機械学習: 入門
機械学習入門
最後にせっかくなので,近年たいへんに発達し注目されている機械学習について簡単に学んでおこう. 機械学習を行う道具立てとしては今回は前回学んだ Julia を素で使い,機械学習用のライブラリ・フレームワーク等は無しという状況でやってみることにしよう.
Neural network と深層学習
機械学習という分野は広くて様々な技術を含むが,最近注目されているのは neural network (NN と略されることも多い) を用いた深層学習だろう. この技術によって画像分類問題で大変画期的な結果が出て以来,大変 hot な分野であることは間違いない.
しかし,その開発が大変勢いある分野であるため,細かい技術論にまどわされて「全体がよくわからない」という者も多いだろう.
そこで今回は,その「基本的な考え方」を授業時に簡単に解説し,そして実際に自分でプログラムして動かしてみよう.
今回のターゲット問題
機械学習のの重要な本質の一つは「明示的なアルゴリズムではどうやって解決方法を実現したら良いかわからない問題」に解決方法を与えるところにある. しかしまあ,本当にそうした問題は扱いそのものがそれなりに面倒だったりするので,今回は大変簡単な問題を「解決できないふりをして」取り組むターゲットとして扱おう.
今回扱う問題は, $x \in [0,1]$ に対して実際は
$g(x) = \left\{\begin{array}{rcl} 1 & : & 1 / 3 < x < 2 / 3, \cr 0 & : & \mbox{ otherwise } \end{array}\right.$
である関数を,その関数形を知らない状態で データ $\{ x_k, g(x_k) \}_{k = 1}^{N_d}$ だけをもらってその情報から近似関数を作ろう,という問題としよう. もちろん,この問題は通常は「補間」技術を用いたほうが筋も結果も計算時間も良いのだが,今回は敢えて機械学習の練習問題としてこれを扱おう.
今回用意する neural netowrk
スカラー実数 $x$ を入力とし,パラメータをもつ層が 3つで,全体の出力はスカラー実数であるような,大変単純な NN を今回は考えよう. 大雑把には下図のような設計になる.
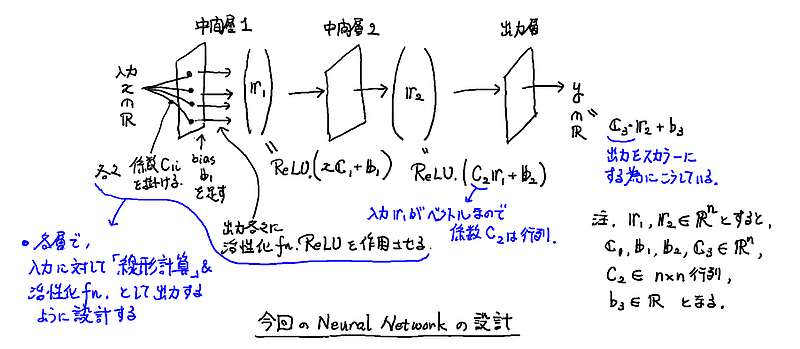
より具体的には, 入力を $x$, 出力を $y$, 中間層(ベクトル, 要素数 $n$)の出力をそれぞれ $\boldsymbol{r}^{(1)}$, $\boldsymbol{r}^{(2)}$ として, 密結合係数として $n$ 次元ベクトル $\boldsymbol{C}_1, \boldsymbol{C}_3$ と $n \times n$ 行列 $C_2$, バイアスとして $n$ 次元ベクトル $\boldsymbol{b}_1$, $\boldsymbol{b}_2$, スカラー $b_3$ を用意して,NN が
$\left\{\begin{array}{rcl} \boldsymbol{r}^{(1)} & = & \mbox{ ReLU }( x \boldsymbol{C}_1 + \boldsymbol{b}_1), \cr \boldsymbol{r}^{(2)} & = & \mbox{ ReLU }( C_2 \boldsymbol{r}^{(1)} + \boldsymbol{b}_2), \cr \mbox{ 出力 } y & = & \boldsymbol{C}_3 \cdot \boldsymbol{r}^{(2)} + b_3 . \end{array}\right.$
となっているケース(ほぼ最小限セットだな)を考える. $n$ はそうだなあ,たぶん 5 ~ 10 ぐらいでうまくいくだろう(かなり無駄が多いけどな).
ここで出てくる ReLU 関数は活性化関数と呼ばれる関数の一つで次のように定義され,まあ,なんというか,アナログ性を消さないようにしてある if 文の役目を持つ関数と思って良い.
