13. AI技術: Support Vector Machine 入門
 Photo by Craig Whitehead on Unsplash
Photo by Craig Whitehead on Unsplash
Suppor Vector Machine (SVM) とは
Support Vector Machine (以降 SVM)とは,基本的には,適切に学習することでデータ点を「二種類1に分類できるようになる」ことが目的の分類器(classifier)である AI の一種で,以下のような仕組みになっていると考えれば良い.
SVM のおおまかなアイディア
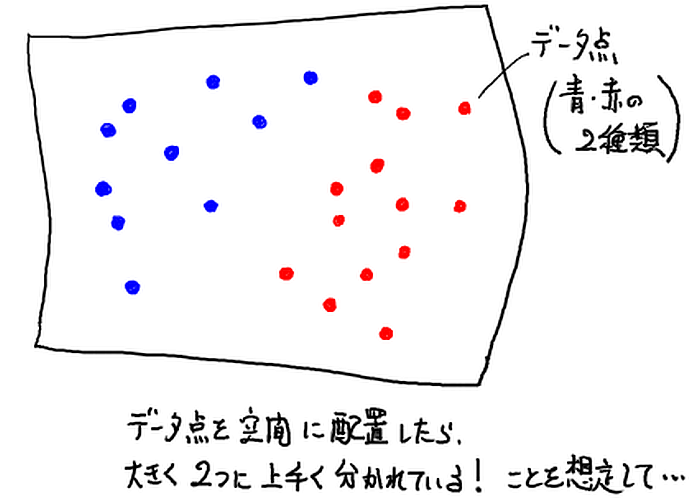
- 空間上に既知のデータ点を配置する. このとき,データ点がおおまかに2つに別れて配置されている,と想定する.
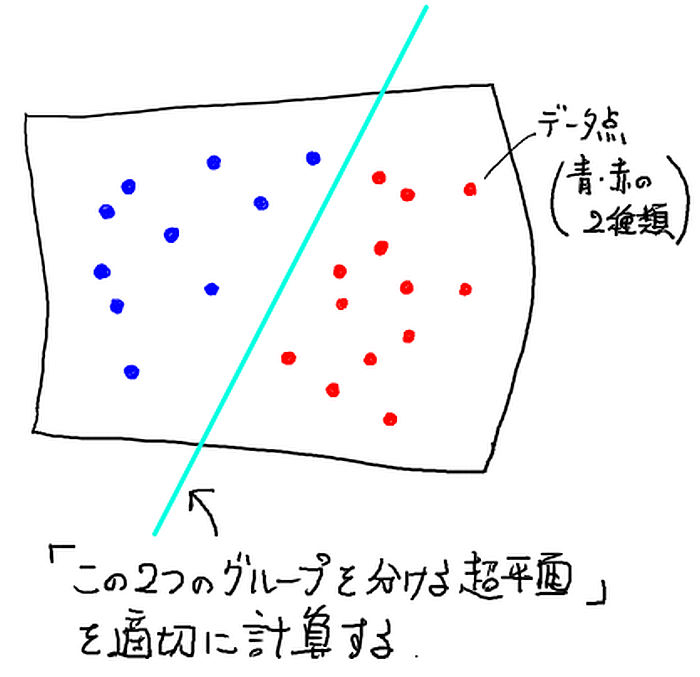
- 一つの超平面を用意し「その両側で空間を二分して」,そのどちらにデータ点があるかでデータを 2つの種類にうまく分類できるようにする.
言い換えると,そのような適切な超平面を既知のデータ点から計算する.これが SVM の学習過程である.
このとき,この超平面に一番近いデータ点を Support Vector 2と呼ぶ…のだが,いまとなってはあまり重要な概念ではないかな.
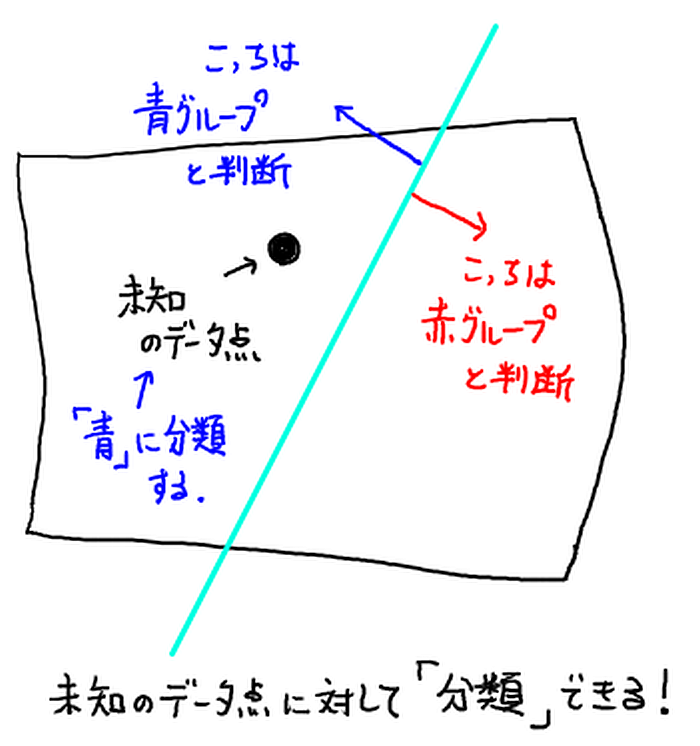
- 未知のデータ点に対し,上で求めた超平面のどちらにあるかで,分類を判断する.
