データベース

データの取り扱いについて
ある程度大規模だったり複雑だったりするデータを処理することはコンピュータではよくあることだ. よくあることであるので,こうしたデータを「どのように保存するか」「保存したデータを どのように取り出すか」という視点できちんと捉えて一定の規格にのっとってこれらを共通化することで,典型的な作業についてはプログラマがいちいち細かいことを考えないで済ませることができるようになる(そもそも論で言えば OS が提供する機能はある程度こうしたものばかりだが.). こうした考え方が一体の形をとったものが以下に述べるデータベースソフトウェアなどと総称されるもの,と思えば良い.
データベース(ソフトウェア)とは
大雑把に言えば,収集されたデータの集合体そのものを指す. または,データを保存すること,また,一定のルールにそって蓄積したデータの中から必要なデータを抽出すること,等のデータ収集かつ抽出の機能を持ったプログラムやライブラリをデータベースソフトウェア,データベースライブラリなどと呼び,その略称としてデータベースと呼ぶ.
データベースソフトウェアの強みはまずはその汎用性,つまり,操作などが共通であることにある. また,データを取り扱うことに特化していることにより,操作によるデータ破壊やデータ損失に備えた機構をもたせていたり,メモリやストレージの利用効率が高くなっていたり,検索などの操作が高速であったりと,その高機能性も利点である.
ただ,こうした高機能性はソフトウェアの肥大化,煩雑さと強い相関があり,ライトユーザーからみるとかえって使いにくい,わかりにくいという欠点にも繋がる.
注意 :
よって,「そのデータ構造にのみ」特化した賢いプログラムの方が
汎用データベースソフトウェアよりも優秀であることは充分にありうる.
対象とするデータの取扱にそもそもデータベースソフトウェアを使うべきかどうか,
まずは最初に検討したほうがいいだろう.
データベースソフトウェアの種類
非常に大雑把に分けるのならば,簡易なものから非常に大規模なものまで以下のような3つに分類できるだろう.
- 表計算ソフト,単なるテキストファイル+Unixコマンド群 等々: 非常に広義に捉えるならばこれらはもっとも簡易なデータベースソフトウェアといえるだろう.
- RDBMS(リレーショナルデータベース管理システム): データベースソフトウェアの主流と言えそうなのがこれである.データの操作には主に SQL という言語が使われる. ソフトウェアとしては簡易なものはライブラリ,コマンドとして実装され,本格的なものはサーバとして実装される.
- 構造型ストレージ(NoSQL): 超大規模なデータや,リアルタイム性を重要視するような, RDB(リレーショナルデータベース)では扱いにくいデータを取り扱う. 操作が SQL でまかなえないということでもあるので,NoSQL (Not Only SQL) とも呼ばれる.
データの規模とデータベースソフトウェアの関係
データが単純,もしくは規模が小さい場合:
全データがコンソール画面 1枚に入りきるケースなど,データ規模が小さい場合は,データベースを導入する手間やデータを処理するソフト本体とデータの間にデータベースソフトウェアが挟まる分だけ,かえってコスト高になりかねない. そうした場合は無理にデータベースソフトウェアを導入しなくても良いだろう(導入してももちろん問題はないけれども). こうした場合は単なるテキストファイルにデータを納めておくとか,いわゆる表計算ソフトウェアなどを利用した方が無理がなさそうだ.
また,例えば単純な観測データが数字で並んでいるだけ,というようにデータが単純な場合はそれに特化した処理系を用意したほうが見通しもよく,処理速度や記憶容量の圧縮性などの面で多くの利点があるだろう. 数値解析,数値計算などの場合はこうしたケースが多そうだ.
データがある程度複雑,もしくは規模が少し大きい場合:
現実的な想定としては住所録やソフトウェアの様々な設定保存などがこのあたりだろう. これぐらいの規模から,データベースの利用を検討する価値がでてくる.
ただし,複雑さや規模がそれほどでもないこの段階では,
- SQLite などの,RDBMS のなかでもサーバシステムではないような軽量データベースソフトウェア.
- 単なる整理したテキストファイル + 小さなシェルスクリプトの組み合わせ
ぐらいが(人的投入コストの面からも)適切と考えられる.
