06. プログラム可能なフィルタ
 Photo by Anne Nygård on Unsplash
Photo by Anne Nygård on Unsplash
前回は単機能なフィルタを中心に学んだので,ここではもう少し複雑な動作が可能な、「プログラミングが可能な」フィルタについて学ぼう.
awk: データ処理専用? フィルタ

「プログラムできて、標準入出力を受け付ける」ものは全てプログラム可能なフィルタであるので、大変にその種類は豊富ということになる.
ここでは、まずはプログラムが可能なもっとも簡潔なフィルタの一つである awk について学ぼう.
awk は
- 行を読み込み、
- 中身を分割し、
- 処理を施す
という作業に向いた設計なので、大変参考になるだろう.
なお、比較的簡単にプログラムできて、フィルタを作るのに向いているツール/言語としては、現在は
python や ruby などの light-weight プログラミング言語が挙げられる.
これらもいずれ使えるようになっておくと良いだろう.
awk の真髄は「簡単なことは簡単にできる」こと
簡単なデータ処理を awk ほど簡単にできるツールはそうそうあるものではない.
awk の起動, 使い方
awk の使い方(起動方法)には次の 3種類がある。

■ awk の呼び出し方
注1: このすぐあとで学ぶ
スクリプトファイルのコマンド化
が為されていれば OK.
なお、「スクリプト」とは動作指示書, すなわち,プログラムのことである.
awk スクリプトの形
awk は sed 同様,入力を一行ずつ処理していく.
つまり,処理単位は「行」である.
そして,awk のスクリプトは基本的に,
|
|
という構造をしている.
以下、これを少しずつ詳しく説明しよう.
まず、awk のマニュアルなどでも以下の用語を使うので覚えておこう.
| 用語 | 解説 |
|---|---|
| パターン | 上の例の「条件」というところ.処理対象となる行指定条件のこと.何も書いてない場合は,「無条件にそのデータを対象とする」という意味になる. |
| アクション | 上の例の「コマンド;コマンド;…」というところ.; の代わりに改行でも良い.対象行に対する一連の(複数)コマンド(処理)のこと. |
awk の動作
awk は次のように動作する.
- 最初に,BEGIN 行があればそのアクションを 1度だけ実行する.
- 次に,データとして行を一行読み込み,
- 最初の条件と照合して、
- 処理対象となる… 対応するアクションを適用し、
- 処理対象とならない…なにもしない、
- 次の条件と照合して,
- 処理対象となる… 対応するアクションを適用し、
- 処理対象とならない…なにもしない、
- さらに次の条件と照合…
- 処理対象となる… 対応するアクションを適用し、
- 処理対象とならない…なにもしない、
- (上の作業を繰り返して…)
- 照合する条件が無くなったらこの行のデータ処理は終了.
- 最初の条件と照合して、
- データとして次の行を読み込み,上と同様の作業を行う.
︙
以下,読み込む行がなくなるまで繰り返し
︙ - 最後に,END 行があればそのアクションを 1度だけ実行する.
実行例.
上の繰り返しの意味がつかみにくい人は,以下の例を見てみよう.
例えば,以下の中身をもつ test.awk というファイル
|
|
を用意して,
|
|
と実行すると,
|
|
という結果が得られる. データ行に対して,二つのパターン(無条件パターン)がそれぞれマッチして,それぞれ別個にアクションが行われたことが分かる.
awk のパターン(対象行の指定)
awk のパターンは、まあ普通は以下の6種類と思えば良い.正規表現以外はごく素直なので簡単だ.
| パターン | 説明 |
|---|---|
| 全部該当 パターンとして何も書かないと、こうなる |
|
| BEGIN | データを読みこむ前に一回だけ該当する、という特別なパターン. |
| END | 全てのデータ読み込みとその処理が終わった後に一回だけ該当する、という特別なパターン. |
| /正規表現/ | 指定された正規表現を「含む」行が該当する |
| 論理式 | 指定した論理式が成り立てば、該当する |
| パターン1, パターン2 | パターン1 が該当する行から、パターン2 が該当する行までの範囲の行、が該当する |
データの分解
awk が読み込んだデータをどう分解するかを知っておこう.
まずマニュアルに出てくる用語を説明しておこう.
| 用語 | 解説 |
|---|---|
| レコード | 読み込まれた一行のデータ。 |
| フィールド | レコードを複数の項目に分解した時の、その項目。 レコード中の n番目のフィールドは $n で表せる。 $0 は特別に全てのフィールド、つまり、レコードを指す。 |
そして、レコードをフィールドに分解する時の「区切り」は,デフォルトでは「空白(連続しても良い)」である。 この区切りに使う文字を変更して指定するには、以下の二つの方法がある.