$\mbox{ ReLU } (x) = \left\{\begin{array}{rcl} 0 & : & x < 0, \cr x & : & 0 \leq x . \end{array}\right.$
さて,関数としてこの全体を NN という名前で呼ぶことにしよう. つまり,$\mbox{output } y = \mbox{NN}( H, \mbox{ input } x)$ という感じだ.
ただし $H$ はこの NN のパラメータ $C_1 \cdots C_3$, $b_1 \cdots b_3$ を適当に一つにまとめたデータだ. 今回は,たとえば下図のようにまとめればよいだろう.
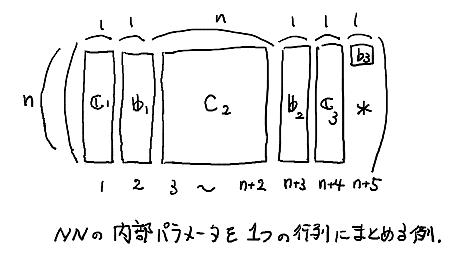
このようにパラメータを一つの量としてまとめておくことで,これらのパラメータを同時に更新して NN を「改善」する手法が使いやすくなる.
具体的には,プログラム中で gradient を利用「できる」ことがその恩恵にあたる.
NN をどう使うの?
使い方は簡単だ.
まず,既知のデータから一つ適当な $x_k$ を関数 NN に入れると値が出てくるので,これとデータに入っている $g(x_k)$ (教師情報. 出力の正解のこと)を比べて誤差 $f(H, x_k)$ を計算する. 今回の場合,$x_k$ も $g(x_k)$ もスカラーなので,誤差関数 $f$ もスカラーで正なものとして定義しておくと良いだろう.
そして,この誤差 $f(H, x_k)$ が小さくなるように NN のパラメータ $H = ($ $\boldsymbol{C}_1$, $\boldsymbol{b}_1$, $C_2$, $\boldsymbol{b}_2$, $\boldsymbol{C}_3$, $b_3$ $)$を修正するのだ!
注: どうやって? と思うかもしれないが,これは「最小化問題」という古典的な(情報系の)問題で,いろんな技術が開発されている. 今回は一番シンプルな勾配法
$\left\{\begin{array}{rcl} H_{ \mbox{new}} & = & H + \Delta H, \cr \Delta H & = & - \gamma \, \mbox{ grad}_H \, f(H) . \end{array}\right.$
を用いよう. ちなみにこの式中の $\gamma > 0$ は学習係数と呼ばれるパラメータに対応してて,スカラー関数 $f$ に対して数値計算的には
$\gamma = f(H) / \left\| \mbox{grad}_H f(H) \right\|^2 $
という感じに計算する. ただし,この計算式をそのまま使うと $\mbox{grad}_H f(H) \cong \boldsymbol{0}$ の時に不安定になるので, $\mbox{grad}_H f(H)$ がある程度小さい時はこの $\gamma$ を適当な数字に決めてしまうなどの対応をしておくと良い.
そしてこの修正プロセスを,データの個数だけ繰り返せば良いんじゃね? というのが全体の使い方だ.
これでうまくいくのかって? まあ,まずはやってみるのが一番だ.
実際にやってみる
あとは少しずつプログラムを作っていくだけだ. まず,今回用いる Julia のパッケージ/ライブラリとして,インストールしてないものをインストールしておこう.
|
|
まあなかなか大きなライブラリなので,少し待たされる.コーヒーでもいれよう. また,このインストール作業は一回だけやっておけば良い.
次に、問題のパラメータを設定してしまおう.
|
|
次に、対象関数を教師情報の代わりに作ってしまおう.
|
|
プロットして確認しておこう.
|
|

次に,NN を作ってしまおう.gradient を計算するライブラリの都合を考慮して,(データに多少無駄が入るが)次のような感じになる.
|
|
誤差の計算は,単なる(スカラー値の)差の二乗にしておこう.
|
|
さてそろそろ計算そのものの準備に入ろう.まずは,肝心のパラメータ群の初期値を乱数で適当に生成する.
|
|
10×15 Array{Float64,2}: 0.324676 -0.317048 -0.383325 … -0.192679 0.251531 -0.355099 0.356019 -0.24486 0.183784 -0.288493 -0.318379 -0.357167 0.085179 0.248078 0.398218 0.339936 0.288824 -0.465594 -0.23337 -0.159247 -0.37432 0.222478 -0.359834 0.316811 -0.095615 0.319995 -0.425803 -0.0563131 0.476165 0.330165 -0.126157 0.139713 0.375416 … -0.00224324 -0.359773 0.466978 -0.351099 -0.364506 -0.139314 0.0908853 -0.332693 0.439637 0.452288 -0.425559 0.354947 -0.353736 0.0133133 -0.166082 -0.280295 0.465438 -0.266818 0.128114 0.0609274 -0.358294 -0.375012 0.481077 -0.357738 0.290997 0.249286 -0.0404348
このパラメータで関数 NN はどうなっているかをプロットして見ておこう.
|
|

乱数で作っているので当たり前だけど,ターゲット関数とはまるで異なるよな.