重要なポイントをおおまかに先に書いておく
さて,アイディアはシンプルで分かりやすい. ただ,アイディアを理解した時点で根本的な疑念がいくつか生じるだろう. そのあたりを先に記述しておこう.
- 疑念.
空間にデータ点を配置しても,超平面でうまく二分できるようにデータ点が配置されているとは限らないのでは?
回答. そのとおり.そのため,通常はデータ点を
・非線形変換する
・(上の変換後のデータと組み合わせて)データ点の配置空間の次元を上げる
ことでうまく二分できる「可能性を上げる」. これについては, SVM with polynomial kernel visualization (HD) (Youtube 動画, by udiprod)が大変わかりやすいイメージ動画になっているので一度見ておこう.
さらに,
・うまく分離できないデータ点の存在を許すソフトマージンを採用する3
ことで全体の柔軟性を上げるのだ. より詳しいことは後述する. - 疑念.
「適切な」超平面を計算する手順は?
とくに上記の非線形変換などを行うと,うまくできる気がしないが…
回答. 「なるべく良い」超平面を探す最適化問題に帰着させることとちょっとした工夫で,既存の知識で可能になる. 重要なポイントを書いておこう.
・分類失敗するデータ点も許す「ソフトマージン」で超平面を計算する!
・非線形変換を行う場合,最適化問題の主問題ではなく双対問題を解く
・この双対問題はデータ点の二次形式4になる
・次元やデータ点数が多くなると二次形式の計算量増大がつらい
・二次形式相当の結果をいきなり計算できるカーネルを採用することで,計算量増大をゆるやかにできる.これはカーネルトリックと呼ばれる重要な工夫だ.
詳しくは後述する.
データ点をそのまま配置してほぼ分離が可能な場合
データ点を素直に空間に配置しただけで二種類のグループに超平面で分離が可能な場合から考えよう. こんな都合の良い場合は少ないだろうが,アイディアの根本なのでここから始めよう. ちなみにこれを「線形分離可能(linearly separable)な場合」と呼ぶ.
ハードマージンを考える: 全てのサンプルデータをきれいに分離する超平面へ
この場合,以下のような図で全体を考えることができる.
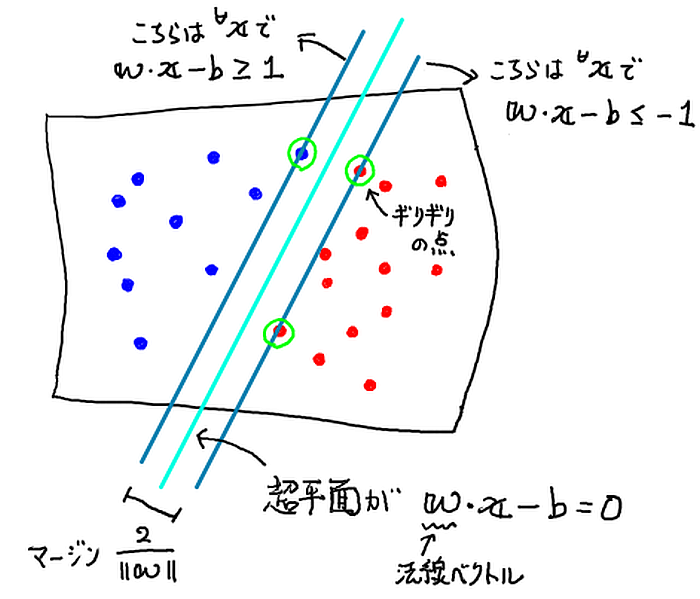
ただし,$\boldsymbol{w}, b$ はそれぞれこの超平面の法線ベクトルと切片で,超平面自身が
\[ \boldsymbol{w}\cdot\boldsymbol{x} - b = 0 \]
という方程式で書かれるとしている.
