フィルタ
フィルタとは,入力したデータ(主にテキストデータ)を加工して出力するプログラム一般のこと.
unix には単純な機能を持つフィルタが多い. これらをパイプでつなげると,複雑で大量のデータ処理が簡単にできる.
フィルタを使うと複雑なことがとても簡単に!
フィルタを(前回紹介した)パイプで繋いで複雑なデータ加工が簡単にできる
単機能なフィルタ
まず,単純な機能のフィルタを紹介する.
cat : ファイルの中身を標準出力に出す
cat ファイル名 とするとファイルの中身を標準出力に吐き出す.
複数のファイルを与えることも出来て、cat ファイル名1 ファイル名2 ファイル名3 などと出来る.このときは、順番に中身を標準出力に吐き出す(本来はこのようにして複数のファイルの中身を「連結する」フィルタである).
ファイル名を与えてないときや,ファイル名として “-” (ハイフン)を与えたときは、標準入力を読込んで出力する.
利用方法としては、
- 複数の結果をまとめる
- オプションを使用して「出力に行番号を与える」
- オプションを使用して「空白行をまとめる」
- オプションを使用して「目に見えない文字を見えるようにする」
rsh(ネットワークの向こうのコンピュータを操作する命令)などと組み合わせて 「ネットワークを経由してファイルをコピーする」
などがよく知られている.以下、例を見よう.
実行例(1)
|
|
とすると,出力結果に行番号を簡単につけられる.
実行例(2)
|
|
とすると,file1 の中身に file2 の中身を続けた結果を sum-file に出力できる(このようにファイルを連結するのが cat の本来の機能).
実行例(3)
|
|
とすると,ネットワーク先のマシン “hoge”
上の
“dummy.txt”
というファイルに出力結果を書込める(ただし,rsh を “hoge” というマシン上で実行する「許可」設定が必要である).
tee : 標準入力からもらったデータを「標準出力」と「ファイル」の両方に出力する
上に書いた通り(前回のパイプの実例でも紹介した)、標準入力からのデータを標準出力とファイルの両方にコピーして出力する.
なお、通常はファイルは「上書き」されるが、
-a というオプションをつければ「追加出力」になる.
実行例 (1)
|
|
“d1.txt” ファイルの中身を “d2.txt” にコピーしつつ、画面で内容を確認出来る.
うまく alias と組み合わせての使い途があるかもしれない.
実行例 (2)
|
|
とすると,出力結果に行番号をつけたうえで,ファイル “dummy.txt” に結果を書込みつつ,同時に画面で確認できる.
grep 一族 : 与えた「パターン」を含む箇所を検索する
標準入力のデータや指定したファイルの中から、与えた「パターン」を含む行を検索する.
文法としては、
grep パターン ファイル名 とするとそのファイルの中からパターンを探し、
(cat 同様)
ファイル名を与えてないときやファイル名として “-” (ハイフン)を与えたときは、標準入力を読込んでその中からパターンを探す.
フィルタとしては,通常は

という使い方になるだろう.
なお、検索パターンについては、 基本正規表現( 正規表現 についてはこのあとすぐ学ぶ) を使って表す.
実行例
例えば,emacs を使っている状態でその pid を知るには,
|
|
とすれば該当行だけが表示されるので簡単にわかる.
さらに,pid だけを出力したければ,
|
|
などとすればよい.
なお、awk のこの使い方もすぐあとの
(おまけ) awk の機能のホンの一部分
で学ぶ.
grep のオプションはたくさんあるが、とりあえず知っておいたほうが良いものだけでも書いておこう.
| オプション | 解説 |
|---|---|
-i |
探すパターンの、大文字小文字の区別をしない |
-n |
パターンが見つかったファイルの中での行番号を示す |
-r |
各ディレクトリ以下のファイルを再帰的に読む |
実習
上の実行例を参考にして, 「狙ったプラグラムの pid を調べてそれを用いて kill する」 動作を 1行で行うにはどうしたらよいか考え,実際にやってみよう. 具体的には,
emacs を端末内で
|
|
として起動してから、emacs の中で C-z として emacs を停止状態へ持ち込んでから、
たった 1行の操作でこの emacs を kill せよ
などということになる.
