第 7 回 (2002.06.07) -- フィルタ
最終更新日 … $Date: 2002-06-07 01:50:22+09 $
フィルタプログラム
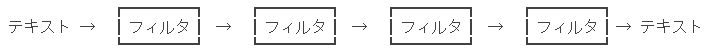
フィルタとは,入力したテキストを加工して出力するプログラム一般を指す.
unix には単純な機能を持つフィルタが多い.
これらをパイプでつなげることで,
複雑かつ大量のテキスト加工が,簡単にかつ一度にできるようになっている.
これは他の OS にはあまり見られない機能であり(VMS などにはそうした機能があるそうだが),
unix の大きな特徴である.
コンピュータ上の情報の多くはテキストという形で保存されているため,
複雑で大量テキスト加工が簡単なコマンドの組み合わせで実現できる unix
の情報処理能力は他の OS に比べて高いということになる.
それもあって,フィルタを使いこなすということは unix を最も unix らしく使うことといえよう.
まず,単純な機能,事実上一つの機能しか持たないフィルタ(プログラム)を紹介しよう.
ごく簡単な処理はこれらのフィルタを組み合わせることで大体できるはずだ.
いいかえると,これらのフィルタの組み合わせで出来ることを,
一生懸命手動で行なったり,それ専用のプログラムを新たに用意したりするのは愚かな行為である.
# この警告を理系世界では「新たに車輪を発明するな」などと表現する.
既に存在するものを新たに作る労力をかけるならば,その労力をより意味のある行為に当てよ,という意味である.
これら単機能なフィルタは長い間使い込まれたプログラムが多く,
その分鍛え抜かれているといえる.
実際,メモリや cpu への負担は小さく,かつ,頑健で素早く動作するものが多い.
安心してガンガン使おう.
-
cat
-
本来はファイルを連結して出力するプログラムである.
ファイル名を与えないか,
ファイル名として "-" とすると
標準入力を読込んで,そのまま出力するので,フィルタとして使える.
数学で言えば「恒等作用素」である(だから重要だ!).
フィルタの応用例としては,オプションを使用して
「出力に行番号を与える」,
「空白行をまとめる」
「目に見えない文字を見えるようにする」
などの他,
rsh
(後の授業で解説する)と組み合わせて
「ネットワークを経由してファイルをコピーする」
などがある.
(実行例)
ls -lg | cat -n | less
などとすると,出力結果に行番号がつくので,情報を把握しやすくなる…かもしれない.
(実行例)
ls -lg | rsh host 'cat > dummy.txt'
などとすると,出力結果をネットワークを越えたマシン
"host"
上の
"dummy.txt"
というファイルに書込むことができる.
# もちろん,
"host"
に書込む許可は持っていないと出来ない.
-
tee
-
cat
と似たような動作だが,
出力先が「標準出力」と「ファイル」の両方にコピーされる,という点が特徴である.
より詳しくは
前回の授業の tee 解説部分
を見よ.
(実行例)
ls -lg | cat -n | tee dummy.txt | less
などとすると,出力結果に行番号がつくのを見られると同時にファイル
"dummy.txt"
に結果が書込まれる.
-
grep (egrep, fgrep, zgrep)
-
与えた「パターン」を含む行を検索して表示するプログラムである.

として使う.
ファイル名を与えるとそのファイル中から検索する.
ファイル名を与えないか,
ファイル名として "-" とすると
標準入力を読込んで,その中から検索して出力するので,フィルタとして使える.
パターンは「基本正規表現」を使って表す(参照先 → 正規表現).
egrep は,パターンに「拡張正規表現」が使える(参照先 → 正規表現).
fgrep は,パターンを「単なる文字列」として扱う.
しかし,fgrep を使えば検索が早いかというと必ずしもそうではない(^-^).
(fgrep の f は fast ではなくて fixed- の頭文字である)
zgrep
圧縮したファイルを解凍してから,その中身を検索する.