そして上の図で左上側にあるグループ「青」を $X_{+}$, 右下側グループ「赤」を $X_{-}$ と書くことにして, それぞれ相手グループ側に一番近い点 $\boldsymbol{x}_{\pm \mbox{c}}$ として
\begin{equation} \left\{ \begin{array}{rcl} \boldsymbol{w}\cdot\boldsymbol{x_{+\mbox{c}}} - b & = & 1, \cr \boldsymbol{w}\cdot\boldsymbol{x_{-\mbox{c}}} - b & = & -1 \end{array} \right. \label{eq:on-margin-line} \end{equation}
を満たすとしよう.
超平面の情報,すなわち $\boldsymbol{w}$, $b$ を決めて計算すると,ぎりぎりに乗っている $\boldsymbol{x_{\pm\mbox{c}}}$ に対して
$\boldsymbol{w}\cdot\boldsymbol{x_{\pm\mbox{c}}} - b$ を計算しても 1 や -1 ちょうどにならないのでは? と思うだろう.
実はそのとおりだ.
実は $\boldsymbol{w}$, $b$ には定数倍の自由度があり,それが原因だ.
具体的には,非ゼロ定数 $C$ を用いて
$C\boldsymbol{w}$, $Cb$ という法線ベクトルと切片を使った超平面: $(C\boldsymbol{w})\cdot\boldsymbol{x} - (C b) = 0$ は,元の超平面: $\boldsymbol{w}\cdot\boldsymbol{x} - b = 0$ と全く
同じ超平面を指すのだ.
だから,上の話は「この定数 $C$ を調整して
$\boldsymbol{w}\cdot\boldsymbol{x_{\pm\mbox{c}}} - b$ がちょうど $\pm 1$ になるように
$\boldsymbol{w}$, $b$ を定数倍する操作が隠されている」
という意味だ,と思って良い.
ちなみに望ましい $C$ の計算方法だが,これは簡単で,今の
$\boldsymbol{w}$, $b$
を用いて
$1/C := \boldsymbol{w}\cdot\boldsymbol{x_{\pm\mbox{c}}} - b$
と求めれば良い.そして超平面のパラメータの正しい値を
$C\boldsymbol{w}$, $Cb$ にすれば OK だ.
さて,話を戻そう. グループの他の点も考えると,上の条件は
\begin{equation} \left\{ \begin{array}{rcll} \boldsymbol{w}\cdot\boldsymbol{x} - b & \geq & 1 & \mbox{ for all } \boldsymbol{x} \in X_{+}, \cr \boldsymbol{w}\cdot\boldsymbol{x} - b & \leq & -1 & \mbox{ for all } \boldsymbol{x} \in X_{-} \end{array} \right. \label{eq:in-group} \end{equation}
と書き直せる.
そして,このグループ間のマージン(図を見よ)は
\[ \frac{2}{\| \boldsymbol{w} \|} \]
となるので,これをハードマージンと呼び,分類がなるべくしやすいように,この値をなるべく大きくする超平面を求めることにする,というのがストーリーだ.
つまり, 条件を満たす範囲でなるべく $\| \boldsymbol{w} \|$ を小さくすればよいという,最小化問題なのだ.
さて,この問題をもう少し整理しよう. まず,各データ点 $\{\boldsymbol{x}_i\}_i^N$ の分類を値 $\{y_i\}_i^N$で表すことにし,例えば左上のグループ「青」はすべて $y_i = +1$, 右下「赤」は $y_i = -1$ であるとしよう.
すると式($\ref{eq:in-group}$) は \[ y_i (\boldsymbol{w}\cdot\boldsymbol{x}_i - b) \geq 1 \mbox{ for all } (\boldsymbol{x}_i, y_i) \label{eq:cond-hardmargin} \] と書き直せるので,ハードマージン下での問題全体は
制約条件付き最小化問題:
$\| \boldsymbol{w} \|$ を最小化せよ.
ただし,全てのデータ $(\boldsymbol{x}_i, y_i)$ に対して
$y_i (\boldsymbol{w}\cdot\boldsymbol{x}_i - b) \geq 1$ を満たせ.
を解けば良い,ということになる. これは典型的な最小化問題なので,あとは最適化問題の技術や知見,ライブラリに頼れば良いだけだ.
なお,上の最小化問題を解くと超平面の法線ベクトル $\boldsymbol{w}$ が求まる. ならば超平面の切片 $b$ は? と思うかもしれないが,それは $\boldsymbol{w}$ と, $\boldsymbol{x}_{\pm\mbox{c}}$ のどれかが特定できていれば 式($\ref{eq:on-margin-line}$)から計算できるので問題ない.
分類は?
上の最小化問題を解いて $\boldsymbol{w}, b$ が求まっていれば,未知のデータ $\boldsymbol{x}$ の分類は簡単だ.
$y = \boldsymbol{w}\cdot\boldsymbol{x} - b$ を計算して, $y$ がプラスならばグループ「青」$X_{+}$ に分類し, $y$ がマイナスならばグループ「赤」$X_{-}$ に分類すれば OK! だ.
