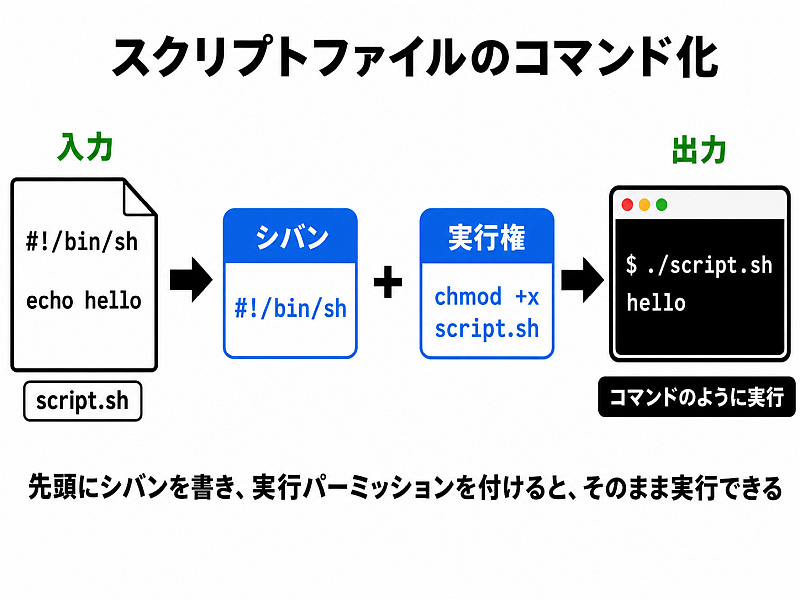
Unix では自分でコマンドを作る方法が豊富に用意されており、その一つが
awk + スクリプト のような組み合わせを一つのコマンドのように見せるテクニック
である. 複雑な処理をコマンド一つで呼び出せるように でき、とても便利だ.
スクリプトファイルをコマンド化するということの意味
さて、これがどういうことなのか考えてみよう. 例えてみると次のような図で表せる。
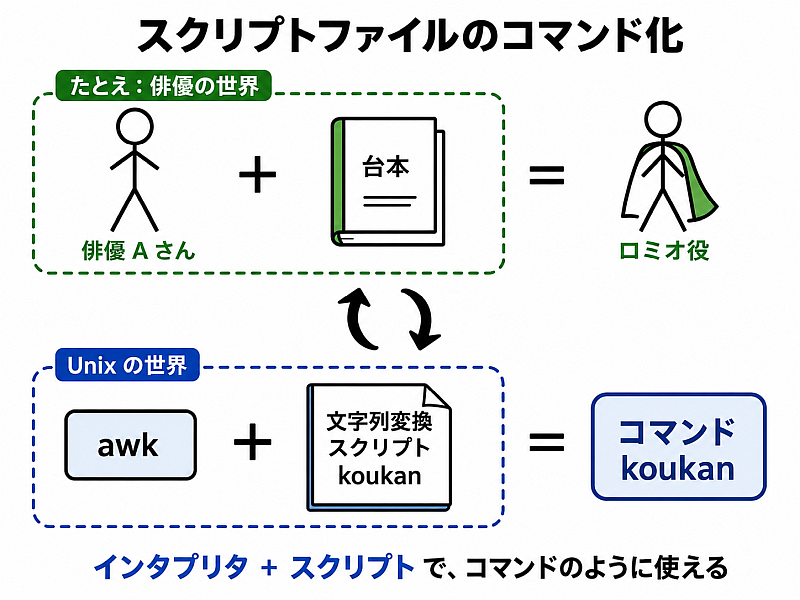
スクリプトをコマンド化する具体的な方法
このテクニックでやるべきことは以下の二つだけだ.
ステップ ❶. 「シバン」をスクリプトに記入する.
これは、スクリプトファイルの先頭行に、そのスクリプトファイルを呼び出すコマンドを
#!コマンドファイル名 (と必要なオプション)
という 1行で書き込むことを指す.具体的には下記の実行例を見てほしい.
ちなみに、この 1行をシバン(shebang)というのだ.
実行例 8: シバンの記入
まず、コマンドファイルの「在り処」を把握する必要がある.
そこで、コマンドファイルの在り処を調べる which コマンドを用いて、
たとえば awk の場合は
1which awk
とする. すると、
/usr/bin/awk
か
/bin/awk
とコマンドファイルの在り処が返ってくる.
そして、この「在り処」を(コマンドのオプション込みで)スクリプトファイルの先頭行を追加して、#! という2文字を前につけて書き込めば良い.
例えば awk の実体ファイルの在り処が /usr/bin/awk な場合は,
対象のスクリプトファイルの先頭に1行追加してその行に
#!/usr/bin/awk -f
と書きこめばよい.
コマンドの実体の場所は環境によって異なる.必ず which で調べてから書き込もう.
awk の場合、オプション -f は重要だ.忘れないように.
ステップ ❷. スクリプトファイルに,「実行してよい」と許可を出しておく.
Unix のファイルには一般に、読み出しの許可、書き込みの許可、実行の許可について設定ができる. そして通常は、実行の許可は設定されていない. そこでこれを許可しておくのだ.この許可は一回だけ出せば良い.
具体的には、chmod u+x スクリプトファイル名 とすれば良い.
実行例 9: wcもどきのコマンドを作ろう
準備ステップ. たとえば、ファイル wc-pseudo というテキストファイルを新たに作成し、 その中身を下記のようにする.
1{ word = word + NF }
2END{ print NR, word }
3
4 # データをもらうたびに、そのデータ行のフィールド数を変数 word に足し込み、
5 # 最後に行数と全フィールド数を出力する.