データが複雑,もしくは大規模な場合:
もう少しデータが複雑,もしくは大規模なケースはこちらになる. 具体的には,会社の各種業務用データやオンラインショッピングサイトのデータ処理などが想定対象だろうか. こうした規模では主に RDBMS が使われている. ただし,近年ではコンピュータの性能向上により,単なるテキストファイル+シェルスクリプト でこうした用途も充分まかなえるとする動きもある.
データが超複雑,もしくは超大規模な場合:
データが非常に複雑だったりその構造が解析前は不明だったり,もしくは規模が サーバ 1台に収まらないぐらい大規模だったりする場合,RDB は不向きである. こうした場合は構造型ストレージ(NoSQL)サーバが使われる.
データが多いとき、データベースの効果は大きいよ
データが多くて定型的なとき、データベースは特にその力を発揮する.
SQLite
本授業で用いる SQLite とは,RDBMS のなかでも最も軽量で広く使われている(有名どころだと,firefox や android で使われている)ソフトウェアで(世界で一番広く使われている SQL エンジンだと主張している),各種言語用ライブラリやコマンドとして実装される. サーバではないため複雑なインストール作業が不要で,すぐ使えるという利点がある. また,データベース一つにつきファイルを一つ作る方式のため,バックアップなどが取り易いのも便利な点である.
データベースの操作は SQL で行うため,他の RDBMS とあまり変わらない操作が行える. ただし,データの「型」設定を要求しないという融通さを持つので,簡単に使える.
主に使われるバージョンは 2系統と 3系統であるが,ここでは 3系統(ver.3)を用いる.
ちなみに、阪大の教育計算機システムの cygwin には sqlite3 コマンドがインストールされているので、これを使って実習ができる.
資料
| 資料名 | 解説 |
|---|---|
| SQLite | SQLite の本家 web である. SQLite をダウンロードすることもできるが, cygwin や Linux ではアプリ管理システムからインストールしたほうがいいだろう. |
| SQLite 入門 第2版: 著 西沢 直木, 翔泳社(2009). |
上の本家 web でも紹介されている書籍である. 題目の通り,入門にはまさにぴったりの本と思われる. ただし,入門者には難解かと思われる内容は載っていないため 中級者以上は他の書籍なども資料として用意しておくと良いだろう. |