ソフトマージン: 多少ミスしてもいいよ,という考え方
そのまま配置で「ほぼ」分離できるケースに問題を緩和して考えよう.
つまり,全てのデータ点に対して $y_i (\boldsymbol{w}\cdot\boldsymbol{x}_i - b) \geq 1$ を要求していたハードマージンに対し, 多少は条件を破っても良いとするのだ.
これがソフトマージンである.
全体には,
- 条件を満たしていないデータ点について「ペナルティ量」を用意し,
- 本来小さくしたい量 $\| \boldsymbol{w} \|$ に足して,小さくすべき全体量を定義する
という仕組みを考えるのだ.
より詳しく解説しよう.
まず,本来守るべき制約条件 $y_i (\boldsymbol{w}\cdot\boldsymbol{x}_i - b) \geq 1$ $\Leftrightarrow$ $0 \geq 1 - y_i (\boldsymbol{w}\cdot\boldsymbol{x}_i - b)$ に対し, この条件を守れない場合のペナルティを
\[ 1 - y_i (\boldsymbol{w}\cdot\boldsymbol{x}_i - b) \]
とするのである. 条件を守れていない場合はこの値がプラスになることに留意しておこう.ちなみに条件を守れている場合はマイナスの値になる.
そして,条件を守れている場合はもちろんペナルティはゼロで良いので,両方の場合を合わせて,
\[ \mbox{ペナルティ項 } := \max( 0, 1 - y_i (\boldsymbol{w}\cdot\boldsymbol{x}_i - b) ) \]
とすれば扱いやすいのでそうしよう.
あとは,本来小さくしたい量である $\| \boldsymbol{w} \|$ と合わせて考えれば良いので,たとえば次のような量 $L$
\[ L := \lambda \| \boldsymbol{w} \|^2 + \frac{1}{N} \sum_{i=1}^N \left\{ \max( 0, 1 - y_i (\boldsymbol{w}\cdot\boldsymbol{x}_i - b) ) \right\} \]
を考えてこれを最小化すればいい,ということになる. つまり,
最小化問題:
与えられた正係数 $\lambda$, データ $(\boldsymbol{x}_i, y_i)_i^N$ に対し,
量 $L$ を最小化する $\boldsymbol{w}, b$ を求めよ.
を解いて $\boldsymbol{w}, b$ を求めれば良いのだ.
ちなみに,係数 $\lambda$ はペナルティをどれだけ軽視するかという量になっていて,大きくすると条件の守られ方が緩くなる,という関係にある. 逆に係数 $\lambda$ を小さくすると条件の守られ方は厳しくなり,ハードマージンに近くなる.
実際にやってみる: その 1
さて,このあたりで簡単な例で実際にやってみよう. 分離が可能な簡単な例で,ソフトマージンで超平面を計算してみるのだ(ハードマージンでも良いぞ).
なお,最適化のために Optim package を用いるので,インストールしてない人は
|
|
としてインストールしておこう.
まずは準備だ.
|
|
次に,対象データを作成しよう. まあ何でも良いのだが,今回は下の図を考える.
|
|

そして,この青い線より上に「青」のデータを,赤い線より下に「赤」のデータを用意する.ちょっと長いが次のようにすればよいだろう. まず,線の上下にランダムにデータを取る関数を次のように作成する.
|
|
そして,2000点ほどデータ点を作ろう. $X_p$ が青のデータ点集合(正値集合), $X_n$ が青のデータ点集合(負値集合)だ.
|
|
どんな点配置か,プロットして確認しよう.
|
|

次に,ペナルティの計算と,超平面のパラメータの定数自由度 $C$ の計算の両方のための情報となる量 $y (\boldsymbol{w}\cdot\boldsymbol{x} - b)$ を計算する関数を作る. これは,条件を満たしていれば自由度 $C$ の手がかりに,満たしていなければペナルティに使われる情報なので,ここでわけておこう.
|
|
そして,データ全体に渡って計算して,$C$ と今の 自由定数$C$ を正しく調整してない $\boldsymbol{w}$, $b$ でのペナルティ値を計算する関数を用意する.
|
|
それから,自由定数 $C$ を用いて正しく最小化したい関数 $L$ を次のように定める.
|
|
あとは Optim package におまかせでいい.次のような感じだ.
ちなみに探索初期値は,超平面が右上がりになっている,というぐらいの設定だ.
|
|
* Status: success
* Candidate solution
Final objective value: 5.424325e-02
* Found with
Algorithm: Nelder-Mead
* Convergence measures
√(Σ(yᵢ-ȳ)²)/n ≤ 1.0e-08
* Work counters
Seconds run: 0 (vs limit Inf)
Iterations: 197
f(x) calls: 378
どうやら成功したようだ.結果は以下のようにして取り出せる.
|
|
([-11302.434571580347, 19945.169790257743], 26716.384970865736)
ただしこれは定数自由度 $C$ の調整を受けてない数字なので,正しく調整しておこう.
|
|
すると,超平面のパラメータは次のような値に近い値になるはずだ(データを乱数で作っているので,やるたびに少し違う).
|
|
2-element Vector{Float64}:
-1.1482483276835298
2.0262897972985368
|
|
2.7141979164101984
分離具合をプロットしてみてみよう.
|
|

ふむ,たいへんうまく分離できているようだね. これで OK だ.