もちろん,他のシェルや端末でこの emacs の pid を調べて操作するのは反則だし,
ジョブ制御による kill %1 や killall コマンドを使うのも無しとして考えよう.
なお、前回学んだ、 先読み評価(コマンド置換) がきっと便利に使えるだろう.
目で探す代わりに grep などを多用しよう
コンピュータを使っていると、 データの中で該当する箇所を探す機会は意外に多い. これを「目」でやると、効率は悪いし、見逃しやすいし、大変に目にも悪い. 検索には grep などをバンバン使おう.
grep 一族の他の方々
grep 一族には(見かけ上)他のプログラムがある. 慣れてきたら使い分けるとなにかと便利なので,頭の片隅にいれておこう.
| 氏名 | 性格 |
|---|---|
egrep |
パターンに「拡張正規表現」を使う(すぐこのあと、正規表現 のところで学ぶ). grep -E と同等のはず. |
fgrep |
パターンを「単なる文字列」として扱う. つまり,正規表現「無し」バージョン. パターンが正規表現で解釈されると困る場合はこちらで. しかし, fgrep は必ずしも高速ではない( fgrep の f は fast ではなくて fixed- の頭文字である). grep -F と同等のはず. |
zgrep |
圧縮したファイルを解凍してから,その中身を検索する. 古い環境だとこのコマンドが無いかも. grep -z と同等のはず. |
sort : 「順番に」並べ直す
与えられた行を 「順番に」並べ直す フィルタである. データを処理の第一歩として、非常に頻繁に使うだろう.
tips: 並べ方のルールは、デフォルトでは「辞書式」順序だ.だから、数字を大きさ順で並べようと思うと意図と異なる結果になる.そういう場合は、下の表にあるオプション -n を用いよう.
なお、意外なオプションもあるので、オンラインマニュアルを一回まじめに読んでおくと良い. 参考までに、いくつかのオプションを載せておこう.
| オプション | 解説 |
|---|---|
-k pos1[,pos2] |
対象フィールドの指定.pos1 から pos2 までの内容で比較する. pos2 を省略すると、行末まで. |
-t sep |
対象フィールドの区切り文字の指定. 例えば、”, “(カンマ) で区切りたい場合は、 sort -t ',' などとする. |
-r |
逆順にソートする. |
--debug |
対象フィールドを強調してくれる.便利. この機能を持たない sort コマンドもある. |
-u |
出力時に、重複を除去する.-c (チェックモード)の時(つまり、sort -c -u )は、「並んだ行に重複がないかをチェックする」. |
--parallel=N |
N 個のプロセッサを使って並列実行する. この機能を持たない sort コマンドもある. |
-n |
普通に数字として数値順にソートする. |
-f |
大文字小文字を同一視してソートする. |
-g |
「浮動小数」に変換して、その数値順でソートする. 便利だが遅いし、変なことも起こりうるので、「なるべく -n でやれ.これは最後の手段にしろ」とマニュアルにはある. |
-h |
人間が読めると思われる数字なら数字として扱ってソートする. 例えば、500 < 1k となる. この機能を持たない sort コマンドもある. |
-M |
対象が「月の略称」になっているとしてソートする. 環境変数 LC_TIME が英語(en)などの場合、’JAN’ < ‘FEB’ < … ということになる. |
-R |
ランダムソート.重複する同じものはきちんと同じ順序になる. この機能を持たない sort コマンドもある. |
-V |
対象がバージョン番号になっているとしてソートする. この機能を持たない sort コマンドもある. |
-c |
チェックモード(sort は通常はソートモード).データがソート済みかどうかを check する. |
-m |
マージモード(sort は通常はソートモード).個々に既にソートされている複数のファイルの内容をソートしてまとめる. 実は通常のソートモードではこの「個々に既にソートされている」前提が不要なので、このマージモードは機能としては低い. ただし、このモードは「動作が速い」. |
実行例 (1)
|
|
とすると(プロセス名が11番目に表示される場合)プロセスのリストを「プログラムの名前順に」,
|
|
などとすればプロセスのリストを「プログラムの名前の逆順に」みることができる.