ただし,zlib とよばれるライブラリを使ってコンパイルされている場合のみ.
(つまり,当てにするなということだ)
(実行例)
例えば,xemacs を使っている状態でその pid を知るには,
ps -axu | grep xemacs
とすれば(目で一生懸命探すという)苦労をせずに見ることができる.
この時,パイプの後ろの
grep xemacs
も検索されてしまうのがイヤだという場合は,
ps -axu | grep '[0-9] xemacs'
や
ps -axu | awk '{print $2,$11}' | grep xemacs
などとすればよいだろう.
なぜこれで良いのかは自分で考えよ.
ちなみに,こうした現象が起きるかどうか,つまり,
パイプの前後の評価が ps にどう反映されるかは,OS やシェルに依存するようだ.
上の実行例をうまく使えば,「狙ったプラグラムを kill する alias」
が簡単に書ける.
考えてみよ.
# sh 系シェルの場合は,シェルの「関数作成機能」を用いる必要がある.
よく分からないものは,とりあえず csh 系シェルで試してみるのがよいだろう.
ちなみに,コンピュータの出力から何かを目で探す行為は
"eye ball search"
と呼ばれ,あまり頭の良くないこととされるので覚えておくように(^-^).
正規表現はコンピュータを使い込む上での基本技術の一つであるので,
これを機会に是非とも覚えよ.
-
sort
-
与えられた行を「順番に」並べ直すプログラムである.
ファイル名を与えるとそのファイル中の行を並べ直して出力する.
ファイル名を与えないか,
ファイル名として "-" とすると
標準入力を読込んで,その中から検索して出力するので,フィルタとして使える.
sort
は比較的よく使うフィルタなので,そのオプションをマニュアルで調べ,覚えておくぐらいが良いだろう.
(実行例)
ps -axu | sort +10
とやればプロセスのリストを「プログラムの名前順に」,
ps -axu | sort -r +10
とやればプロセスのリストを「プログラムの名前の逆順に」
みることができる.
また,
ls -lg | sort -nr +4
とすれば,ファイルを「サイズの大きな順に」並べることができる.
HDD の容量が残り少なくて,無駄なファイルがないかな〜 と調べるときなどに有効だろう.
-
uniq
-
隣り合った行が同じ内容ならば,一行にまとめてしまうプログラムである.
これも使い方の基本はフィルタである(もう面倒なので,ファイル名を省
略したときどうのこうのは書かない).
データに対して
sort
フィルタを通してから
uniq
フィルタを通すと,全体の重複を除去できるので,こうして使うことも多い.
(実行例)
例えば,/usr/bin と /usr/local/bin にあるファイルを重複なしで全部見てみたい
という場合は,
(ls /usr/bin; ls /usr/local/bin) | sort | uniq
などとすればよい.
(実質的にはこのディレクトリにあるファイルは全てプログラムだ)
逆に重複しているファイルを見たければ,
(ls /usr/bin; ls /usr/local/bin) | sort | uniq -d
とするだけでよい.
同じ作業を windows などでやるにはどうするだろうか?
そう考えてみれば unix の効率の良さが良く分かるだろう.
-
tr
-
入力されたテキストの「文字」の置換を行なうフィルタプログラムである.

として使う.
あくまで「文字」単位で変換するのであって「文字列」ではないので注意.
古い文字集合の文字数と,新しい文字集合の文字数は同じにしておくのが基本.
オプションを変えれば,削除や連続する同じ文字を一文字にまとめることもできる.
(実行例)
ls -lg | tr a-z A-Z
とすると,
ls -lg の結果を,a → A, b → B, c → C … z → Z と変換して出力する.
つまり,全て大文字に置換する.
(実行例)
tr -cd [:print:]
とすると,印刷できない文字を全て入力から消去する.
(実行例)
tr -s '\n'
とすると,入力中の改行の繰り返しを一つにまとめる.
つまり,空行を消去する.
-
head
-
入力の最初の数行を出力する.