ちなみに,作った超平面に基づく分類器のマネごとも作ってみよう. 次のような感じだね.
|
|
試しに,「青」になりそうなデータ値を判定させてみる.
|
|
1.0
正の値を返したので,たしかに「青」と分類しているね.
同様に「赤」っぽいデータ値も判定させてみよう.
|
|
-1.0
これも負値を返したので正しく「赤」と分類している.
というわけで,SVM による分類器が正しく作れた,ということになるね. 簡単な問題の場合はこんな感じだ.
さて,話の続きに戻ろう.
ソフトマージンの考え方の続きだ.
双対問題
そもそも最適化問題の理論に,もとの問題(主問題 primary problem と呼ぶ)に対して,双対問題 dual problem と呼ばれる問題を考えると,
双対定理(duality theorem):
主問題か双対問題が最適解を持つならば,もう一方も最適解を持ち,かつそれらは一致する.
という定理がある. であるので,主問題と双対問題の「難易度」が異なる場合,易しい方を解けば良い,というアイディアにつながるわけだ.
詳細5は省くが 上のソフトマージンの最小化問題にも双対問題を考えることができ,しかもこちらの方が話を拡張しやすいのだ. そこでこれを見ておこう.以下のようになる.
上の最小化問題の双対問題:
与えられた正係数 $\lambda$, データ $(\boldsymbol{x}_i, y_i)_i^N$ に対し,
\[ f(c_1, c_2, \cdots, c_N) = \sum_{i=1}^N c_i - \frac{1}{2}\sum_{i=1}^N \sum_j^N y_i c_i \boldsymbol{x}_i\cdot\boldsymbol{x}_j y_j c_j \label{eq:normal-dual-problem} \]
を最大化する $\{c_i\}_i^N$ を求めよ.
ただし,$\sum_i^N c_i y_i = 0$ と全ての $c_i$ に対して $0 \leq c_i \leq 1/(2N\lambda)$ を満たせ.
そして,超平面の情報であるが,これを解いて求まる $\{c_i\}_i^N$ によって
\[ \boldsymbol{w} = \sum_{i=1}^N c_i y_i \boldsymbol{x}_i \]
と法線ベクトルが定まる.切片 $b$ についてはハードマージンのときと同じだ.
データ点をそのまま配置すると分離が難しい場合(非線形変換へ)
さて,これがある意味ほんとうにやりたい問題だ. データ点を配置しても素直に超平面で分離なんかできないぞ,という,よくありそうなケースを考えたい.
この場合,おおよそ主流の組み合わせが決まっていて,
非線形変換 & 双対問題を考える &カーネルトリックの採用
という形になっている6. ここでもこの流れを紹介しよう.
非線形変換
まず非線形変換であるが,これは形式的には
\[
\boldsymbol{x} \mapsto \boldsymbol{\varphi}(\boldsymbol{x})
\]
とするだけだ.
ただし,このあとカーネルトリックを採用するため,
この$\boldsymbol{\varphi}$ の形は陽に与えないでよい7.
双対問題
次に双対問題を考える点についてだが,これは下記のように 式$(\ref{eq:normal-dual-problem})$を少し変形した問題になる.
非線形変換時の双対問題(カーネルトリック採用前):
与えられた正係数 $\lambda$, データ $(\boldsymbol{x}_i, y_i)_i^N$ に対し,
\[ f(c_1, c_2, \cdots, c_N) = \sum_{i=1}^N c_i - \frac{1}{2}\sum_{i=1}^N \sum_j^N y_i c_i \boldsymbol{\varphi}(\boldsymbol{x}_i)\cdot\boldsymbol{\varphi}(\boldsymbol{x}_j) y_j c_j \label{eq:nonlinear-dual-problem} \]
を最大化する $\{c_i\}_i^N$ を求めよ.
ただし,$\sum_i^N c_i y_i = 0$ と全ての $c_i$ に対して $0 \leq c_i \leq 1/(2N\lambda)$ を満たせ.
カーネルトリック
そしてこの問題に対してカーネルトリックを採用する.
ここで,そもそもカーネルトリックとはなにかを説明しよう.
