
#!/bin/awk -f … linux の場合
#!/usr/bin/awk -f … FreeBSD の場合
と書き込んであればよい。 これについては、 スクリプトファイルのコマンド化 を参照せよ。
awk は行単位でデータを読み込み、
1行の中身を適当な項目に分割して、
その項目ごとに複雑な処理を施すことを主な使い方とする、
プログラマブルなフィルタである。
unix ではデータはテキスト形式で保存されていることが多く、
そのデータは意味のあるひとかたまりが一行に固められて保存されている形式が多い。
であるから、そうしたデータを処理するには awk はまさにぴったりのフィルタである。
このため、unix でデータを処理する時には昔から awk が非常に良く使われてきた。
より柔軟なプログラムが可能である perl が登場してからは awk の登場の出番も少なくなったが、
ごく簡単な処理をするにはやはり awk を使う方が楽だったりするので、
フィルタのプログラミング入門という意味でも awk から学ぶのが良いだろう。
また、awk に慣れ親しんでおけば、perl を学ぶときもあまり違和感がないので、
そういう意味でもやはり awk を学んでおくのは無駄にならない。
awk はやはり他のフィルタと同じく、シェルから起動して用いる。 awk の使い方というか、起動方法には次の 3種類がある。
| awk の起動方法(呼び出し方) | 注釈 |
|---|---|
|
|
(注1)
ファイル中の先頭行に
#!/bin/awk -f … linux の場合
#!/usr/bin/awk -f … FreeBSD の場合
と書き込んであればよい。 これについては、 スクリプトファイルのコマンド化 を参照せよ。 |
ここでいう「スクリプト」が,awk の動作を指定するためにわれわれが用意するプログラムのことであるのは sed のときと同様である。
awk は入力を一行ずつ処理していく. つまり,処理単位は「行」である. これは sed 同様である。 そして, awk のスクリプトは基本的に,
処理対象となる行の指定 その1{
コマンド
コマンド
コマンド
コマンド
}
処理対象となる行の指定 その2{
コマンド
コマンド
コマンド
コマンド
}
…
という形を構造をしている.
この時、awk では、
処理対象となる行の指定を パターン,
それに対応する(複数の)コマンドをアクションと呼ぶ。
そして,awk の動作は、次のようになる。
まず、データとして行を一行読み込んでは、
最初のパターンと照合して、
と動作して、今度は次のパターンと照合して同様に動作して、以下これを繰り返し、
スクリプトの最後までいく。
そうしたら、新たに次の行をデータとして読む。
そして、またスクリプトの最初からチェックを始めて最後までいく。
そうしたら、新たに次の行をデータとして読む… を繰り返すというのが基本動作である.
awk のパターンは大きく分けて次の 6つがある。
| パターン | 説明 |
|---|---|
|
全部該当。
パターンとして何も書かないと、こうなる。 |
|
| BEGIN | データを読みこむ前に一回だけ該当する、 という特別なパターン。 |
| END | 全てのデータ読み込みとその処理が終わった後に一回だけ該当する、 という特別なパターン。 |
| /正規表現/ |
指定された正規表現を「含む」行が該当する。
|
| 論理式 |
指定した論理式が成り立てば、該当する。
|
| パターン1, パターン2 |
パターン1 が該当する行から、パターン2 が該当する行までの範囲の行、
が該当する。
|
まず、awk が読み込んだデータをどう扱うかを知っておこう。
awk がデータを一行ずつ読み込み、それを複数の項目に分解する、というのは既に述べた。
これは全く自動的に行われる。
ちなみに、次のような単語が使われるので示しておこう。
$n
で表せる。
$0
は特別に全てのフィールド、つまり、レコードを指す。
この「レコード」→「フィールド」の過程でどういうルールによって分解されるのかだが、
これは簡単で、「適当な区切りで分ける」のである。
この時の「適当な区切り」とは、何も指定しないと「空白(連続しても良い)」である。
区切りに使う文字を変更して指定するには、
-F
というオプションを使うと、フィールドの区切りを変えられる。
FS という変数を書き換えると、それが新たなフィールドの区切りになる。
実習
フィールドの区切りを変えてみよう。
まず、何もしないと、
ls -lg | awk '{print $9}'
ではファイル名が得られる.
ls -lg | awk '{print $1}'
とすると、パーミッション情報が得られる。
では、フィールドの区切りの文字を" A " という文字に変えてみよう。
それには、次の二つの方法がある。
ls -lg | awk -FA '{print $1}'
ls -lg | awk 'BEGIN{FS="A"} {print $1}'
各々やってみよ.
また,他の区切り文字も試してみよ.
配列とは,添字のついた変数で,添字を指定されると一つのデータがでてくるものである.
ベクトルのようなもの,と思えば良い.
awk には「連想配列」という,添字として文字列を使える配列が実装されている.