実行例 (2)
|
|
とすれば,ファイルを「サイズの大きな順に」並べて見られる. HDD の容量が残り少なくて,無駄なファイルがないかな〜 と調べるときなどに有効だろう.
uniq : 重複を除去
隣り合った行が同じならば一行にまとめる フィルタである.
データに対して sort フィルタを通してから uniq フィルタを通すと,全体の重複を除去できるので,こうして使うことも多い.
sort and uniq は sort -u と機能が似ているが細かいところで違う.
一般に sort and uniq の方がオススメだ.
少しだけオプションを紹介しておこう.
| オプション | 解説 |
|---|---|
-c |
同じ行をまとめるだけでなく,「何回続いたか」も出力. |
-d |
「重複した行のみ」出力. |
-u |
「重複しなかった行のみ」出力. |
実行例 (1)
/usr/bin と /usr/local/bin にあるファイルを重複なしで全部見るには,
|
|
とすればよい.
なお、ls コマンドの挙動を alias で変更している人は,上の例の中の ls という部分を \ls と置き換えて実行しよう.
ちなみに,コマンドに \ をつけて実行するのは,「alias があってもコマンドそのものを呼び出す」という意味である.
このように、sort and uniq のコンボはもうパターンなので覚えてしまおう.
実行例 (2)
逆に, 重複しているファイルをチェックしたければ
|
|
とすればよい.
tips: 上の重複の結果は「無し」の場合がほとんどだが、もしもここに重複がある場合は少し注意が必要だ.これは重要なツールが二箇所に重複して存在するということなので…
tr: 「文字」単位での一括変換
入力されたテキストの「文字」の置換,削除,圧縮を行なうフィルタである.

として使う. 基本は「文字」単位での変換であって、「文字列」ではないことに注意しよう.
実行例 (1)
|
|
で,ls -lg の結果を,a → A, b → B, c → C … z → Z と変換して出力する. つまり,全て大文字に置換する.
実行例 (2)
そこそこ長いテキストファイル “dummy.txt” に対して,
|
|
とすると,印刷できない文字を全て消去して出力する.
この場合は、「改行」などが削られるだろう.
なお、オプション -cd と 文字クラス [:print:] についてはマニュアルを見ておこう.
実行例 (3)
|
|
とすると,入力中の改行の繰り返しを一つにまとめる. つまり,空行が消去できる.
実行例 (4)
逆に処理しやすくするためにすべての項目をバラバラにすることもできる.例えば
|
|
とすると,cal コマンドの出力がすべて行に分解される.
例えば、1年に ○月31日 は 7回あるはずであるが,上の機能を使って次のように確認できる.試してみよう.
|
|
実行例 (5)
テキストファイルの改行コードは OS 毎に異なるが、これを変換することができる.
例えば、
|
|
とすると,Windows の改行コードを持つテキストファイル wintext.txt から、Unix の改行コードを持つ unixtext.txt へ変換できる.
注: Windows, Unix, MacOS の3つの OS の改行コードを調べ、それぞれの間での変換を tr や sed を使ってどうやるか考えてみよう.
実行例 (6) 面白い例
例えば
|
|
とすると,入力ファイル “dummy.txt” 中の「単語」が出現回数と共に,出現回数の多い順に表示できる.