これは簡単な話で,非線形変換後の二次形式ないしはベクトルの内積(ここでは
\[ \boldsymbol{\varphi}(\boldsymbol{x}_i)\cdot\boldsymbol{\varphi}(\boldsymbol{x}_j) \]
の項)を,カーネル(Kernel)と呼ばれる「計算量が少ない二変数関数」
\[ k( \boldsymbol{x}_i, \boldsymbol{x}_j ) \]
で置き換えてしまう操作を言うのだ. なにそれ? と思うかもしれないが,再生核ヒルベルト空間 reproducing kernel Hilbert space の議論によって,(もちろん一定の前提条件を満たせば,だが)こうしても良いということがわかっているのだ. こうすることで,二次形式や内積を計算しなくても少ない計算量で話が済むだろう,というわけだ.
だから,最終的には次の問題を解くことになる.
非線形変換 & カーネルトリック採用時の双対問題:
与えられた正係数 $\lambda$, データ $(\boldsymbol{x}_i, y_i)_i^N$ に対し,
\[ f(c_1, c_2, \cdots, c_N) = \sum_{i=1}^N c_i - \frac{1}{2}\sum_{i=1}^N \sum_j^N y_i c_i k( \boldsymbol{x}_i, \boldsymbol{x}_j ) y_j c_j \label{eq:nonlinear-kernel-trick-dual-problem} \]
を最大化する $\{c_i\}_i^N$ を求めよ.
ただし,$\sum_i^N c_i y_i = 0$ と全ての $c_i$ に対して $0 \leq c_i \leq 1/(2N\lambda)$ を満たせ.
そして超平面の決定と分類だが,実は超平面の法線ベクトル $\boldsymbol{w}$ は計算しなくてよい(やっぱり $\boldsymbol{\varphi}$ を必要としないのだ). 解説しておくと,次のように変形を考えれば,カーネルだけあれば良いことがわかる.
- 超平面の切片 $b$ の計算:
マージンぎりぎりにある $\boldsymbol{x}_{\mbox{c}}$ を一つ見つけておいて,次のように計算する.
\begin{eqnarray} b = \boldsymbol{w}\cdot\boldsymbol{\varphi}(\boldsymbol{x}_{\mbox{c}}) - y_{\mbox{c}} & = & \sum_{i=1}^N c_i y_i \boldsymbol{\varphi}(\boldsymbol{x}_i)\cdot\boldsymbol{\varphi}(\boldsymbol{x}_{\mbox{c}}) - y_{\mbox{c}} \nonumber \cr & = & \sum_{i=1}^N c_i y_i k( \boldsymbol{x}_i, \boldsymbol{x}_{\mbox{c}} ) - y_{\mbox{c}} \end{eqnarray}
- 未知のデータ $\boldsymbol{x}$ の分類:
次の量がプラスならば $X_{+}$ の元,マイナスならば $X_{-}$ の元であると判定する.
\[ \boldsymbol{w}\cdot\boldsymbol{\varphi}(\boldsymbol{x}) - b = \sum_{i=1}^N c_i y_i k(\boldsymbol{x}_i, \boldsymbol{x}) - b \]
カーネルの種類
ちなみにカーネルの種類等であるが,まあ典型的なのは次のような感じか.
- カーネルの例
名前 関数 $k( \boldsymbol{x}_i, \boldsymbol{x}_j ) = $ 備考 多項式 $( \boldsymbol{x}_i\cdot\boldsymbol{x}_j + r )^d$ 意外と有効だ ガウシアン動径基底関数
(Gaussian RBF, Gaussian radial basis function)$\displaystyle \exp\left( - \frac{ \| \boldsymbol{x}_i - \boldsymbol{x}_j \|^2 }{2\sigma^2} \right)$ 広く使われる sigmoid $\tanh(\kappa \boldsymbol{x}_i\cdot\boldsymbol{x}_j + c )$ ただし,$c < 0 < \kappa$
実際にやってみる: その 2
ここでは SVM を扱うちょっと有名なライブラリ LIBSVM8 を julia で使えるようにした LIBSVM package を採用して実習してみよう.
これをインストールしていない人はまずは以下のようにインストールしよう.
|
|
ちなみに LIBSVM package の使い方だが,using LIBSVM してある状況で
?svmtrain とするとデフォルト値がどうなっているかとか使い方が分かるよ.
デフォルトはガウシアン RBF をカーネルにした非線形 SVM だね.
あとは LIBSVM の情報を見ると良いね.
では,まずは典型的な例として,前回やったアヤメのデータを分類させてみよう. 下記のように準備 & データのダウンロードをして,
|
|
今回はデータの半分を SVM の学習用データに,残りの半分を SVM の性能評価に回そう. 次のようにデータを半分に分けておく.
|
|
そうそう,アヤメの花は 3種類あったので,上の SVM のストーリーからずれる.
どうするの? と思うだろうが,2種類判定を繰り返せばよいのだ.
そして,以下のように,LIBSVM package はそのあたりを自動でやってくれる.