では,肝心の計算だ! かなり簡単だぞ.
|
|
Progress: 100%|█████████████████████████████████████████| Time: 0:00:49
今回のように学習係数 $\gamma$ を自動調整するとなぜか計算が速い(原理的に計算量は変わらないように思うのだが…)
ちなみに,教師データとして関数 predict を使っているのは「ズル」と言えばずるいので,真面目にやるならデータを作っておこうw
さてうまくいったのか,グラフを見てチェックしよう.
|
|

おお! なんかうまくいったことがわかる. なんにも考えないでループを回してうまくいくんだから,これは確かに「いい」方法なのかも,と思わされるよな.
ちなみに,修正後のパラメータ群を以下のようにしてちょっと見てみると,
|
|
10×15 Array{Float64,2}: 0.30918 -0.333525 -0.383325 … -0.192679 0.251531 0.991079 0.300295 -0.308322 0.183784 -0.288493 -0.318379 -0.357167 2.2015 -0.680849 0.397532 0.183212 -0.271072 -0.465594 -0.23337 -0.159247 -0.373324 0.0344011 -1.64666 0.316811 -1.06149 0.727758 -0.426603 -0.683817 0.171372 0.330165 3.31537 -1.02036 0.375416 … 0.551363 -1.57333 0.466978 -0.351099 -0.364506 -0.138739 0.129592 -0.472502 0.439637 0.425336 -0.452835 0.354947 -1.02799 0.659472 -0.166082 -1.88422 1.29059 -0.266901 0.0836234 -0.0468442 -0.358294 -2.20279 1.50933 -0.358366 0.291126 -0.0803843 -0.0404348
という感じで,意外に数字が散らばっていて,その特徴を掴むにはまたちょっと工夫が要りそうだ.
レポート
以下の課題について能う限り賢明な調査と考察を行い,
2020-AppliedMath7-Report-14
という題名をつけて e-mail にて教官宛にレポートとして提出せよ. なお,レポートを e-mail の代わりに TeX で作成した書面にて提出してもよい.
課題
図
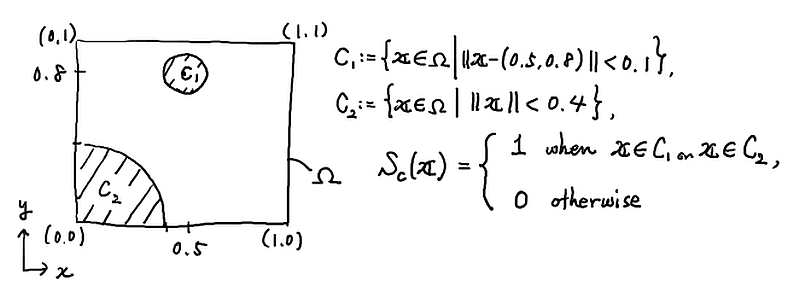
の中で定義される関数 $S_c$ に従ってデータ $D = \{ \boldsymbol{x}_k, \boldsymbol{y}_k = S_c(\boldsymbol{x}_k) \}_{k=1}^N$ が $N \cong 10,000$ 程度で得られているとする($N$ は好きに設定して良い).
関数 $S_c$ が未知である想定のもとに,今回の授業と同様に NN を構成し,データ $D$ を使ってパラメータを学習させて,NN が関数 $S_c$ を近似的に構成するようにしてみよ.
注: この問題は,2つのパラメータ( $\Omega$ 上の座標 $(x,y)$ のこと)から 2種類の分類(0 か 1 か)ができるように,という機械学習を行うことに相当する.現実の問題にこの考え方を使えないか,検討してみよう.例えば,4つの数字と「その花の種類(3種類ある)」をデータ化した UCI の iris データ をもとに,その4つの数字だけから花の種類を当てられるようにできるだろうか.
(興味のある人向け) 実際に機械学習を行おうと思ったら,適切に設計されたライブラリ・フレームワークを利用したほうがよいだろう. Julia の場合は Flux というパッケージ(ライブラリ)があるので, 機械学習: 入門2 with Flux package を参考に試してみよう.