第 4 回 (2002.05.14) -- ネットワーク検索
ネットワーク検索
ネットワークを通じて情報を検索し, 大学での学習,研究や学生生活に役立てるための手段,知識について学ぶ.
現在, コンピューネタットワーク上に存在する情報は膨大であり,
その全体をとらえることは既に人類にとって不可能なこととなっているほどである.
その情報の膨大さに加え,コンピュータ自身の高速性とネットワークの透過性,
情報の入手費用の安価性, 電子的情報の再利用の容易さを鑑みると,
これらの情報を利用する能力はこれからの学生にとっては必須能力であると言えよう.
しかし逆に情報が「豊富すぎる」ことから,
ネットワーク上の情報を適切に利用するにはそれなりの知識と能力が必要とされる.
こうした傾向はこれからしばらくは強まると思われるため,
情報を検索して取捨選択する能力を大学生活の初期からなるべく鍛練するのがよい.
本講義ではネットワーク検索に必要な簡単な知識や手段を示すとともに,
最低限必要と思われる注意点についても言及する.
ネットワーク検索と他の資料検索との違い
ネットワーク検索と他の手段での資料検索との違いは以下のようなものである.
ちなみに他の手段とはコンピュータネットワークが無い時代から存在するもので,
成書からの検索,図書館での検索や人間同士の対話等である.
-
ネットワーク検索は基本的に非常に速い.
検索対象から検索自体,表示等にいたるまで全てコンピュータを通じて電子的に行なわれるため
その速度は基本的に速い.
-
ネットワーク検索は検索対象が基本的に非常に広い.
検索対象のデータが電子的に格納されていることから,
他のデータ格納方法よりも物理的にも費用的にも非常に少ないコストで格納できる.
このため,低コストで膨大なデータが検索対象として扱われるケースが多い.
-
ネットワーク検索は無料, もしくは非常に安価な場合が多い.
データの格納方法にしろ検索自身にしろ,
これまでよりも格段に低コストで実現できることから
ユーザに高いコスト負担を強いる事なくデータ検索システムを構築できる.
さらに, データ表示に web browser
が用いられることが大半であることから,
検索データ表示とともに商用データ(広告など)を表示するシステム等を通じて
コストを回収することもできるため,低負担で利用できる.
日本の行政機関の検索システムに良くみられるが,
むやみに高コスト負担をユーザに強いるシステムもある.
アメリカの行政機関や研究機関,
軍事機関までがそのデータの多くを web で無料で公開していることと比較すると
わが国の行政が10年以上遅れていることがよく理解できるだろう(^-^).
-
地理的条件を受けにくい.
既存のデータ検索では, 受益者がデータ検索のために物理的に移動する必要が多く,
そのコストは地理的条件を強く反映するものであった.
しかしネットワーク検索は, ネットワークさえ使える状況ならば地理的条件を無視しうる為,こうした制約を受けにくいことになる.
# 日本ではネットワークを利用するための地理的条件がまだ存在するので, この点は問題であるが.
-
ネットワーク検索では(明示的/暗黙の)検閲等を受けていない「真に自由な情報」
を得られる可能性が高い
web 情報を検索するようなシステムからは,
情報公開の方法の匿名性の高さや情報のあまりの膨大さから
あらゆる力から逃れた自由な情報が入手できる可能性が高い.
大げさに言えば, 幅広い層の人間が自由な情報を入手できるというのは人類史上始まって以来初めてのことであり,
情報伝達という意味において実は革命的な出来事であるとも言える.
ただし,真に自由な情報は時にデタラメな情報と区別がつきにくいため,
検索者は情報の真贋を見極める能力が必要とされる.
-
ネットワーク検索では得られる情報の質が一定でないことが多い.
既存のデータベースを電子的に検索できるようにした, というシステムの場合はそうでもないが,
web 情報を検索するようなシステムでは情報そのものの質が非常にばらついていることが多い.
これは検索者に情報の質を見極める能力が高い次元で要求されるということである.
これはデメリットでもあるが,
「検閲されていない自由な情報を入手できる」メリットと裏表の関係にあるものなので
あえて享受すべきものである.
-
ネットワーク検索は使いこなすのがやや難しい.
上に記したように,ネットワーク検索は得られる情報が膨大な上にその質が一定でない.
さらに検索自身も電子的に行なうために, 検索は理論的に行なわないといけない.
こうしたことから, ネットワーク検索は使いこなすのはそれなりに難しいことになる.
しかし, 得られるものは大きいのであるから, 躊躇無く利用し, 慣れていけばよい.
ネットワーク検索の仕組み
■ ネットワーク検索の仕組み概念図 ■
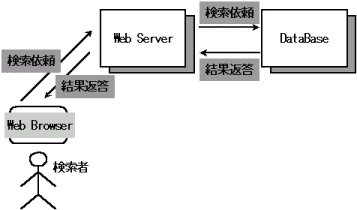
|
現在ではネットワークを介した検索はその多くが http (Hyper Text
Transfer Protocol) を用いて行なわれる.