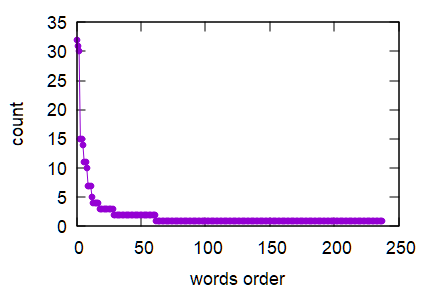
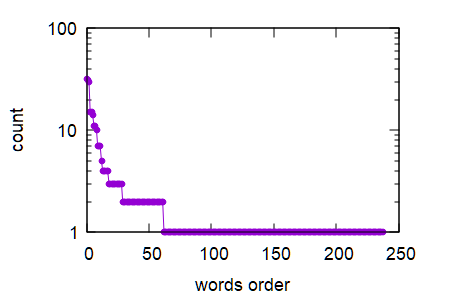
これを使うと、Zipf の法則を確認できる(Zipf の法則について調べてみよう).
余裕があるならば,適当な英文(阪大の英語 web の総長の挨拶文など)を用意してこの法則が成り立つかどうか確認してみよう.
ちなみに、総長の挨拶文を解析すると、頻出単語の top10 は以下のような感じ(単語と出現回数).
the 32
and 31
of 30
university 15
in 15
osaka 14
to 11
as 11
a 10
that 7
そして、ちなみに、横軸に出現回数の多い方から単語の出現回数を並べたグラフは次のような感じだ(素のグラフと、y軸を対数にしたグラフ). Zipf の法則が成り立っているかどうかを検証するには、データの大きさが足りないかな.
head, tail : 最初/最後の数行を出力
入力データの最初/最後の 数行を出力するフィルタである.
例えば、随時 記録が追加されていくようなファイルの変化をチェックするには,tail が役に立つので覚えておくと良い.
fold : データを折りたたむ
入力された行を決められた桁数で折り返して行分割して出力する. デフォルトは 80桁.
実行例:
例えば
“dummy.txt”
というファイルの中身をメールで送ろうと考えたとする.
そのメールが 1行あたり 40文字表示される環境でどう見えるかを荒っぽくシミュレートしてみるには,
|
|
としてみればよい.
expand, unexpand : タブ ←→ スペース 変換
機能は以下の通り.ごくたまに「あってよかった」と思う…かなあ.
タブをスペースに変換する(expand).
スペースをタブに変換する(unexpand).
pr, enscript : プリンタに出力するのにヨサゲな形式に変換
入力をプリンタに出力するのにヨサゲな形式に変換する.
pr は古めのコマンドで、まああまり美しくない.
enscript は、かなり美しく変換できる.ただし、日本語は扱えない.
実行例(1)
|
|
としてみると意味が分かるだろう.
実行例(2)
もし enscript コマンドがインストールされていれば,たとえば
|
|
とすると, “dummy.txt” を横二段組にして行番号をつけて内容を色付けしたものが “dummy.ps” という Postscript 形式のファイルに出力される. 自分で書いたプログラムを印刷するときなどはとても便利なので覚えておこう. また,enscript は Postscript だけでなく,html 形式などにすることもできる.
wc : 数える.
入力データの「大きさ」「単語数」「行数」を出力するフィルタ. これまでにも、何度もコマンドの例として紹介しているが、他のフィルタとの組み合わせて使うと意外に使い勝手が良い.
実行例
|
|
とすると,行数・単語数・バイト数 が出力される. オプションを自分で調べておこう.
nkf, iconv : 文字コードを変換する
nkf は主に日本語の漢字コードを、iconv は一般の文字コードを変換するするフィルタである.
環境によっては nkf はインストールされていないこともあるが、あると時々便利だ.