| ”SQLite 入門” と検索して出てくるような web. | 丁寧に書かれた分かりやすいものもあり,大変為になるので見ておくと良いだろう. |
それぞれの学習環境での状況
今回用いる SQLite3 のインストール状況は各環境で以下のような状態だ.
| 環境 | 状況 |
|---|---|
| 阪大情報教育システム Windows 10 |
Windows用に独自にはインストールされていないようだ. 今回は下記の cygwin 用を用いよう. |
| 阪大情報教育システム cygwin |
ver 3.30.0 がインストール済み. 今回はこれを使っても良い. |
| 阪大情報教育システム CentOS7 |
ver 3.7.17 がインストール済み. ちょっと古いが今回はこれを用いても良い. |
| 各自PC CentOS7 obtained at OSBoxes |
ver 3.7.17 がインストール済み. ちょっと古いが今回はこれを用いても良い. |
| 各自PC Windows | Windows 用 sqlite3 バイナリ からダウンロードして ver 3.32.2 をインストールできる.今回はこれを使っても良い. |
| 各自PC cygwin | 未インストールならばインストールしておくと良い.package としてインストールできる.今だと ver 3.30.0 あたりがインストール可能だろう. |
| 各自PC Mac OS X | 通常は未インストールの様子.インストールしよう. “homebrew sqlite” などと web 検索して調べて自分でインストールしよう. |
SQLite の操作
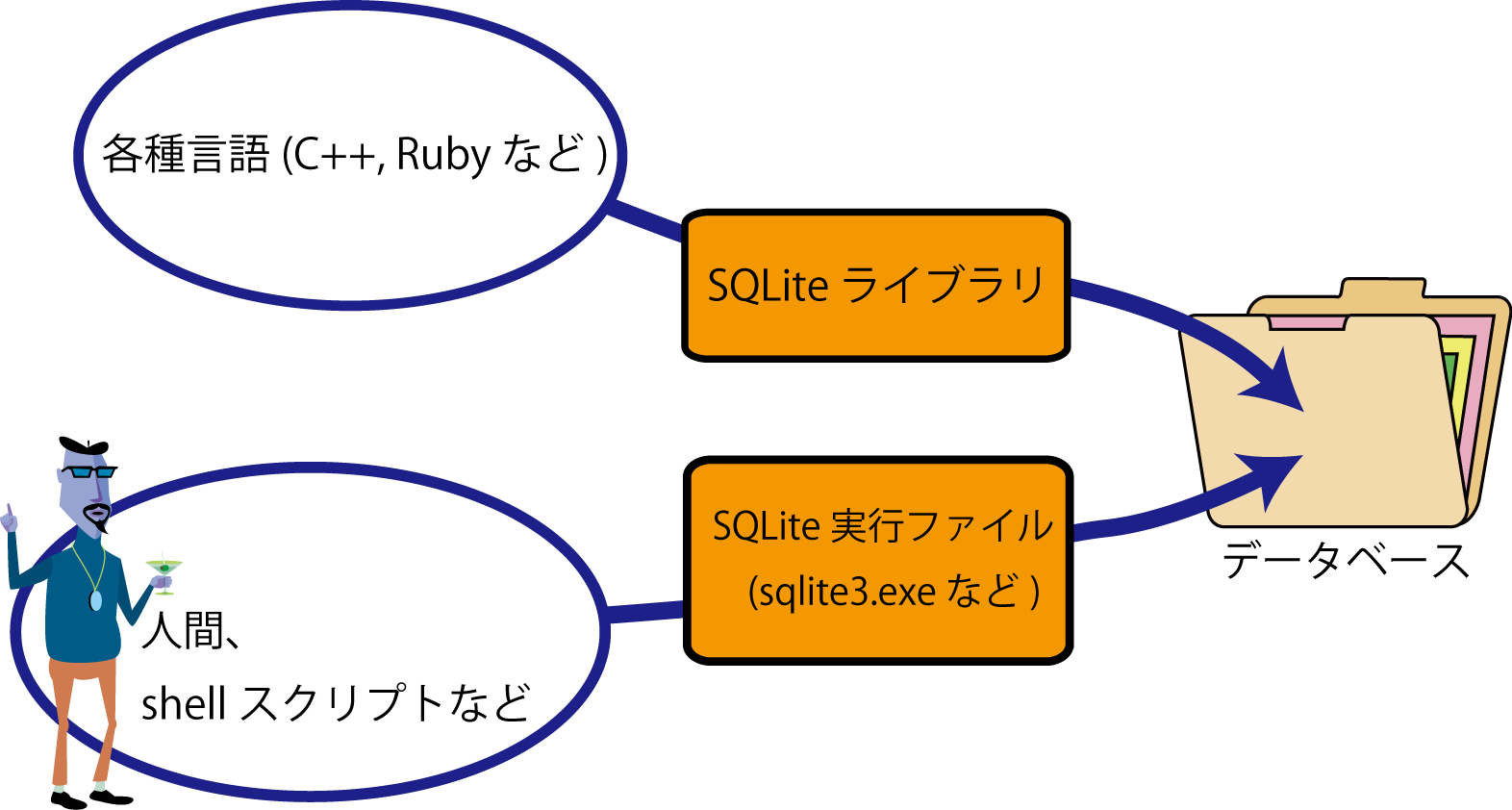
データベースの操作を一括管理するサーバがあるわけではない.
他の著名な RDBMS はソフトウェアとしてはサーバ形式をとることが多い.
これは、ネットワーク越しにデータベースを扱うためにはこの方が好都合だからで、
ある程度大きな規模のデータベースでは(利用者が複数になることもあり)必要な形式といえる。
しかし、サーバをインストール、稼働させるためにはシステムの管理者権限が必要だったり、特殊なアカウントを用意したりせねばならず、利用するための労力は小さくない.
これに対し、SQLite はサーバ形式ではなく、単なるコマンド、もしくはライブラリからデータベースを操作するという単純な仕組みである.
本授業では、もっとも簡単なコマンドからの操作を持って学ぶものとする.