よってユーザは使い慣れた Web Browser を通じて検索ができ,
その利便性を高めている.
また,http を用いることによって検索を行なうシステムとユーザとが分離され,
様々な利点を産み出している.
さらに, Web Server とデータベース Server も通常は分離され,
安定性や安全性,高速性等のメリットが得られるようになっている.
|
ネットワーク検索で必要な知識
ネットワーク上で情報を検索し,その情報にアクセスするために必要な最低限の知識について触れておこう.
- HyperText
-
テキスト同士が(その情報の意味から)接続できるようなシステムを内包したテキスト(^-^;).
… と書くと何が何だか分からないが(^-^).
要するに,テキスト本文と「注釈」を同等なテキストとして扱う仕組みを備えたテキストとでもいうか.
情報が連鎖的に接続されるため,このシステムを用いれば膨大な文献が一つに繋がることも夢ではない.
実際にこれが実現された一つの形として www がある.
- HTTP (HyperText Transfer Protocol)
-
HyperText を転送するための(汎用)プロトコル([RFC 2616]).
… と書くとこれも何が何だか分からないが(^-^).
要するに,HyperText の形で書かれている情報を「これくれ」「はいよ」とやり取りするための電子的な規格である.
web 上の情報は主としてこの規格に沿ってやりとりされる(もちろん他の通信規格もある).
HTTP の現在のバージョンは ver. 1.1 であるが,これを拡張しようとする規格がいくつかある.
とりあえず, coffee: URI スキームをもつ
HTCPCP
(HyperText コーヒーポット制御 Protocol :
[RFC2324]
,
[RFC2324 日本語訳])
などを見ておくのがよい(^-^).
- URI (Uniform Resource Identifier)
-
情報資源の名前/所在地を統一的に表示する方法.
要するに,情報のありか.
スキーム:所在地名称等
という形で(情報)資源の在処や名前を示す.
スキーム(アクセス手段とでもいうか)については, 良く知られているものの多くは
公式に登録されている.
例えば http スキーム(web への主流のアクセス方法)の場合は URI は次のようになる([RFC 2616]).
"http:" "//" host [":" port ] [ abs_path [ "?" query ]]
最初の http: は http という手段で接続することを示す.
次の // と host [:port] 部分は資源を所有するサーバを指定するもの.
# port とはネットワーク接続をする時にある沢山ある受け付け窓口のようなもの.
# 沢山あるので,使うときは本来「窓口番号」を指定しないといけないが,
http_URI では port が省略されたら 80 となると決められている.
abs_path 以降でその資源がサーバ内部のどこにあるかを表す.
- URL (Uniform Resource Locator)
-
URI のうち,
一般的なスキームである http, ftp, mailto などを用いたものを指す
「非公式な」名称.
URI と URL の関係の詳細については web 関連技術の標準化団体である w3c の記述である
http://www.w3.org/TR/2001/NOTE-uri-clarification-20010921/
,
http://www.w3.org/Addressing/#terms
を参照すること.
ネットワーク検索の分類
■ ネットワーク検索の分類 ■
|
検索対象
|
システム
|
概要
|
例
|
(電子化された)
既存データベース
|
これまでの資料検索システムをそのまま電子化したと見られるもの.
公的機関や商用サイト, マスコミ系サイトに多い.
検索の高速性や地理的条件の克服等のメリットは得られるが,
データベースがやや限定的であることやユーザ負担がやや高めになるというデメリット傾向がある.
その代わり情報の質が一定であり,内容が保証されていることも多いので,
確実な情報を入手するには良いだろう.
|
阪大蔵書検索(OPAC)
全国図書館目録検索
研究活動情報検索
学術情報等検索(有料)
Science Direct(文献検索:商用)
アメリカ数学会文献検索システム
新聞記事横断検索(有料)
など.
|
|
Web 情報
|
ロボット検索型
|
Web 情報をロボットエージェントとよばれるソフトウェアで web から広く無作為に検索収集し,
機械的にデータベース化して検索できるようにしたシステム.
データベースは機械的に構築されるため,検索は単語(を組み合わせた文字列)検索で行なうのが基本である.
情報の圧倒的な膨大さと検索の高速性,情報の幅の広さ,
事実上無料で使えること等がメリットである.
ユーザが無料で使えるビジネスサイトが主流.
現在のネットワーク検索システムの主流.
最近はディレクトリ型と融合しつつあるところも多い.
|
Google
Infoseek
goo
あたりが有名か.
他にも数多く存在する.
これらのサイトも最近はディレクトリ型の側面も強めつつある.
|
|
分類型(ディレクトリ型)
|
対象が Web 情報であることはロボット検索型と同じだが,
データベースを「意味で分類」してある点が異なる.