ステップ ❶. 上で用意したファイルに シバン を先頭行として追加し、以下のように修正する.
1#!/usr/bin/awk -f
2{ word = word + NF }
3END{ print NR, word }
4
5 # シバン を書き足した.
ステップ ❷. 実行許可を設定する.具体的には、この wc-pseudo ファイルのある場所で、下記のように実行する.
1chmod u+x wc-pseudo
事後ステップ.動かしてみよう!
これまでも使ってきた score.txt を対象にして、下記のように実行してみる.
1cat score.txt | ./wc-pseudo
と実行する3と、
5 10
という出力が得られ、score.txt は 5行あり、10個の単語が含まれていることを示している.
ためしに、本家である wc コマンドを使って
1cat score.txt | wc
とすると、
5 10 50
という出力が得られ、wc-pseudo が wc の真似をうまくできていることがわかる.
実行例 10: これまでにない機能を持つコマンドを作る
入力されたデータの最初の項目の数字をどんどん合計してその平均を出すコマンド average を作ってみよう. 具体的には,
1#!/usr/bin/awk -f
2{ sum=sum+$1 }
3END{ print sum/NR, sum, NR }
4
5 # それぞれの行の最初の数字を読み、それを変数 sum に足していく.
6 # 最後に、合計/行数, 合計, 行数 の3つの数字を出力.
という中身のテキストファイル average を作り、その後、chmod u+x average として実行許可を出しておけば良い.
そして,たとえば dummy.dat というファイルを
11.0
210.0
33.2
45.3
54.0
61.8
という中身で用意して,
1cat dummy.dat | ./average
とすれば,
14.21667 25.3 6
として,平均,合計,総数 が出力されるはずだ.
実習
- 上の実行例 9 および実行例 10 を実行してみよう.
- 実行例 10 を参考にして,平均ではなく 分散を計算 して出力するコマンドを作ろう.
発展・補足編
基本編の内容に対する、発展・補足的な内容を以下に述べる.
学習初期においては無視しても良い内容として、授業時も解説を省略する予定である.
簡単な文法: 文字列操作
awk のアクション中で用いる、文字列を操作する主なコマンドを紹介しておこう.
| コマンド | 解説 |
|---|---|
| gsub(r, s) | 正規表現 r にマッチする部分を全て s に変換。 |
| index(s, t) | 文字列 s 中に含まれる文字列 t の位置。 |
| length(s) | 文字列 s の長さ。 |
| match(s, r) | 文字列 s 中で正規表現 r にマッチする位置。 |
| split(s, a [, r]) | 文字列 s を正規表現 r を用いて分割して配列 a に入れる。 r を省略すると FS を用いる(つまり、フィールド分割と同じになる)。 |
| substr(s, i, [,n]) | 文字列 s の i 番目から最大 n 文字の(部分)文字列を返す。 |
| tolower(str) | 文字列 str の小文字化。 |
| toupper(str) | 文字列 str の大文字化。 |
スクリプト指示に必要そうな知識: 1. 特別な変数 (補足)
| 変数 | 説明 |
|---|---|
| ARGC | awk 起動時の引数の個数. 起動プログラム自身の名前も含むので,必ず 1以上となる. |
| ARGV | awk 起動時の引数を並べた配列. n 番目の引数は,ARGV[n-1] . よって,引数は ARGV[0] から ARGV[ARGC-1] まであることになる. また,1番目の引数,つまり ARGV[0] はコマンド自身の名前になる. |
スクリプト指示に必要そうな知識: 2. 判定・演算系機能 (補足)
| 記号 | 機能、解説 |
|---|---|
| in | 配列に属する。 |
| atan2(y, x) | y/x の逆 sin 関数. |
| int(式), rand() | 整数への切り捨て,乱数(0〜1 の間) |
レポート No.6
注意
近年はセキュリティ上の懸念から,実行形式のプログラムなどをメールに添付するとそのメールそのものの受信を受信側サーバが拒絶したりする.
そういうことを避けるため,レポートをファイルで提出するときはそういった懸念のあるファイル形式のものではないようにしよう.
まあ要するに,レポートは pdf ファイルにして送るのが良い ということだと思っておこう.
以下の課題について、自らの将来のスキルアップに繋がるように調査と考察を行い,
学籍番号-氏名-06.pdf
というファイルとしてレポートを作成し、
webフォーム
から教官宛に提出しよう.
なお,レポートを $\TeX$ 等で作成したものを印刷した「紙媒体」を教官に直接手渡す形で提出してもよいが、物質によるレポート提出は常に破損や紛失の可能性があるのであまりお勧めはしないぞ.
課題
- 実行例10を参考に、データの平均と分散をの両方を出力するコマンドを作成し、その中身を提示し、解説せよ.
そして、適当なデータファイルを新たに作り,それに対して作成したコマンドが正しく結果を返すことを示せ.
- その月の最終木曜日をもとめる awk スクリプトを作成し、その中身を提示し、解説せよ.
また、動作状況の様子を報告せよ.
ただし,入力データとして
ncal -bの出力を想定する. - osaka 130.003.125.224 のように,単語のあとに、3桁の数字列が4つ、ピリオドで繋がる文字列がある.
こういう入力データを,数字の部分だけ前後引っくり返して
osaka 224.125.003.130 と出力するように awk スクリプトを作成し、その中身を提示し、解説せよ.
また、適当な入力に対して実際に正しい出力を返すことを確認し,報告せよ.
なお,awk スクリプトの作成がうまくいかないが複数のスクリプトを用意してそれをパイプなどで繋ぐ等の方法でならば問題を解けるという場合はそれでも良い.