SQLite で用いる言語
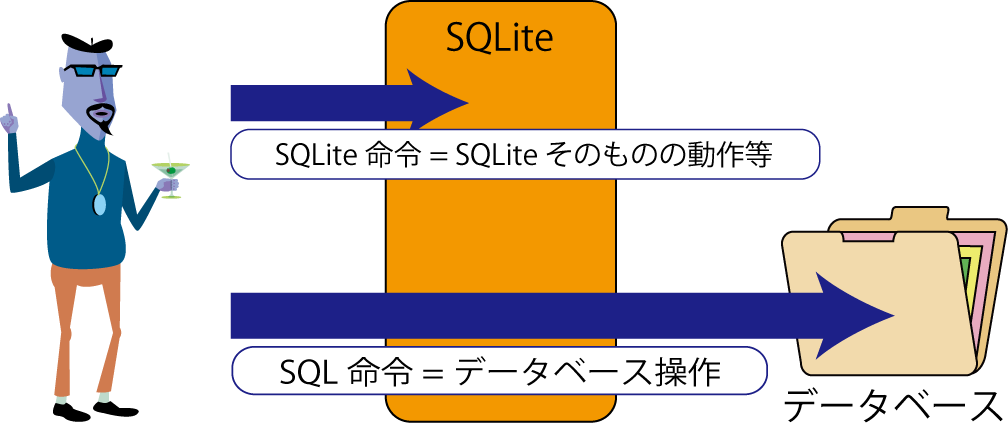
SQLite を使っての操作には、以下の二種類があり、それぞれについて異なる言語(コマンド)を用いる.
- SQLite そのものの操作:
各種設定の変更、表示など.SQLite コマンド と呼ばれるコマンドを用いる. SQLite コマンドは .(ピリオド)で始まる単語であることが特徴である. - データベース処理:
データベースへの操作.テーブルの作成、データの登録、データの抽出など、本来のやりたいこと. これには SQL コマンド を用いる.
SQL コマンドはあるていど規格化されており, 標準的な機能を使うのであれば他のデータベースソフトウェアと同様に扱える.
SQLite におけるデータの取扱い
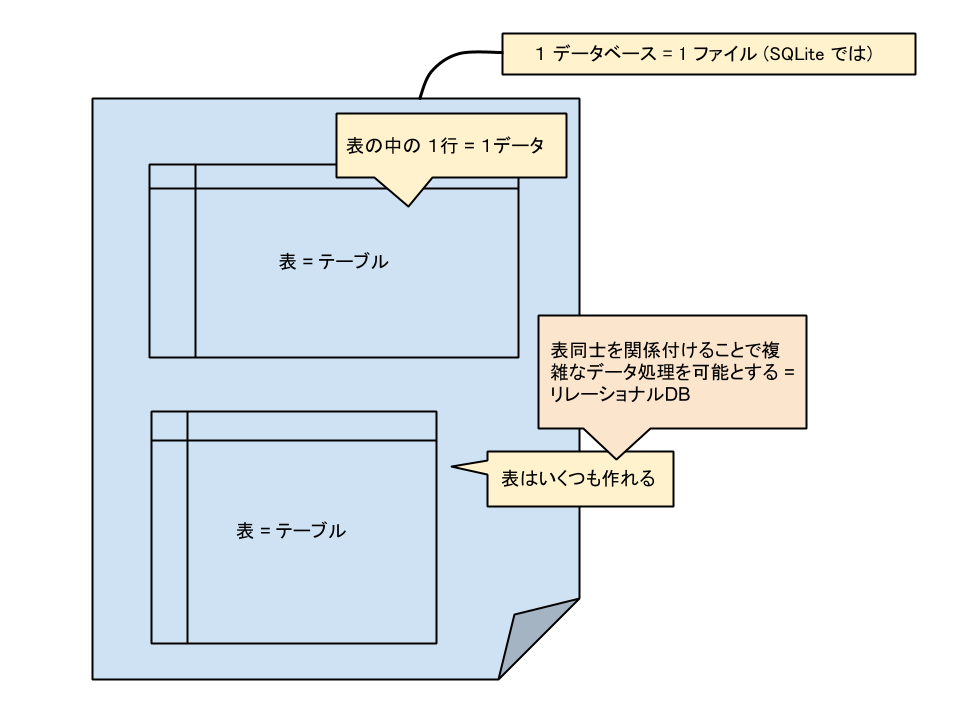
通常は、RDBMS では一つのデータベースの中に,テーブル(表)を複数作り,
そのテーブルの中に一行ずつ決まった形式でデータを入れる(さらに、こうしたデータベースを複数作る).