- 起動時にオプションで指定する。
-F というオプションを使うと、フィールドの区切りを変えられる。 - プログラム中で指定する。
プログラムの途中で、FS という変数を書き換えると、それが新たなフィールドの区切りになる。
実習
以下のようにして、実際にフィールドの区切りを変えてみよう。 まず、何も設定しないデフォルト設定では、空白が区切りになるので、
|
|
とするとファイル名が出力され(環境や設定によっては $7 ではなく $8 などの場合もあるので自分の状況にあわせて考えよう),
|
|
とすると、パーミッション情報が得られる。
では、フィールドの区切りの文字を 0 (数字のゼロ)に変えてみよう。
上に書いたように,次の二つの方法がある。
|
|
|
|
なお、BEGIN をうまく使っていることに注意しよう. これをまずやってみよう. また,他の区切り文字もいろいろ試してみよう.
簡単な文法: 特別な変数
| 変数 | 説明 |
|---|---|
| FS | 入力レコードをフィールドに分解するときに使う区切り文字. |
| ARGC | awk 起動時の引数の個数. 起動プログラム自身の名前も含むので,必ず 1以上となる. |
| ARGV | awk 起動時の引数を並べた配列. n 番目の引数は,ARGV[n-1] . よって,引数は ARGV[0] から ARGV[ARGC-1] まであることになる. また,1番目の引数,つまり ARGV[0] はコマンド自身の名前になる. |
| NF | 現在のレコードのフィールド数. |
| NR | その時点での全レコード数. 要するに,そこまで読み込んだ入力データの行数. |
簡単な文法: 文字列操作
主にアクションの中で使う awk の、文字列を操作するコマンドを紹介しておこう.
| コマンド | 解説 |
|---|---|
| gsub(r, s) | 正規表現 r にマッチする部分を全て s に変換。 |
| index(s, t) | 文字列 s 中に含まれる文字列 t の位置。 |
| length(s) | 文字列 s の長さ。 |
| match(s, r) | 文字列 s 中で正規表現 r にマッチする位置。 |
| split(s, a [, r]) | 文字列 s を正規表現 r を用いて分割して配列 a に入れる。 r を省略すると FS を用いる(つまり、フィールド分割と同じになる)。 |
| substr(s, i, [,n]) | 文字列 s の i 番目から最大 n 文字の(部分)文字列を返す。 |
| tolower(str) | 文字列 str の小文字化。 |
| toupper(str) | 文字列 str の大文字化。 |
簡単な文法: 演算
パターンやアクションの中で使う awk の演算コマンドなどを紹介しておこう.
データ処理やパターンマッチングでよく使うのでざっと見ておこう.
| コマンド等 | 解説 |
|---|---|
| + - * / ^ % | 四則演算、べき乗、剰余。 |
| == != < > <= >= | 同値、非同値、より小さい、より大きい、以下、以上。 (注) 最初の記号は"=" が二つつながっている。 |
| = | 代入. (注) 記号は"=" が一つ. 同値と違うので注意. |
| ! && ¦¦ | NOT AND OR |
| ~ !~ | 正規表現マッチ、否定のマッチ。 |
| in | 配列に属する。 |
| atan2(y, x) | y/x の逆 sin 関数. |
| exp, cos, sin, log, sqrt | ごく普通の関数. |
| int(式), rand() | 整数への切り捨て,乱数(0〜1 の間) |
簡単な文法: 制御構造
場合分けが必要なシーンではプログラムの制御が必要になる.そういうときはこれだ.
| コマンド等 | 解説 |
|---|---|
| if (条件) 条件が正しい時の処理 else 条件が正しくない時の処理 |
条件が正しいかどうかチェックして,それによって処理を変える. else 文は省略してもよい. |
| for (初期化 ; ループ条件 ; ループ毎処理) 処理 | 繰り返し. 初期化を行ってから,ループに入る. ループでは,ループ条件が真ならば、処理を行い、ループ毎処理を行い, もう一度ループに入る. ループ条件が偽ならば,ループ終り. |
| for (変数 in 配列) 処理 | 繰り返し. 変数を自動的に一通り変えていって,そのたびに処理が行われる. |
簡単な文法: 配列
awk の面白いところは、そこそこ古いツールなのに「連想配列」が使えるところだ.
用途によってはこれは大変に便利なのでぜひ習得しておこう.
まず、配列とは多変数をつなげて一つにしたもので,ベクトルのようなものと思えば良い.そして、 普通の配列は各要素はその要素番号で指定するが、 連想配列は各要素に「文字列で」名前を付け、その名前で指定するようになっている.