簡単すぎるので以下略(^-^).
-
tail
-
入力の最後の数行を出力する.
簡単すぎるので以下略(^-^).
-
fold
-
入力された行を決められた桁数で折り返して(行分割して)出力する.
デフォルトは 80桁.
(実行例)
例えば,
"dummy.txt"
というファイルの中身をメールで送ろうと考えたとする.
そのメールが 1行あたり 8文字表示される携帯電話でどう見えるかを荒っぽくシミュレートしてみるには,
cat dummy.txt | fold -w 8 | less
などとしてみればよい.
-
expand, unexpand
-
入力中のタブをスペースに変換して出力する(expand).
入力中のスペースをタブに変換して出力する(unexpand).
簡単すぎるので以下略(^-^).
-
pr
-
入力テキストをプリンタに出力するのにヨサゲな形式に変換して出力する.
(実行例)
ls -lg | pr | less
などとしてみると簡単にその意味が分かる.
-
wc
-
入力中に含まれる「データ全部の大きさ」「単語数」「行数」を出力する.
(実行例)
ls README* | wc -w
としてみると,ディレクトリに README という文字列で始まる名前を持つファイルがいくつあるかがわかる.
-
nkf
-
(日本語)入力テキストの漢字コードを変換するフィルタ.
漢字コードについての簡単な解説は
漢字コードについて
を参照せよ.
(実行例)
nkf -e … 入力テキストを euc に変換して出力する.
nkf -j … 入力テキストを jis に変換して出力する.
nkf -s … 入力テキストを shift-jis に変換して出力する.
なので,windows で作成したテキスト(dummy-win.txt という名前だとしよう)が
unix で読もうとすると文字化けして読めない時などは,
nkf -e < dummy-win.txt | less
とすれば読めたりする.
-
compress, uncompress, zcat
-
compress は,入力データを adaptive Lempel-Ziv 法を用いて圧縮して出力する.
uncompress は,入力データが圧縮されたデータならば元に戻して出力する.
(zcat は,圧縮されたファイルに変更を加えずに中身を閲覧するためのコマンド).
通常は compress によって圧縮されたファイルには
.Z
という拡張子を付加するのが慣例である.
(実行例)
ls -lg | compress > dummy.txt.Z
とすると,
ls -lg の結果が圧縮されて dummy.txt.Z という名前のファイルになる.
圧縮してない例
ls -lg > dummy.txt
もやってみたあと,
ls -lg dummy.txt*
などとしてファイルサイズがどれくらい小さくなっているか(圧縮されているか)
実際に見てみるとよい.
注) 通常は
ls -lg > dummy.txt
としてから,
compress dummy.txt
とするのが普通だ.
ここでは「フィルタ」としての使い方を強調するため,こうした書き方をしている.
-
gzip, gunzip, zcat(gzcat)
-
gzip は,入力データを Lempel-Ziv 77 法を用いて圧縮して出力する.
compress よりも効率がよい.
gunzip は,入力データが圧縮されたデータならば元に戻して出力する.
(zcat は,圧縮されたファイルに変更を加えずに中身を閲覧するためのコマンド).
通常は gzip によって圧縮されたファイルには
.gz や .z
という拡張子を付加するのが慣例である.
(実行例)
ls -lg | gzip > dummy.txt.gz
とすると,
ls -lg の結果が圧縮されて dummy.txt.gz という名前のファイルになる.
compress の時の例とも比較してみて,
ファイルサイズがどれくらい小さくなっているか(圧縮されているか)
実際に見てみるとよい.
かなり効率がよいことが良く分かるだろう.
注) 通常は
ls -lg > dummy.txt
としてから,
gzip dummy.txt
とするのが普通だ.
ここでは「フィルタ」としての使い方を強調するため,こうした書き方をしている.
-
tar
-
複数のファイルをまとめて一つのデータとして出力する.
ただし,後で元のファイルに分割しなおせる形式になっている.