テーブルは注目するデータの分類ごと(例えば顧客リストを並べて作る顧客テーブル,商品リストを並べる商品テーブル,そして誰が何を買ったかという購買リストを並べた購買テーブルなど)に作ることが想定されており,それらを関係付ける(別のデータベースのテーブルと関係づけることも出来る)ことで全体の情報がまとまることになる. このように,リストアップできる情報をテーブルとして並べ,それらの関係をまたテーブルにする,というように[関係性]で全体の情報を表すのが大雑把に言えばリレーショナルDB である.
なお、SQLite では一つのデータベースを一つのファイルに入れるので分かり易いし、バックアップも取りやすい.
この授業では、売上を管理するデータベースを想定してみる.
具体的には、一つのデータベースの中に 商品情報のテーブル、顧客情報のテーブル、売上記録のテーブルを作ってみる.
そのつもりで以下を読み進めてみよう.
環境依存のトラブルが有る場合の回避
少し古めの sqlite3 on cygwin では sqlite3 が「文字端末画面で少し変わった表示をしようとするとおかしくなる」問題がある.
Using SQLite3 with Cygwin に技術的な議論と解決方法があるので気になる人は読んでもらうとして、トラブルにあう場合はとりあえずインストールされている sqlite3 を使うのを諦め、一時的に新しい sqlite3 を用意して使うことにしよう.
具体的には以下のように作業しよう.
- Windows の “コマンドプロンプト” を起動しよう.
今回の作業専用ディレクトリを作ってそこに移動しよう.例えば
z:\sqlを今回の作業専用ディレクトリとするならば、 コマンドプロンプトの中で1 2md sql cd sqlとすればよい.
- Windows 用 sqlite3 バイナリ をダウンロードして、解凍し、出てきたファイル(3つほどあるはず)を今回の作業専用ディレクトリに置こう.
- 以降は、このコマンドプロンプトで下記の作業を行おう.
SQLite3 の起動、終了
コマンドから SQLite を起動する = データベースへの接続 or データベースの作成
SQLite のコマンドは、引数に文字列を与えるとその名前のデータベース(ファイル)に接続しようとする。 もしそのデータベースがなければ新規にデータベースが作られる。 たとえば db1 という名前のデータベースを作るとすると、 (今回は, 上で示したコマンドプロンプト中で)
1.\sqlite3.exe db1
と入力すればよい. sqlite (ver.3) が起動してコマンド受付モードになる. プロンプトが sqlite> に変わることで判別がつくだろう.
実習
上のようにして SQLite を起動しよう.
起動したらそのままにして、次の実習まで先へ読み進めよう.
SQLite の終了
起動した SQLite を終了するには、
|
|
もしくは
|
|
でよい。 それぞれ一文字目がピリオドであることに注意しよう。
SQLite3 の設定
SQLite を起動してから、まずは
|
|
としてみよう. 現在の設定状況が以下のように表示される. もちろん、内容は設定により異なるので、これと同じとは限らない.
|
|
見て推測できるように、いろいろ設定はあるが、まずは以下の設定だけでもしておくと何かとわかり易くなるので, 手でデータベースにアクセスするときはこうしておこう.
|
|
これは、画面出力をわかりやすくする設定であり、対話的に操作しているときはなにかと助かるだろう.
実習
.show コマンドを試しに実行したのち、.explain on 設定をしておこう.
SQLite3 でのテーブル「単独」操作
テーブルを作る
リレーショナルデータベースの中身の本質はデータを列挙した塊であるテーブルである。 ただし、一つのテーブルの中に列挙されるデータはすべて同じ構造をしている必要がある。 そして、その構造をテーブル作成時に定義する必要がある。
SQLite でのテーブルの作成時におけるデータの定義は簡単だ. しかもデータの型の定義を省略することもできるので、慣れていないうちはテーブルの作成は次のようにすると良いだろう.
|
|
注意
SQLite3 は ; (セミコロン)を入力するまでは命令の解釈を待つので、長いコマンドを
全部 1 行で入力する必要はない.人間にとって分かり易いところで改行して入力を続けると良いだろう.