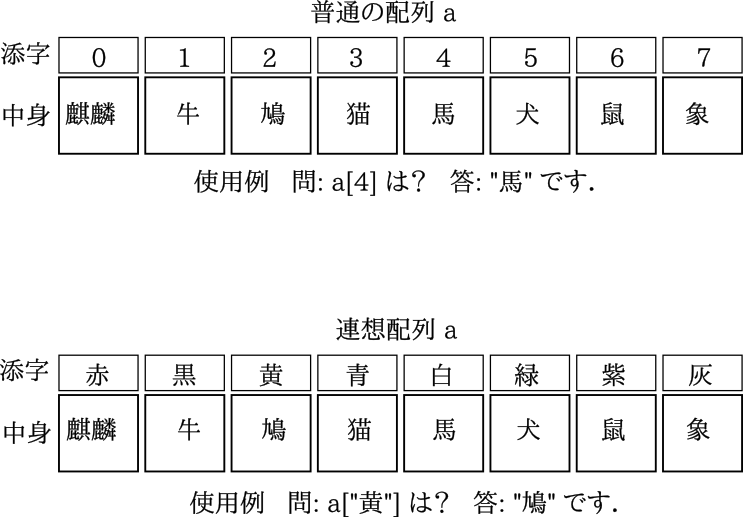
■ awk の配列
連想配列が使えると便利なシーンが有るよ!
「3番目の」箱には何が入ってますか? と聞けるのが普通の配列で、 「黄色い」箱には何が入ってますか? と聞けるのが連想配列. データを処理してまとめたあとは連想配列だと便利なシーンが有る.
実行例 (1)
awk で「ファイルの名前と大きさを配列に記録しておいてあとで処理する」ことを考えよう.
簡単のため,今回はこの「処理」を単に「表示」するだけとすると以下のようになる.
まず比較のために、これを普通の配列でやろうとすると、
|
|
という内容のスクリプトファイルを用意し( $8 ではなく $7 などの場合もあるので自分の環境にあわせて考えよう),test.awk という名前で保存してから,
|
|
として実行して、
Text_Highlighter-0.7.1.tgz's size is 137135
moin-1.7.2's size is 4096
moin-1.7.2.tar.gz's size is 5524184
package.xml's size is 11639
pukiwiki-1.4.7_notb's size is 4096
pukiwiki-1.4.7_notb.tar's size is 1116160
pukiwiki.ini.php's size is 18123
pukiwiki.ini.php.2007's size is 18211
test.awk's size is 105
というような結果を得ることになる.
このスクリプトをみると、 関連する情報を処理するのにわざわざ二つの異なる配列を用意しないといけないため、データの関連性が失われていることに注意しよう. これは、本来は不要な添字の数字を使うことなどにつながってしまっていて、無駄やバグの温床となっており、いろいろとまずい.
一方,連想配列を用いるならば、
|
|
という内容(君の環境だと $8 ではないかもしれないことは上同様)で同じことが出来る. 比較して、論理的にも無駄がなくなり,分かりやすく,間違えにくくなっている ことに注目しよう.
実習
上のスクリプトを実際に作成し,動作させてみよう.
実行例 (2)
|
|
とすると,これは
|
|
と同じである.
実行例 (3)
|
|
とすると(君の環境だと $8 ではないかもしれないことは上同様),ファイル名が 5文字以上のファイル名が出力される.
実行例 (4)
|
|
とすると,ファイルの大きさが 20バイト以上のファイルの大きさの合計が出力される.
実習
- 上の実行例を理解するとともに,実行してみよ.
- 次の動作を理解し,隣の人に解説してみよう.
通常の unix 環境の場合:
|
|
cygwin環境などの場合:
|
|
スクリプトファイルのコマンド化
シェルの alias などで体験したように,
Unix では自分でコマンドを作る方法が豊富に用意されている.
その豊富な方法の一つとして、 awk + スクリプト のような組み合わせを一つのコマンドのように見せることができる方法がある. これがスクリプトのコマンド化である。
これによって 複雑な処理をコマンド一つで呼び出せるように できるようになる. これは大変に便利で、しかもこうしてコマンドを増やしていけば便利さは増すばかりなのでぜひできるようになっておこう.
スクリプトをコマンド化する具体的な方法
やるべきことは以下の二つ.
1. そのスクリプトを実行するプログラムの名前をスクリプト自身に記入しておく.
これは、スクリプトファイルの先頭行に、
#!プログラム名 (と必要なオプション)
という 1行を追加で書き込めば良い.
ちなみにこの 1行をシバン(shebang)という.
具体的にどう書くかは、例で示そう.