# 通常の使い方はマニュアルを見よ.
さすがに tar をフィルタとして使うのは無理がある…
と思うかもしれないが,
複数のファイルをディレクトリの構造ごと「移動」させるのによく用いられる手段だ.
unix ,特にフィルタに慣れてないと何が何だか分からない例だろう.
(実行例)
tar cf - -C ディレクトリA . | tar xpf - -C ディレクトリB
とすると,ディレクトリA の中身をそのままディレクトリ B へコピーできる.
パイプの間に
rsh
を挟めばネットワークを越えてディレクトリの構造をコピーできる.
# これはかなり慣れないと何言ってるかわからないだろう.
だからわからなくてもあまり気にしなくてよい.
-
(おまけ) awk の機能のホンの一部分
-
awk は
スペースや ,(カンマ) で区切られたデータが連なる入力に対して,
区切られたデータを抜き出すフィルタとして使える.
これは非常に便利な使い方だ.
データは,左から $1, $2, ... という名前で扱える.
詳しくは実行例で見るのがよいだろう.
より細かいことは後の講義で解説する.
(実行例)
ps -axu | awk '{print $2, $11}'
などとやってみれば一瞬で理解できるだろう.
正規表現とは,文字列の集合を表すために考えられたルールの一つである.
人間が文字列処理を行なうとき,指定したい文字列を人間に伝えるのは簡単だが,
機械に対して正確に指定するのが難しい,ということは良くあることだ.
例えば,re で始まって,tion で終わる単語を文書中から探してくれ,
というのをコンピュータに伝えるにはどうしたらいいだろうか?
こうした人間の要望を正確かつ厳密に表現する方法として,正規表現は存在する.
unix では当たり前のように使われるルールであるので,使いこなせるようになっておくべし.
ちなみに,正規表現そのもののマニュアルは,
-
Linux の場合 …
man 7 regex
-
FreeBSD の場合 …
man re_format
とすることで読むことができる.
■ 正規表現の式とその意味 ■
|
基本正規表現
|
拡張正規表現
|
意味
|
|
|
|
通常文字
|
メタキャラクタでない文字.
その文字自身を表す.
メタキャラクタとは,
基本正規表現では \ ^ $ . [ ] * の7文字を,
拡張正規表現では \ ^ $ . [ ] * + ? { } ( ) | の14文字をいう.
|
|
\m
|
メタキャラクタ m の意味を打消し,通常文字として扱う(エスケープという).
|
|
^
|
行頭を表す.
|
|
$
|
行末を表す.
|
|
. (ピリオド)
|
任意の一文字を表す.
|
|
[ ]
|
[ ] で囲まれた文字列中のどれか一文字を表す.
[ ] 中では特別に "-" のみがメタキャラクタとなり,
他のメタキャラクタは通常文字として扱われる.
"-"
を通常キャラクタとして扱うには,
"---" (ハイフンを三つ繋げる)
と書けばよい.
|
|
[ c1 - c2 ]
|
文字 c1 から c2 までの範囲の文字中のどれか一文字を表す.
|
|
[^ ]
|
[^ ] で囲まれた文字列中に「含まれない」一文字を表す.
|
|
*
|
直前の正規表現の 0 回以上の繰り返しを表す.
|
|
|
+
|
直前の正規表現の 1 回以上の繰り返しを表す.
|
|
|
?
|
直前の正規表現が 0 回か 1回現れることを表す.
|
|
\{ m \}
|
{ m }
|
直前の正規表現の m 回の繰り返しを表す.
|
|
\{ m, \}
|
{ m, }
|
直前の正規表現の m 回以上の繰り返しを表す.
|
|
\{ m, n \}
|
{ m, n }
|
直前の正規表現の m 回以上 n 回以下の繰り返しを表す.
|
|
\( \)
|
( )
|
囲まれた部分をグループ化する.
|
|
\N
|
N 番目のグループ化された正規表現が合致した結果(N= 1,2,..9).
|
|
|
|
|
直前と直後の正規表現の「どちらか」を表す
|
|
|
|
|
\<
|
単語の先頭を表す.