これは,例で示した方が分かりやすいだろう.
awk で配列を用いた例
たとえば,
#!/bin/awk -f
{ size[$9]=$5 }
END{ for (file in size) print file "'s size is " size[file] "." }
というスクリプトを"fsize"という名前で用意して,実行許可を与えてから
ls -lg | ./fsize
などとするとどうなるだろうか.
実習
上のスクリプトを実際に作成し,動作させてみよ. ただし,後述の スクリプトファイルのコマンド化 を理解してからの方がよいだろう.
さて,慣れてないと上のような抽象的な説明では良く分からないだろう. よって,簡単な例をやってみて実感するのがよいだろう. いくつか例を挙げてみるので,自分で体感してみよ.
ls -lg | awk '/hoge/{print $0}'
とすると,これは
ls -lg | grep hoge
と同じである.
ls -lg | awk ' length($9) > 10 {print $9} '
とすると,ファイル名が10文字以上のファイルのリストができる.
ls -lg | awk '$5 > 1000 { s = s + $5 } END { print s }'
とすると,ファイルの大きさが 1000バイト以上のファイルの大きさの合計がでる.
実習
ps -axu | awk '$2 > 7000 {print $2,$1,$NF}' | sort -n
はどんな動作をするか.
隣の人に解説してみよ.
unix には自分でコマンド(っぽいもの)を作る方法が豊富に用意されているのは、
シェルの alias などで体験済みのはずである。
その豊富な方法の一つとして、
あるプログラムに対するスクリプト自身を一つのコマンドのように見せることができる。
それがスクリプトのコマンド化である。
# これは、正しくは「インタプリタのスクリプトとインタプリタを結び付ける」ことを意味する。
具体的には、これはスクリプトの先頭行に、
#!プログラム名
と書き込めば良い。
こうすると、(実行許可を与えておけば)そのファイル自身が新たにコマンドとして認識され、
そのファイル名をコマンドとして実行すると、
プログラム名 スクリプトファイル名
と入力したことと同等となる。
少し例をみてみよう。
スクリプトファイルのコマンド化の例
#!/bin/grep dummy
dummy ha kore
are ha dore
aaa bbb ccc
123 dummy datoka
shikaraba
と書き込んだファイルを用意する。ファイル名を " script-test " としてある、としよう。
で、このスクリプトファイルに「実行許可」を与える。具体的には、
chmod u+x script-test
と一回やっておけばよい。
すると、このスクリプトファイル " script-test " は「新しくコマンドとして扱われる」。
実際に実行してみよう。
% script-test
#!/bin/grep dummy
dummy ha kore
123 dummy datoka
という結果が得られるのがわかる。
これはよく考えてみると、
% grep dummy script-test
としたことと同等である。
これがどういうことなのかというと、例えてみると次のような絵で表せる。
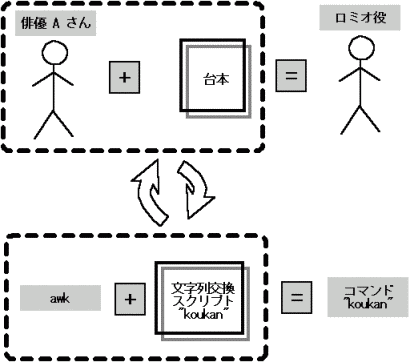
|
俳優が台本に従って演技するとき、それは俳優自身ではなくて演劇の役として行動していることになる。
つまり、台本にしたがっているならば役の名前で呼ばれる人になっている、
といえる。
これと感覚的には同じことである。 つまり、複雑で長いスクリプトを用意して、それに従ってコマンドが動作するとき、 人間からみればその動作の意味はスクリプトで決まるのである。 よって、スクリプトの名前でそれをコマンド化できれば、 人間にとって直感に非常にあうので、わかりやすく、かつ、便利になる、 というわけである。 |
他の例もみてみよう.
スクリプトファイルのコマンド化の他の例
fsize-sum というファイル名のスクリプトを作る.
内容は以下の通り.
#!/bin/awk -f
BEGIN {
sum = 0;
count = 0;
}
/^-.*$/ {
sum += $5;
++count;
}
END {
print "Total size of ",count " files in this directory is", sum, "byte.";
}
このスクリプトを実行できるようにしてから,
ls -lgA | ./fsize-num
などとすると,「そのディレクトリにあるファイルの総サイズ」が表示される.
実習
上の実行例を理解するとともに,実行してみよ.
以下に示された課題について
AppliedMath-Report-06
という題名をつけて e-mail にて教官宛にレポートとして提出せよ(教官のメールアドレスは授業中に口頭で伝える).
なお,レポートを e-mail の代わりに TeX で作成した書面にて提出してもよい.
課題内容
cal の出力を利用して良い.
最終更新日 …
$Date: 2006/05/06 17:50:21 $