各 OS のデフォルト設定では unix, windows, mac ともに日本語の漢字コード(+改行コード)が異なるので、こうしたコマンドの存在は知っておいたほうが良いだろう. オプションや使い方等は以下の通り.
| nkf のオプション | 解説 |
|---|---|
-e, -j, -s, -w |
それぞれ、「データを EUC-JP, JIS, Shift_JIS, UTF8 に変換して」出力する. |
-E, -J, -S, -W |
それぞれ、「入力データが EUC-JP, JIS, Shift_JIS, UTF8 であると仮定する」. |
| iconv のオプション等 | 解説 |
|---|---|
iconv -f A -t B |
-f のあとの A で入力データの文字コードを、-t のあとの B で出力データの文字コードを示す. |
SJIS |
Shift_JIS コードのこと.上の -f と -t に使える. |
EUCJP |
eucJP コードのこと.上の -f と -t に使える. |
JIS |
いわゆる_JIS コード, ISO2022JP のこと.上の -f と -t に使える. |
UTF8 |
UTF8 コードのこと.上の -f と -t に使える. |
ivonv -l |
どんな文字コードが使えるか、一覧を示す. |
実行例
テキスト ‘dummy.txt’ が文字化けして読めない時,端末の表示漢字コードが EUC ならば
|
|
か、
|
|
とすれば読めたりする.
注意: lv は less や more よりも高機能のページャ(ファイルの中身を見せてくれるソフト)だ.
注意: テキストファイルの漢字コードや改行コードは OS によって異なるため、改行コードの変換も必要なことがある. 幸い,nkf には改行コードを変換する機能もついているので、そういう時は使ってみよう.
gzip, gunzip, zcat, bzip2, bunzip2, bzcat, xz, … : ファイルの圧縮・解凍
データを 圧縮・解凍・閲覧 するフィルタ.
多くの種類がある.
一般には、コマンドごとに圧縮形式やファイルフォーマットが異なる.
一般に性能の良いと言われている順に、以下に示そう.
| ファイルフォーマット | コマンド群 | 解説 |
|---|---|---|
| xz | xz, lzma など | 圧縮性能がかなり良い.比較的近年のコマンド群. LZMA2 法による. |
| bz2 | bzip2 など | gz より高性能. Burrows-Wheeler ブロックソート圧縮+ハフマン符号化. |
| gz | gzip, gunzip など | unix ではかなり標準的なフォーマット. Lempel-Ziv 77 法による. |
| zip | zip など | 一般ではかなり広く用いられている.しかし、性能はあまり良くない. |
| Z | compress, uncompress など | unix で用いられていたかなり古い圧縮形式. 性能も良くなく、今はあまり使われない. |
以下、gzip を用いて、おおよその使い方を例で示そう.
実行例(1)
|
|
とすると, dummy.txt が圧縮されて dummy.txt.gz になる. ただし,この方法だと dummy.txt は消去される.
実行例(2)
|
|
というように,オプション -k (=keep) をつけると, dummy.txt は消去されずに圧縮されて dummy.txt.gz という新たなファイルができる.
実行例(3)
|
|
とすると,ps axu の結果が圧縮されて dummy.gz という名前のファイルになる. すぐに使わない結果などはこうして最初から圧縮しておくと保管しやすい.
実習
適当に, 大きなテキストファイルなどを用意して, 圧縮しない場合, gzip で圧縮した場合, (bzip2 が使えるなら) bzip2 で圧縮した場合, (xz が使えるなら) xz で圧縮した場合、 の結果を比較して,ファイルサイズがどれくらい小さくなっているか(圧縮されているか)実際に比較してみよう.
tar : 複数のファイルをまとめて一つに
複数のファイルをまとめて一つのデータに して出力する「アーカイブ機能」をもっているのがこの tar だ(そもそも、Tape ARchive の略である).
もちろん,後で元の複数のファイルに戻せる.
ちなみに、unix の多くの圧縮ツールは(アーカイブ機能はこの tar にまかせることにして)自分ではアーカイブ機能を持っていない.
通常は次のいくつかのオプションだけ覚えておけばいいだろう.
| オプション | 解説 |
|---|---|
cvf |
複数のファイルをひとつにまとめる |
xvf |
tar ファイルを解凍して複数のファイルに戻す |
J |
(上に追加して) xz 圧縮・解凍を使う |
j |
(上に追加して) bzip2 圧縮・解凍を使う |
z |
(上に追加して) gzip 圧縮・解凍を使う |
Z |
(上に追加して) compress 圧縮・解凍を使う |
実行例(1)
例えば,そこにあるディレクトリ “data” をまるごと1つのファイル result.tar にしたい時は,
|
|
とすればよい.