GNU によって作成されたソフトで実装されている(GNU 拡張).
|
|
|
\>
|
単語の末尾を表す.
GNU によって作成されたソフトで実装されている(GNU 拡張).
|
|
|
\b
|
単語の先頭か末尾を表す.
GNU によって作成されたソフトで実装されている(GNU 拡張).
|
|
|
\B
|
単語の(先頭か末尾)以外を表す.
GNU によって作成されたソフトで実装されている(GNU 拡張).
|
プログラマブル フィルタ
単機能フィルタでは少々荷が重い複雑なフィルタ処理を行なうには,
そのままでは,
シェルスクリプトを作成するか,
通常言語でプログラムを組むなどの行為が必要となる.
しかし,シェルスクリプトは制限が強すぎて柔軟な処理は難しいし,
通常言語でフィルタの内容をプログラムするのは無駄が多い.
そこで,フィルタプログラム自身が複雑なフィルタ処理をプログラムできれば,
フィルタの便利な機能を生かしつつ,無駄無く複雑な処理が柔軟にできるというものだ.
これが「プログラミング可能な」フィルタの存在意義である.
こうしたプログラミング可能なフィルタプログラムとしては,
sed,
awk,
perl,
ruby
等が有名である.
awk, perl, ruby 等はプログラミング言語としてとらえないと全く理解できない恐れがあるので,
それらについての解説は後の講義で別に時間を設ける予定である.
そこで,本講義では,cui ユーザとして必須なツールである sed についてまず簡単に解説する.
先に注意しておくが,sed や awk でできることは perl などでも可能である.
しかし,sed や awk の方が,
シンプルで機能が少ない分だけ理解しやすくかつコンピュータへの負荷も小さい(つまり速い)
という利点があるので,
これらで簡単にできることはこれらで行なう,というのが正しい姿だろう.
sed は本来 Strem EDitor と呼ばれるエディタであり,実は非常に複雑なことが出来る.
ただし,出来るには出来るのだが,
おそろしく単純な機能だけを用いて複雑なことを行なうことになるので,
分かりにくい上に労力だけ浪費することがほとんどだろう.
よって,
よほどの物好きでない限り sed をエディタとして用いることはないと言ってよい.
# 頭の体操や罰ゲームにはいいかもしれない.
現在では sed は,
高速 かつ 正規表現の使える
「文字列置換ツール」
として使われるのが主流である,といってよい.
そこで,ここでもその路線に従った解説を行なう.
-
sed の使い方(文法)
-
sed はシェル(もしくはシェルスクリプト)から用いるのが基本であり,通常は

として用いる.
ただし,ここでいう「スクリプト」とは,sed
の動作を指定するために我々がこれから作るプログラムのことである.
指示通りに sed というプログラムが動くという意味で,
この指示を芝居の台本(スクリプト)になぞらえたらしい.
オプション
-n
は,後述するコマンド
p
と組み合わせて用いるものである.
-
sed の動作,スクリプトの基本
-
sed は入力を一行ずつ処理していく.
つまり,処理単位は「行」である.
そして,
sed のスクリプトは基本的に,
処理対象となる行の指定 {
コマンド
コマンド
コマンド
コマンド
}
という構造をしている.
コマンドが一つしかない場合は { } は不要だ.
さらに対象行の指定が不要である,つまり,全ての入力行を対象とする場合は,
コマンド
コマンド
コマンド
コマンド
とコマンドだけを書き連ねてもよい.
そして,sed の動作は
-
処理対象となる行には… 全てのコマンドを適用してから,
-
対象外の行には…なにもしないでそのままにして,
どちらにせよ出力する というのが基本動作である.
ただし,起動時に
オプション
-n
を使用した場合は,
-
処理対象となる行には… 全てのコマンドを適用し,
p
コマンドの時だけ出力する.