LIBSVM package では,分類が 2種類より大きい $n$ 種類になっても大丈夫.2種類分類器を ${}_n C_2$ 個作ってそれぞれで判定し,多数決で判定するタイプの多種類分類(one-against-one strategy と呼ぶ)を自動でやってくれる.
で, LIBSVM ではいきなり以下の 1行で SVM を学習,構築できる.
|
|
LIBSVM.SVM{String, LIBSVM.Kernel.KERNEL}(SVC, LIBSVM.Kernel.RadialBasis,
nothing, 4, 75, 3, ["Iris-setosa", "Iris-versicolor", "Iris-virginica"],
Int32[1, 2, 3], Float64[], Int32[], LIBSVM.SupportVectors{Vector{String},
Matrix{Float64}}(30, Int32[5, 13, 12], ["Iris-setosa", "Iris-setosa",
"Iris-setosa", "Iris-setosa", "Iris-setosa", "Iris-versicolor",
…略…
LIBSVM.SVMNode(1, 6.0), LIBSVM.SVMNode(1, 5.8), LIBSVM.SVMNode(1, 6.3)]),
0.0, [0.8070380364343522 0.8047780005392675; 0.0 0.741676866696239; … ; -0.0
-1.0; -0.0 -1.0], Float64[], Float64[], [0.12550506116227908,
0.21415319269230185, -0.07664844428517169], 3, 0.25, 200.0, 0.001, 1.0, 0.5,
0.1, true, false)
前回の Deep Learning に比べて,SVM の学習が一瞬で終わることに注目しよう(まあ,データの個数分以上に学習過程を増やせないしね). SVM の方が構造が明確なので,なにかと計算が高速だと思うぞ.
さて,出来上がった SVM分類器を用いて,検証用データを分類させてみよう.
|
|
75-element Vector{String}:
"Iris-setosa"
"Iris-setosa"
"Iris-setosa"
"Iris-setosa"
…略…
そして,分類結果を正解と比較してみよう.たくさんあるので,正解率をいきなり計算する形でいいかな.
|
|
0.9333333333333333
ほう,いきなり 93% の正解率を出したか. データの正規化等を行っていないし,学習に用いたデータはわずか 75個にすぎないのにだいぶ良い値だ. こうした分類に関してはやはり SVM は良い性能を持つのだな,と実感できる.
レポート
下記要領でレポートを出してみよう.
- e-mail にて,
- 題名を 2021-numerical-analysis-report-13 として,
- 教官宛(アドレスは web の "TOP" を見よう)に,
- 自分の学籍番号と名前を必ず書き込んで,
- 内容はテキストでも良いし,pdf などの電子ファイルを添付しても良いので,
下記の内容を実行して,結果や解析,感想等をレポートとして提出しよう.
- SVM を適用すると良さそうな分類問題の例が LIBSVM Data に挙げられているので,この中からどれでもよいので対象として SVM を適用してみよう.
やり方は今回の授業の最初の実習例のように自分で地道にプログラムしてから
Optimpackage などで最適化をしても良いし,LIBSVMpackage を使っても良い.
なお,LISVM Data のデータの取扱いに困るという人もいるだろう. たとえば,「データの意味がよくわからない」とか,「そもそもどうやって julia に取り込んだら良いのか技術的に困る」という理由でだ. そこでそのあたりを少し解説しておこう.
まず,データの意味について解説しておこう.といっても全部は多すぎるので,a1a から a9a という名前のものについてのみにしておこう. 他もこれで慣れればきっとだいじょうぶだろう.
まず,これら a1a - a9a のデータは,UCI にある Adult というデータを変換したもので,これはアメリカ人の特徴データ 14個と,それに加えて「年収が 5万ドル以上かどうか」を分類したデータだ.
たとえば a1a の 1行目は
-1 3:1 11:1 14:1 19:1 39:1 42:1 55:1 64:1 67:1 73:1 75:1 76:1 80:1 83:1
となっているが,最初の項 -1 が分類を表していて,この場合は年収が5万ドル以下ということになる. 5万ドルを越えるとここが +1 になるのだ.
そして残りの 14個のデータは「下記の特徴 14個を全部並べ直して 123個の特徴9に直し,そのうち,あてはまるものを列挙したもの」になる.
よって,例えば a1a の 1行目の第2項は 3:1 は年齢が下から 3番めの段階にあたること,第3項の 11:1 は雇用型が 6番目の型にあたること,を意味するのだ.