注意
慣習として SQL 命令は大文字で表記されるが、SQLite3 は小文字でも問題なく受け付ける.
対話的に入力するときは面倒だろうから、気にせずに小文字のままで入力してしまうのが簡単だろう.
注意
ここでは 変数名1 を id と決めてしまっているが、実は自由に決めて良い.
ただし、慣れていないうちはこうしておくとなにかと後で助かるだろう.
注意
id の後の INTEGER PRIMARY KEY AUTOINCREMENT の意味は、
id という変数を「整数」で「これを主キーとして」「データ削除後の再利用なし」にするという意味である.
主キーというのは、大雑把に言えば、その表の中でこの変数に対するデータは唯一であることが保証される変数である、という意味である.
実習
次のようにして、商品情報の一つ目のテーブルとして fruits テーブルを作っておこう.
|
|
上の注意で書いたように、一行で一気に入力する必要はない.
最後の ; (セミコロン) を打つまでは命令は実行されないので、適当なところで改行するなどして、見やすい入力を心がけよう.
テーブルを削除する
作ったテーブルを削除するのは簡単で、
|
|
とするだけでテーブルを削除できる.
注意
この簡単な操作であっさり大量のデータを失うことがあるので、要注意!!
データベースにどんなテーブルが有るか見てみる
一つのデータベースには複数のテーブルを格納できる.
そこで、データベース中にどんなテーブルがあるか調べる方法を書いておこう.
これは .tables 命令(SQLite 命令)を使って
|
|
とするだけでよい.
実習
上の .tables コマンドを用いて、確かに fruits テーブルが作られていることを確認しよう.
テーブルにデータを追加する
さて、データの追加について話そう. 存在するテーブルにはデータを追加できる.
データの追加は INSERT 命令を使って以下のように行う.
|
|
注意
こうしてデータを追加すると、変数 id には連番で自動的に数字が入力される.
実習
次のようにして、 fruits テーブルに商品データを登録しよう.
|
|
注意
もちろん、他のテーブルやデータベースからデータをコピーしてくる方法や、他の普通のファイルからデータをコピーしてくる方法なども有る.
必要になったら調べよう.
テーブルのデータを表示する, 取り出す
テーブルに入っているデータをまずは見てみたいという場合は SELECT 命令を使って以下のようにする.
|
|
注意
上の設定で .explain on としているとこの表示が少しだけ分かり易いようになる.
実習
上の SELECT コマンドを用いて、fruits テーブルにデータが登録されて
いることを確認しよう.
うまくいっていれば、次のように表記されるはずだ.
|
|
さらに、条件を指定してデータを見てみたいという場合は、SELECT 命令に WHERE 句を追加して以下のようにする.
|
|
WHERE のあとに続く条件は柔軟に指定できる.
ここで説明するには多すぎるので、まずは以下の二例をみて感覚をつかもう.
実習
次の SELECT コマンドを用いて、fruits テーブル中で単価が 1000円以上の品をリストアップしてみよう.
|
|
うまくいっていれば、次のように表記されるはずだ.
|
|
さらに今度は、fruits テーブル中で名前が “ほにゃららnana” というものをリストアップしてみよう.
|
|
これもうまくいっていれば、次のように表記されるはずだ.
|
|
注意
LIKE 中の % は「任意の文字列」という意味を持つ.詳しくは調べよう.
さらに、項目すべてではなく、一部の項目だけ見たいという場合は SELECT 命令のあとに * ではなく、項目名を列挙する.
|
|
実習
次の SELECT コマンドを用いて、fruits テーブル中の単価「のみ」リストアップしてみよう.
|
|
うまくいっていれば、次のように表記されるはずだ.
|
|
テーブルのデータを修正する
テーブルに格納されているデータを修正するには、REPLACE 命令と UPDATE 命令が使える.
都合に合わせて好きな方を使おう.
まず REPLACE は、次のように使う.
|
|
注意
REPLACE 命令を使った時、その id番号 をもつデータがない場合、そのデータはその id番号で新規に「登録」される.
その意図がない場合は後々の混乱のもとになるので、本当に修正しかしたくない場合は次の UPDATE 命令を使ったほうが良さそうだ.