-
対象外の行には…なにもしないで出力もしない.
という動作になる.
具体的には,
p
コマンドを使用するときは混乱しないように
-n
オプションを使用するのだ,と覚えておけば大丈夫だろう.
-
sed スクリプトでの処理対象行の指定方法
-
処理対象となる行を指定する方法は,
-
行番号 … 10 と書いたら 10行目のこと.
-
/正規表現/ … その正規表現を「含む」行(複数ありうる).
-
$ … 最終行.
の 3通りである.
ただし,
10, /win/
のように二つの指定を ,(カンマ) で繋げて書いた場合には,
10行目から win を含む行まで という範囲指定になる.
-
sed スクリプトでのコマンド
-
■ sed のスクリプトコマンド ■
|
コマンド
|
意味
|
|
s/置換元パターン/置換新パターン/フラグ
|
置換元パターン(正規表現可) に合致する文字列を
置換新パターン で置き換える.
置換新パターン中には,特別に
&
というメタキャラクタも使える.
これは置換元パターンに合致した文字列そのもの,を表す.
|
フラグ
|
意味
|
|
g
|
行内の該当する文字列を「全て」置換.
|
|
N
|
行内の該当する文字列の「N 番目」を置換.
|
|
p
|
置換が行なわれたならば「表示」.
|
|
|
p
|
その行を表示する.
-n
オプションとの関係は記した通り.
|
|
d
|
その行を削除する.
|
|
q
|
sed そのものを終了する.
|
sed の簡単な実習
さて,慣れてないと上のような抽象的な説明では良く分からないだろう.
よって,簡単な例をやってみて実感するのがよいだろう.
いくつか例を挙げてみるので,自分で体感してみよ.
(実行例)
ls -lg | sed -e 's/emacs/ORAORAORAORA/g' | less
さあ,何が起こっているか分かるだろうか.
さらに,
ls -lg | sed -n -e 's/emacs/ORAORAORAORA/gp' | less
とすると,より分かりやすいだろう.
また,友人の名前とあだ名を使って次のようなスクリプト
s/友人A/いい奴/g
s/友人B/ちょっといい奴/g
s/友人C/金返せ/g
を書いたとしよう.
このスクリプトを
"dummy.sed"
という名前のファイルで保存したとしよう.
すると,例えば日記を
"nikki.txt"
という名前のファイルに書いていたとしたら,
cat nikki.txt | sed -f dummy.sed | less
とすれば,友人たちの名前が書き変わった日記を読むことができる(^-^).
もっと細かくやれば,標準語で書かれた文章を関西弁に直すことなどもできるだろう.
また,正規表現を使ったやや複雑な例としては,多くのファイルの名前を自動的に変更するというのもできる.
例えば,*.text というファイルをすべて *.txt というファイル名に変更したいとしよう.
すると,次のようにすればよいのである.
ls *.text | sed -n -e 's/\(.*\).text$/mv & \1.txt/gp'
例えば a.text, b.text というファイルがあるとすれば,
これを実行すると
mv a.text a.txt
mv b.text b.txt
という結果が得られる.
あとはこれをシェルスクリプトにしてもよいし,シェルそのものに渡しても良い.
つまり,
ls *.text | sed -n -e 's/\(.*\).text$/mv & \1.txt/gp' | tcsh
などとするもよし,ということだ.
これらの結果からも想像できるだろうが,
sed を使えば大量の文字列置換が自動的にかつ高速にできるようになるのである.
-
Takahashi か Takahasi という文字列を含む行をデータの中から探すにはどうしたらよいか.
-
あるファイルの中身の行頭全てに
" > "
という一文字を付け加えたい. どうすればよいか.
-
文中から,
Myoji Namae と並んでいる文字列を探し出して
Namae Myoji と並べ直すにはどうしたらよいか.
-
自分で便利だ,と思うフィルタの組み合わせを作り,解説せよ.