情報を分類するため, データベースの構築は主として人力で行なわれている.
情報が少なくなること, 新しい情報への追随性が低くなること,
情報の(暗黙の)検閲が行なわれることなどがデメリットとして挙げられるが,
ユーザにとって「分かりやすい」という大きなメリットがある.
ユーザが無料で使えるビジネスサイトが主流.
ネットワーク検索に慣れていない者はこのタイプから触れ始めるとよいだろう.
最近はロボット型と融合しつつあるところも多い.
|
Yahoo!
が有名かつ圧倒的な存在感を誇る.
他にも数多く存在する.
|
手続き
ネットワーク検索は,Netscape や Mozilla のような Web Browser を起動し,
上の分類の項で示したようなサイトへアクセスすればよい.
この際,検索はおおよそ次のような手順で行なうのがよい.
-
情報の検索を行なうサイト自体を検索を通じて決定する(省略可).
例えば, 自宅近くの郵便局が何時まで開いているかを調べたいとしよう.
こういうときは「郵便局のデータを検索できるサイト」があれば良いが,
そういうサイトの URL を知らないのが通常である.
そこでこういうサイトをまず探すのである.
この検索は,
探す情報が「かなりメジャー」→ ディレクトリ型 Web 情報検索サイト(Yahoo等)
そうでない → ロボット検索型 Web 情報検索サイト(google 等)
で行なうのがよいだろう.
-
情報の検索サイトの使い方を調べる.
検索サイトには使いこなせば非常に便利なオプションが存在することが多い.
オプションの使い方を調べるのは一見手間が増えるように思うかもしれないが,
最終的には検索の手間と時間を省くことになるので,
使う前に調べるのがよい.
例えば google では使い始める前に一度
google ヘルプ
に目を通し,かつ,
google 表示設定
を適切に変更しておくと後々の効率が全然違うはずである.
-
情報の検索を行なう.
最初はなるべく緩やかな条件から検索を始め, それから徐々に条件を絞っていくのが良い.
この際,先の「使い方を調べる」時に得た知識を用いて検索オプション(and や or 等)
を積極的に使っていくのがよい.
また,
探す情報にもよるが, 得られた結果が少なすぎるときは大事な情報源が漏れている可能性が高いため,
条件をより緩くするか,検索サイトを変更することを検討すべきである.
-
得られた情報をチェックする.
システムにもよるが,得られた情報が確実に正しいという保証はない.
よって, 得られた情報の正しさをある程度検証する必要がある.
よく使われる方法は,複数の情報源から情報を得てそれらを比較するというものである.
他にも情報を確認する方法があるならばそれを積極的に用いるのが望ましい.
実習
-
ログイン, Netscape(or Mozilla) の起動, このページの閲覧
-
阪大OPAC, Google, Yahoo! に各々アクセスしてみる.
-
(課題)
Linux に関する日本語の本が阪大のどこにどれくらいあるのか, 調べてみよ.
-
(課題)
数学者ガロア(Galois) についてその人生,業績,後世への影響等を調べよ.
-
(課題)
英語やその他の外国語の web を日本語に翻訳してくれる web サイトを調べよ.
-
(中級者向け)
余裕がある者は,
阪大教育用計算機システムの上でタイピング練習が出来る web, もしくはソフトウェアをいくつか探して,
自分に適したものを見つけ, 使用してみて紹介報告をせよ.
-
(上級者向け) 余裕があり,かつ,コンピュータに慣れているという者は,
kterm の中で使える Web Browser について調べ,試してみよ.
要するに, Netscape や Mozilla のようなグラフィカルな Web Browser
ではなく,
文字だけで構成される Web Browser である.
注意点
-
ネットワーク検索は, 情報が膨大であるために適切に絞り込みを行なわないといつまでたっても欲しい情報にたどり着けないことがある.
そのため,「情報の絞り込み」を行なう検索オプションを積極的に活用するべきである.
-
ネットワーク検索をしていると,
得ようとしている情報からそれて他の方向にいってしまうことが多々ある(^-^).
これは別に悪いことではないが, これであまりに時間を無駄にしないようにしたい.
-
ネットワーク上の情報は正確な情報源は英語であるケースがかなり多いのが現実である.
英語で書かれていることに躊躇して正確な情報源に触れない ということは避けるようにするべきである.
-
web 上にはたまにブラクラ(Browser Crasher)と呼ばれる悪質なものが存在する.
これは Browser や OS の動作を狂わせようという悪質なイタズラを仕込んだ web のことを指す.
こうした web を事前に見極める容易な方法は無いが,
タイトルや URL などでなんとなくそうした雰囲気を感じ取れることも多い.
ネットワーク検索をしているとこうした web にいきなり飛込んでしまう可能性が出てくるので,
アクセスする前にアクセスするべきかどうか簡単にでよいので検討する必要がある.
Web broser で Java や Javascript が動作しないように設定しておくのも有効である.