ちなみに tar は圧縮はしないので,圧縮したければ上の gzip や bzip2 をこのまとめた結果に対して使えば良い.
また,こうしてできた result.tar というファイルを解凍したい場合は,
|
|
とすればよい.
実行例(2)
tar をフィルタとして使う面白い応用として,
複数のファイルをディレクトリの構造ごと「移動」させる例がある.
|
|
とすると,ディレクトリA の中身をそのままディレクトリ B へコピーできる(-C は change directory オプション).
さらにこのパイプの間に
rsh など
を挟めばネットワークを越えてディレクトリの構造をコピーできる.
(おまけ) awk の機能のホンの一部分 : 入力データを要素ごとに分解して取り扱う
ここではとりあえず,入力行の 項目を好きなように並べ直せる フィルタとして理解しておこう(awk は本来はプログラム可能な高機能フィルタである.あとで学ぶ).
つまり,
スペースや ,(カンマ) で区切られたデータが連なる入力に対して,
区切られたデータを抜き出せる.
データは,左から $1, $2, … という名前で扱える( $0 は特殊で、「全部」という意味になる).
実行例(1)
|
|
などとやってみれば一瞬で理解できる.
実行例(2)
データを 1行あたりの文字数の多い順に並べ直すのに、例えば awk を次のようにして使える.
|
|
データ処理の初歩: 指標を追加して、ソートした後、追加した指標を除去する
上はデータ処理の初歩かつ基本的な手法である 「指標を追加して、ソートした後、追加した指標を除去する」手法( DSU = Decorate Sort Undecorate ) の典型的な例である.大変便利に使えるパターンなので覚えておこう.
cut : 入力データを要素ごとに分解して取り扱う
区切られたデータが連なる入力に対して,区切られたデータを抜き出す フィルタで、 その意味では awk と似ているが,awk より融通が効かない. 続いているスペースは一つの空白とみなさず、空っぽの要素が間に挟まっているという機械的な処理をしてしまう.
実行例
|
|
とすると,「区切り文字 = スペース」として 2番目と11番目の項目を出力してくれるのだが, 上の awk の例と比較すると,「融通が効かない」という意味がわかるだろう.
実習
上に示した実例を実際に行い,何が起きているのかよく理解せよ.
正規表現 : 「こんな感じのパターンで…」を文字で示す方法
正規表現とは,文字列の集合を表すために考えられたルールの一つである.
人間が文字列処理を行なうとき,指定したい文字列を人間に伝えるのは簡単だが,
機械に対して正確に指定するのが難しい,ということは良くあることだ.
例えば,re で始まって,tion で終わる単語を文書中から探してくれ,という指示をコンピュータにどうしたら伝えられるだろうか?
こうした人間の要望を正確かつ厳密に表現する方法として,正規表現がある.
そのオンラインマニュアルを読むくなら、コマンドは以下の通り.
| 正規表現のオンラインマニュアル | 解説 |
|---|---|
man 7 regex |
Linux の場合 |
man re_format |
FreeBSD の場合 |
ある程度を、次の表で示しておこう.