- 14個の特徴とその並べ直しのための情報
| 仮番号 | 特徴 | 数字か種類か.数字の場合,何段階に変換したか. |
|---|---|---|
| 01 | 年齢 | 数字 → 5段階に変換 |
| 02 | 雇用型 | 8種類 |
| 03 | 体重 | 数字 → 5段階に変換 |
| 04 | 学歴 | 16種類 |
| 05 | 教育暦年 | 数字 → 5段階に変換 |
| 06 | 結婚歴 | 7種類 |
| 07 | 職業 | 14種類 |
| 08 | 家族関係 | 6種類 |
| 09 | 人種 | 5種類 |
| 10 | 性別 | 2種類 |
| 11 | 資本利益 | 数字 → 2段階に変換 |
| 12 | 資本損失 | 数字 → 2段階に変換 |
| 13 | 週あたり労働時間 | 数字 → 5段階 |
| 14 | 出身国 | 41種類 |
注意: 上の合計をとって 5段階x3個 + 2段階x2個 + (8 + 16 + 7 + 14 + 6 + 5 + 2 + 41)種類 = 123 で,これをすべて「種類」とみなして 123種類になる.
そこでデータは 123次元の空間に属する点とみなして,該当する種類の次元の座標を 1 にして,そうでない次元の座標を 0 としているのだ. 当然,123次元のうち 14次元の座標が 1 で,残りの次元の座標は 0 になる.
なんでこんなことにしているかというと,データに数字のものと,属性タイプみたいなものが混在しているので,全体を一度に取り扱うためにはこうした方が良い,というもののようだ.
次にこのデータの読み込み方だが,少し注意すべきことが有る. データを先に少し眺めてみると気づくだろうが,欠損しているデータが混じっているのだ.
欠損データが混じっていると,読み込みだけでも面倒だし,読み込んだ後でも取扱いには注意が必要だ10.
そこで,下に示す「データの取扱いのためのDataFramespackage」の出番だ.
データを扱うときは,欠損などがあっても問題なくデータを扱えるDataFrames package を使おう!
あとは小さな工夫をするだけなので,順にプログラムを見せよう.
まず,データそのままだと扱いにくいので,CSV形式に直してファイルを作る.
|
|
次に,必要なパッケージの読み込みだ. なお,未インストールならば先にインストールしておこう.
|
|
次に,CSVファイルを読み込んで,データに取り込む.
|
|
1,605 rows × 15 columns (omitted printing of 6 columns)
Column1 Column2 Column3 Column4 Column5 Column6 Column7 Column8 Column9
Int64 Int64 Int64 Int64 Int64 Int64 Int64 Int64 Int64
1 -1 3 11 14 19 39 42 55 64
2 -1 3 6 17 27 35 40 57 63
…略…
次に,DataFrames package の機能をありがたく使わせてもらって,欠損データを排除しよう.
|
|
あとは読み込んだデータを SVM 用にするのだ.
|
|
こうして得られる X_train が学習用特徴データに,Y_train が学習用の分類データになる.中身を見てみると次のような感じになっているはずだ.
|
|
1478×123 Matrix{Int64}:
0 0 1 0 0 0 0 0 0 0 1 0 0 … 0 0 0 0 0 0 0 0 0 0 0 0
0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
…略…
|
|
1478-element Vector{Int64}:
-1
-1
-1
-1
…略…
-
二種類への分類は用途が限られすぎ…と思うかもしれないが,現在は多種類の分類機としての拡張もなされている.もちろん,二種類への分類を単純に繰り返しても多種類分類ができるぞ. ↩︎
-
このことから,support vector machine の名前がある. ↩︎
-
ソフトマージンを採用しないもの, たとえばハードマージンを採用する(サンプルデータ点をすべて分類成功するような超平面を求めることに相当する)ものももちろん SVM なのだが,よほどきれいなデータ点でないと「全体がそもそも失敗する」ので実用性が低くなってしまうな. ↩︎
-
ベクトル $\boldsymbol{x}$ の二次形式とは,ある行列 $A$ が存在して $\boldsymbol{x}^{T} A \boldsymbol{x}$ と書けるものを言うぞ.要するにたくさんの変数 $\{x_i\}_{i=1}^n$ の二次式(ただし全部二次項)だな. ↩︎
-
主問題 primal problem と双対問題 dual problem あたりをキーワードにして検索して勉強すると良い. ↩︎
-
もちろん,「おおよそ状況がわかっている」ケースなどでは非線形変換のみでも問題ない. ↩︎
-
カーネルを決めることが非線形変換を決めることにも相当するので,非線形変換を先に決める必要がないという言い方をしても良い. ↩︎
-
Chih-Chung Chang and Chih-Jen Lin, LIBSVM : a library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2:27:1--27:27, 2011. Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm ↩︎
-
調べてみるとこれを 129個の特徴に変換して扱っている人もいる.そういう人は特徴の No.11,12(資本による利益値,損失値)をそれぞれ 5段階に変換しているようだ. ↩︎
-
欠損データをどうするかはもちろん方針次第だ.ただ,どうするにせよ,素でプログラムを書くと面倒な処理になりかねない. ↩︎