例えば awk の場合は、まず、普通に which コマンドを
|
|
として実行して,awk コマンドの実体がどこにあるか調べよう.
結果はおそらく /usr/bin/awk か /bin/awk だろう.
この調べがついたら,あとはこれをオプション込みで書き込めば良い.
例えば /usr/bin/awk が実体である場合は,
対象のスクリプトファイル(例えば test.awk)の先頭行に
#!/usr/bin/awk -f
と追加で 1行書きこめばよい.
コマンドの実体の場所は環境によって異なる.必ず which で調べてから書き込もう.
awk の場合、オプション -f は重要だ.忘れないように.
2. スクリプトファイルに,「実行してよい」と許可を出しておく.
これには chmod コマンドを使う.
使い方は、これも例で示そう.
例えば対象のスクリプトファイルが test.awk という名前ならば、
そのファイルのあるディレクトリで,chmod コマンドを
|
|
として実行すればよい.
スクリプトファイルのコマンド化の例 (1)
例えば,ファイル test.awk を
|
|
という内容にして,実行許可を出しておく.
そうしておいて,適当な文章が入ったファイル dummy.txt に対して,
|
|
と実行すると、wc コマンドもどきの動作をさせることができる.
実際、
|
|
とやってみて、この新しく作ったコマンドの動作の結果と比べてみよう.
さて、これがどういうことなのか考えてみよう. 例えてみると次のような絵で表せる。
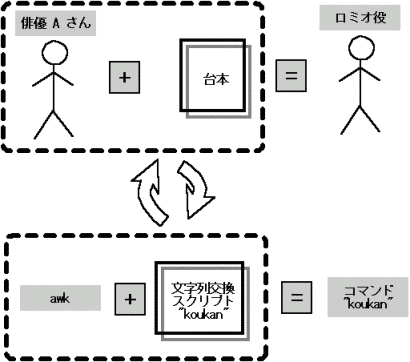
■ スクリプトのコマンド化を例えるなら… ■
例えば、俳優が台本に従って演技するとき、それは俳優自身ではなくて演劇の役として行動していることになる。 つまり、台本にしたがっているならば役の名前で呼ばれる人になっている、 といえる。
これと感覚的には同じことである。 つまり、複雑で長いスクリプトを用意して、それに従ってコマンドが動作するとき、 人間からみればその動作の意味はスクリプトで決まるのである。
よって、スクリプトの名前でそれをコマンド化できれば、 人間にとって直感に非常にあうので、わかりやすく、かつ、便利になる、 というわけである。
スクリプトファイルのコマンド化の例 (2)
入力されたデータの最初の項目の数字をどんどん合計して、その平均を出すコマンド average を作ってみよう. 具体的には,
|
|
という中身で作れば良い. うまくいったならば,例えば,dummy.dat というファイルを
|
|
という中身で用意して,
|
|
とすれば,
|
|
として,平均,合計,総数 が出力されるはずだ.
実習
- 上の実行例を理解するとともに,実行してみよ.
- 上の例を参考にして,平均だけでなく、分散も 一緒に計算して出力するコマンドを作ろう.
レポート
以下の課題について能う限り賢明な調査と考察を行い,
2022-AppliedMath7-Report-06
という題名をつけて e-mail にて教官宛にレポートとして提出せよ. なお,レポートを e-mail の代わりに TeX で作成した書面にて提出してもよい.
注意
近年はセキュリティ上の懸念から,実行形式のプログラムなどをメールに添付するとそのメールそのものの受信を受信側サーバが拒絶したりする.
そういうことを避けるため,レポートをメールで提出するときは添付ファイルにそういった懸念のあるファイルが無いようにしよう.
課題
- 上の「平均」と「分散」を出力するコマンドを作成し,実際に適当なデータファイルを作り,それに対してその作業を行い,その結果を示せ.
もちろん,作成したコマンドの中身も記すこと.
- 今月の最終木曜日をもとめる awk スクリプトを組め.
ただし,入力データとして cal の出力を利用して良い.
実際に作成したスクリプトを紹介するとともに,その動作状況の様子を報告せよ. - osaka 130.003.125.224 のように,単語のあとに3桁の数字列が4つピリオドでくっついている文字列があるとする.
こういう入力データを,数字の部分だけ前後引っくり返して
osaka 224.125.003.130 と出力するように awk スクリプトを組め.
なお,複数のスクリプトを用意してそれを何回か使う(パイプでつなぐとかね),という実現の仕方でも良い.
これも実際に適当なデータファイルを作って作業を実際に行い,その様子を報告せよ. - Julia Evans による Bite Size Command Line! のサンプルページにある awk の画像を見て,書いてあることが理解できることを確かめよう.