次に、UPDATE の使い方だが、次のようになる.
|
|
注意
WHERE 以降を省略すると、データ全部が対象となってしまうので気をつけよう.
実習
次のように UPDATE コマンドを用いて、fruits テーブルのデータの中の、water melon の価格を 2000 に修正しよう.
|
|
うまくいっていれば、SELECT コマンドで次のように表記されるはずだ.
|
|
実習(応用)
さらに、次のように UPDATE コマンドを用いて、単価が 300円未満の商品を倍に値上げしよう.
|
|
うまくいっていれば、SELECT コマンドで次のように表記されるはずだ.
|
|
テーブルのデータを削除する
テーブル中のデータを削除するには、DELETE コマンドが使える.
|
|
注意
これも WHERE 以降を省略すると、データ全部が対象となる.
つまり、データが全部消えてしまう! ので、間違えてそう操作しないよう気をつけよう.
実習
次のように DELETE コマンドを用いて、fruits テーブルのデータの中の、
strawberry についての情報を削除しよう.
|
|
うまくいっていれば、SELECT コマンドで次のように表記されるはずだ.
|
|
注意
一度使われた id 番号 2 が欠番になっていることに注意しよう.
実習
次のように INSERT コマンドを用いてデータを追加し、
欠番 id がどのように扱われるか把握しよう.
|
|
うまくいっていれば、SELECT コマンドで次のように表記されるはずだ.
|
|
注意
自動連番機能を用いると id 番号 2 が欠番のままになっていることに注意しよう.
ファイルからデータを読み込んで追加する
.import コマンドで、ファイルに書いてあるデータをテーブルへ追加できる.
その .import の使い方は次のようになっていて、
|
|
そしてファイルへのデータ記載方法は、次のルールに沿う.
- 1行に1データ
- データ中の要素は、colseparator (デフォルトは | だ.
.showコマンドで確認せよ)で区切る. - 改行コードは rowseparator (デフォルトは \n だ.これも
.showコマンドで確認せよ).
実習
次のように .import コマンドを用いて、ファイルからデータを読み込もう.
まず、sqlite3 コマンドを実行しているディレクトリにファイル(この例では add-fruits.txt という名前にしておく)を作り、次のような内容を書き込もう.
|
|
それから、sqlite の中で次のようにして読み込む.
|
|
その後、select * fruits; コマンドで、確かにこれらがデータとして追加されていることを確かめておこう.
SQLite3 でのテーブルの「相互作用を考慮した」操作
データベースでのテーブル相互作用の基本は、何かの項目を共通キーとしてテーブルを合体させることである. 難しくはないがやってみないと実感しにくいので、実習を通じて学ぶとしよう.
準備
実習を通じて学ぶために、少し準備をしよう. 具体的には、もう二つ、他のテーブルを同じデータベースの中に作成しよう.
実習
次のように CREATE コマンドと INSERT コマンドを用いて、今のデータベースの中にもう2つのテーブルを作っておこう.
まず一つ目は、顧客リストを並べた customers テーブルである. 顧客として 3人ほどデータを入れておこう.
|
|
SELECT 命令で中身をみると次のようになっているはずだ.
|
|
二つ目は、売上リストを並べた sales テーブルである.
売上リストは、
id, 顧客id, 商品id, 売れた個数
という並びでデータを格納することにしよう.
|
|
としてテーブルを作ってから、例えば次のような 5 回の売上げ情報を入れておこう.
|
|
SELECT 命令で sales テーブルの中身をみると次のようになっているはずだ.
|
|
注意
この sales テーブルは他のテーブルの情報があって初めて意味があることに注意しよう.
共通情報をもとにテーブルを合体させる
これでこのデータベースには計 3つのテーブルが有るはずである.
一応、.tables コマンドで
|
|
とすると、
|
|
と出力されることを確認しよう.
この 3つのテーブルのうち他のテーブルの情報を引用する形になっているのは sales テーブルであるので、
sales テーブルに他のテーブルの情報を合体(join)させてみよう.
具体的には、SELECT と同時に JOIN 命令を使って、合体させたテーブルから情報を取り出す形をとる.
WHERE 句に似た使い方と言えばわかるだろうか.