| 基本 正規表現 | 拡張 正規表現 | 意味 |
|---|---|---|
| 通常文字 | 同左 | メタキャラクタでない文字. その文字自身を表す. |
| \ ^ \$ . [ ] * | \ ^ \$ . [ ] * + ? { } ( ) ¦ | メタキャラクタ. 意味はそれぞれ下記を見よ. |
| \m | 同左 | メタキャラクタ m の意味を打消し,通常文字として扱う(エスケープという). |
| ^ | 同左 | 行頭を表す. |
| $ | 同左 | 行末を表す. |
| . (ピリオド) | 同左 | 任意の一文字を表す. |
| [ ] | 同左 | [ ] で囲まれた文字列中のどれか一文字を表す. [ ] 中では特別に “-” のみがメタキャラクタとなり, 他のメタキャラクタは通常文字として扱われる. “-” を通常キャラクタとして扱うには, “—” (ハイフンを三つ繋げる) と書けばよい. |
| [ c1 - c2 ] | 同左 | 文字 c1 から c2 までの範囲の文字中のどれか一文字を表す. |
| [^ ] | 同左 | [^ ] で囲まれた文字列中に「含まれない」一文字を表す. |
| * | 同左 | 直前の正規表現の 0 回以上の繰り返しを表す. |
| (該当無し) | + | 直前の正規表現の 1 回以上の繰り返しを表す. |
| (該当無し) | ? | 直前の正規表現が 0 回か 1回現れることを表す. |
| \{ m \} | { m } | 直前の正規表現の m 回の繰り返しを表す. |
| \{ m, \} | { m, } | 直前の正規表現の m 回以上の繰り返しを表す. |
| \{m, n\} | {m, n} | 直前の正規表現の m 回以上 n 回以下の繰り返しを表す. |
| \( \) | ( ) | 囲まれた部分をグループ化する. |
| \N | 同左 | N 番目のグループ化された正規表現が合致した結果(N= 1,2,..9). |
| (該当無し) | ¦ | 直前と直後の正規表現の「どちらか」を表す |
なお,GNU ソフトウェアには以下のような拡張も追加されている.
| GNU拡張 | 意味 |
|---|---|
| \< | 単語の先頭を表す. |
| \> | 単語の末尾を表す. |
| \b | 単語の先頭か末尾を表す. |
| \B | 単語の(先頭か末尾)以外を表す. |
例 (1):
re.*tion
は「re で始まって,tion で終わる単語」に近い正規表現だ(そのものでない).
例 (2): 例えば,ある web page をファイル d.html として保存し、 このファイルから,html のタグ (< … > というやつ) を除去する作業を考える. この作業を emacs (正規表現が使える)でやるには次のようにすればよい.
emacs でファイルを読み込んでから、
|
|
とするとミニバッファに
|
|
と出て,入力を要求される. これは 「置換すべき対象」を正規表現で入力しろ, ということであるので、
|
|
と入力して Return を押す. するとミニバッファにさらに
|
|
と出て,入力を要求される. これは 「何に置換するのか」を正規表現で入力しろ, ということであるので,(今回は単に消去したいので)「空」を入力する. つまり,何も書かずに Return を押す.
実習
用いられる正規表現を理解しながら、上の例の作業を実際に行おう.
プログラマブル フィルタ
単機能フィルタでは少々荷が重い複雑なフィルタ処理を行なうには, そのままでは, シェルスクリプトを作成するか, 通常言語でプログラムを組むなどの行為が必要となる.
しかし,シェルスクリプトは制限が強すぎて柔軟な処理は難しいし, 通常言語でフィルタの内容をプログラムするのは無駄が多い.
そこで,フィルタプログラム自身が複雑なフィルタ処理をプログラムできれば, フィルタの便利な機能を生かしつつ,無駄無く複雑な処理が柔軟にできるというものだ. これが「プログラミング可能な」フィルタの存在意義である.
こうしたプログラミング可能なフィルタプログラムとしては, sed, awk, perl, ruby 等が有名である. 本講義では, sed についてまず簡単に解説する.
sed : 1行ずつ、正規表現に基づいて文字列を置換する
sed は 1 行ずつ 高速 かつ 正規表現の使える文字列置換ツール (フィルタ)である. フィルタとしては

というように用いる.
ここでいう「スクリプト」とは,sed の動作を指定するために我々がこれから作るプログラムのことである.
オプション -n についてはすぐあとで学ぶ.
動作としては、sed は入力を一行ずつ処理していく.
つまり,処理単位は「行」である.
そして,sed のスクリプトは基本的に,
|
|
という構造をしている.
なお、コマンドが一つしかない場合は { } は省略してもよい.
さらに、対象行の指定が不要である(つまり,全ての入力行を対象とする)場合は,
|
|
とコマンドだけを書き連ねてもよい.
そして,このスクリプトに従って、sed は基本的に
- 処理対象となる行には… 全てのコマンドを適用してから,
- 対象外の行には…なにもしないでそのままにして,
どちらにせよ結果を出力する.
ただし,起動時にオプション -n をつけた場合,「出力を命令(p フラグか p コマンド)されたとき以外は」出力しなくなる.
よって、
「処理された結果のみを見たい 場合は,-n オプションと,p フラグか p コマンドを使う」
と覚えておけば大丈夫だろう.
そして、処理対象となる行を指定する方法は,
| 対象行の指定文法 | 解説 |
|---|---|
| 行番号 | 10 と書いたら 10行目のこと. |
| /正規表現/ | その正規表現を「含む」行(複数ありうる). |
| $ | 最終行. |
の 3通り.
ただし,10, /win/ のように二つの指定を ,(カンマ) で繋げて書いた場合には,10行目から win を含む行まで という範囲指定になる.
そして、sed のスクリプト中に書き込むコマンドは以下の通り.
| コマンド | 意味 |
|---|---|
| s/元パターン/置換新パターン/フラグ | 元パターン(正規表現可) に合致する文字列を新パターンで置き換える. 置換新パターン中には,特別に & というメタキャラクタも使える. これは置換元パターンに合致した文字列そのもの,を表す. フラグは以下の通り. g … 行内の該当する文字列を「全て」置換. N … 行内の該当する文字列の「N 番目」を置換. p … 置換が行なわれたならば「表示」. |
| p | その行を必ず表示する. |
| d | その行を削除する. |
| q | sed そのものを終了する. |
実行例 (1)
|
|
とすると… 何が起こるか?
実行例 (2)
さらに,
|
|
とすると,上より分かりやすい.
実行例 (3)
たくさんあるファイルの名前を,一斉に機械的に変更したい.
例えば,*.text というファイルをすべて *.txt というファイル名に変更したいとする.
すると
|
|
とすると,「その変更操作のための下準備」ができる.
具体的には,例えば a.text, b.text, c.text, … というファイルがある
状態でこのコマンドを打つと,
|
|
という結果が得られる( ここでは念の為に ls の頭に \ をつけている).
さて,あとはこの「結果」をシェルスクリプトにしてもよいし,シェルそのものに渡しても良い. 例えば,
|
|
などとすると,一斉にファイル名を希望通りに変更できる.
実習 実習: 実習用にディレクトリを用意し,その中に実習用の ファイルを幾つか作って,上の例を試してみよう.
レポート
以下の課題について能う限り賢明な調査と考察を行い,
AppliedMath7-Report-04
という題名をつけて e-mail にて教官宛にレポートとして提出せよ. なお,レポートを e-mail の代わりに TeX で作成した書面にて提出してもよい.
Exercises: 課題
- Tsushima か Tsusima Tushima か Tusima か,という文字列を含む行をデータの中から探すにはどうしたらよいか述べよ.
- あるファイルの中身の行頭全てに
“ > “
という一文字を付け加えたい. どうすればよいか.
- あるファイル中で,年月日が全て
2019.05.18というような形式で記述されている. これを全て18/May/2019という形式に修正したいが,どうすればよいか(もちろん 1月は Jan. に,2月は Feb. に…と全部直すのである). - (余裕のある者向け) 普通の文章を,「関西弁風」に変換する方法を考えよ.
- (余裕のある者向け) データベースを用いる通常の方法をやめ,大規模な業務用システムをフィルタを使う単純な仕組みに直してしまっている例 システム統合にSOA? RDBMS? bashで十分! がある. 読んでみて,自分なりに考察せよ.