文法としては次のような感じだ.
|
|
注意
読み易いように上のコマンドは適当に改行して二行になっているが、行末の ;(セミコロン)の有無を見れば分かるように、SQLite からみたら 全体で 1行のコマンドである.
最後の = で繋がれている二つの項目が、このテーブル間で共通に扱われる情報である. まあ、次の実習をやってみるとわかりやすいだろう.
実習
次のように, sales テーブルの売上情報で、共通に入っている顧客の id を利用してテーブルをつなげて、顧客の名前が見えるようにしてみよう.
|
|
すると、次のような感じでデータが得られるはずである.
|
|
全体の、第2項目(sales テーブルの customer_id) と第5項目(customers テーブルの id)が一致していることを確認しておこう.
これでは見にくい、というようであれば出力を見やすいものだけにすればよい. 例えば次のような感じだ.
|
|
次のような出力が得られるはずだ.
|
|
注意
テーブルを合体させると、同じ項目名が使われていることがある.
これを曖昧に記述して命令するとエラーになるので、そういう時は上のように テーブル名.項目名 として指定して、区別をする.
実際、上の例でも SELECT の対象で sales.id として区別しているのに注意しよう.
JOIN はいくつでもいける!
JOIN はいくつでもテーブルを合体させられる. 単に後ろに続けて記述すればいいだけである. 次の実習で確かめよう.
実習
sales テーブルの売上情報で、顧客の名前だけでなく、商品の名前や単価も見えるようにしよう.
具体的には先の例にさらにもう一回 join をすれば良い.
|
|
すると、横に長いが, 次のような出力を得るはずだ.
|
|
わかりやすくするならば、次のような感じか.
|
|
すると、次のような分かり易い出力を得るだろう.
|
|
これをみれば、例えば第4回目の取引きでは tom が200円のバナナを4本買っていったことがすぐわかる.
注意
こんな面倒なことをしないで、上の表そのものを用意して、データを足していけばいいんじゃないかと思う人もいるだろう.
しかしそれをやると、途中で何かを変更すると過去のデータとの一貫性を失ってしまったり、
ある欄では tom と書き他の欄では ton と記載ミスすると別人扱いになってしまったりするのだ.
商品情報は商品テーブル単独で、顧客情報は顧客テーブル単独で管理でき、かつ、それらの情報を
他のテーブルから参照できる、というのが RDB のポイントなのである.
これはデータの管理の「安全性」を意味する.
データが多く、複雑になればなるほどこのことの重要性は増すだろう.
さて、さらに, データをただ見るだけではなくて、計算するなどの加工を少ししてみよう.
|
|
すると次のように、単価x個数=小計 もリストアップできる.
|
|
(応用)
さて、さらに、誰にいくら請求するべきかも合計を見てみよう.
顧客情報をもとにまとめるわけだが、これには GROUP BY という命令を使う(詳しくは各人で調べよう).
なお、合計には単なる SUM という命令が使える.
|
|
すると、次のような出力を得ることができる.
|
|
これで、だれに合計でいくら支払ってもらえばよいか、一目瞭然である.
最後に
今回は SQLite をコマンドラインから直接操作して RDBMS の入門的な部分を理解できるような内容とした. RDB を実用に供する場合は,ライブラリ経由かサーバ経由となるため,さらに理解しないといけないことが増えるが,基本は同じである. そういった際によくわからなくなったら,今回のように直接コマンドラインから該当する操作をしてみて,実際に何が起きるか確認してみるのも良いだろう.
レポート
以下の課題について能う限り賢明な調査と考察を行い,
2020-AppliedMath7-Report-10
という題名をつけて e-mail にて教官宛にレポートとして提出せよ. なお,レポートを e-mail の代わりに TeX で作成した書面にて提出してもよい.
課題
- 上の実習を続けて、さらに、どの商品が合計でいくつ売れたか、を出力させてみよ.
- SQLite で、データベースの情報をテキストファイル等にバックアップしておく方法を調べよ.
- SQLite のデータベースを GUI で操作できるアプリケーションが多数存在する. そういった物を探し,そのうちの一つで良いので実際に操作して試してみよ.
- 自分の生活の中で SQLite を利用すると便利になりそうなシーンがないか、考えてみよ.